P2P 网络简介
文章目录
P2P 的去中心化思想正在被越来越多使用,了解一下这个技术背后有趣的原理。
1、P2P
peer-to-peer(P2P) 即点对点网络,无中心化服务器,用户端既是节点,也可以是提供服务器功能。
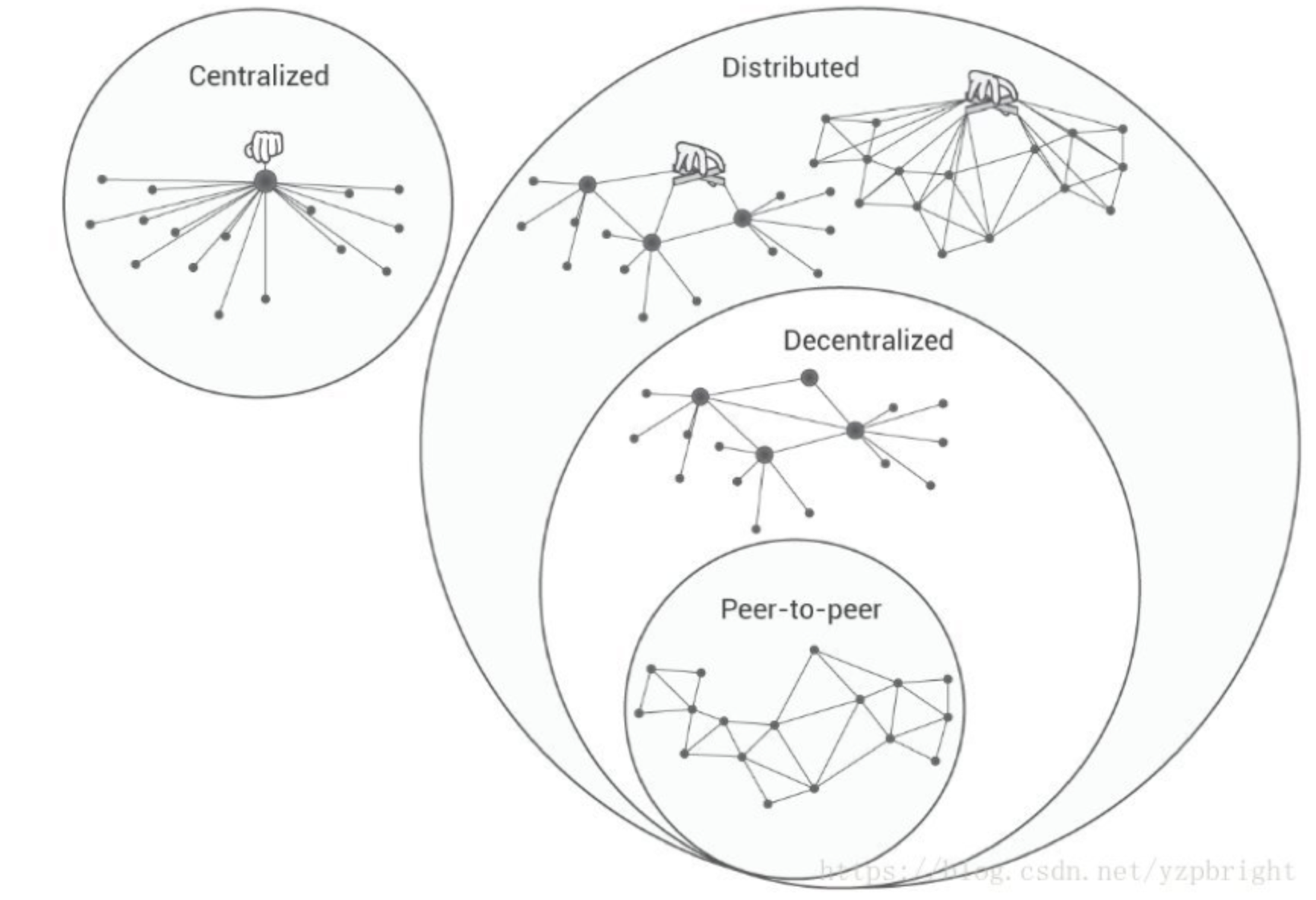
1.1、第一代 P2P
第一代 P2P 由服务器登记哪些用户在请求哪些资源,然后让请求同一资源的用户集中在一起互相分享。
但人多容易出现带宽不足,下载速度变慢;且一旦服务器出现问题,服务就没了。
1.2、第二代 P2P
第二代 P2P 由每台机器自己进行泛洪式查询,节点(客户端软件) 请求对等方的列表,初始时会在列表中加入预设默认的 IP 多播组。
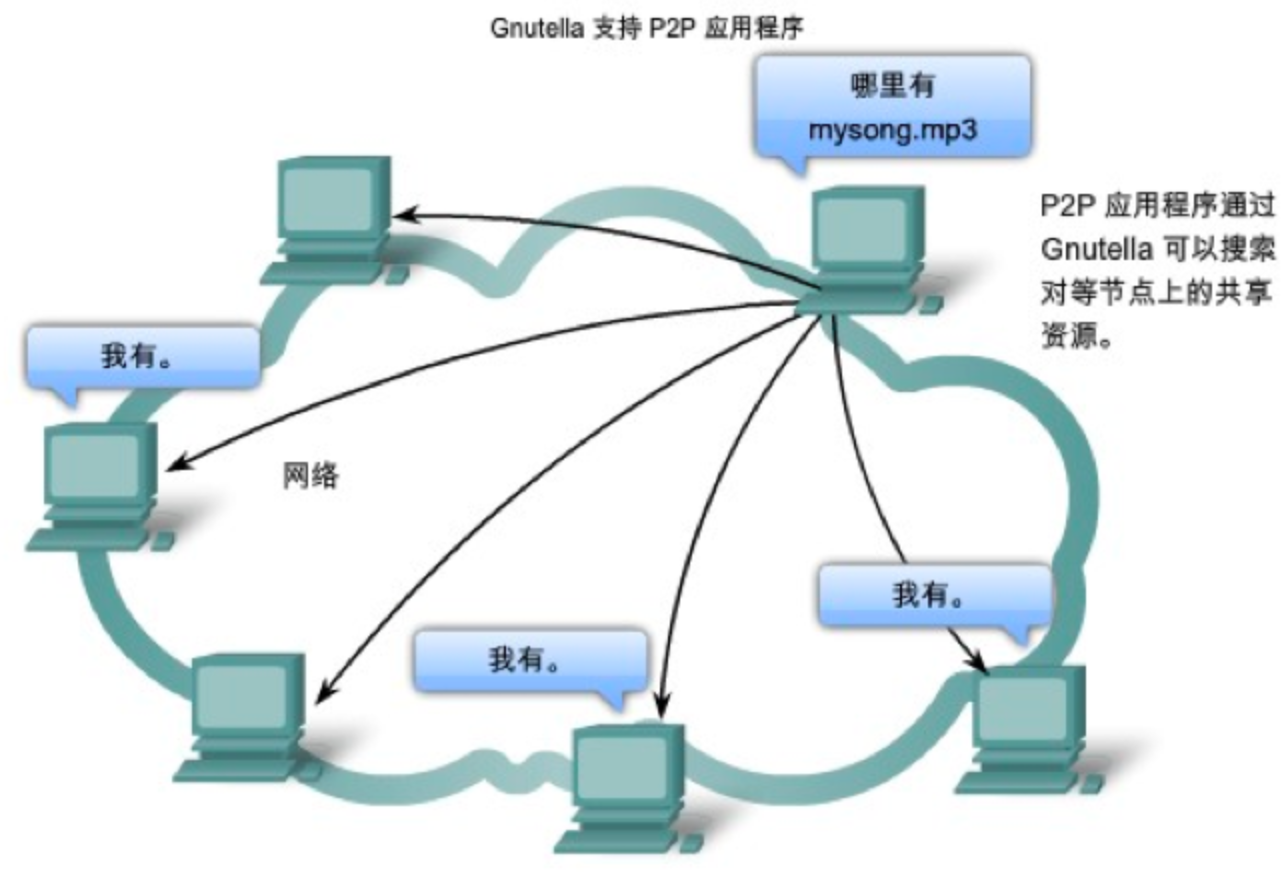
但这种方式会造成广播灾难,冗余消息多,带宽消耗浪费;且不可靠,节点经常连接或断开。
1.3、第三代 P2P
第三代 P2P 采用了 DHT(distributed hash table),加入这个网络的人负责存储资源信息和其他成员的联系方式,会使用哈希值来定位一个用户或一个资源。
2、具体实现
把文件分成很多个小块,让下载者互相连接,进行资源互换。参与者越多,交换的内容就越多,下载速度就越快。
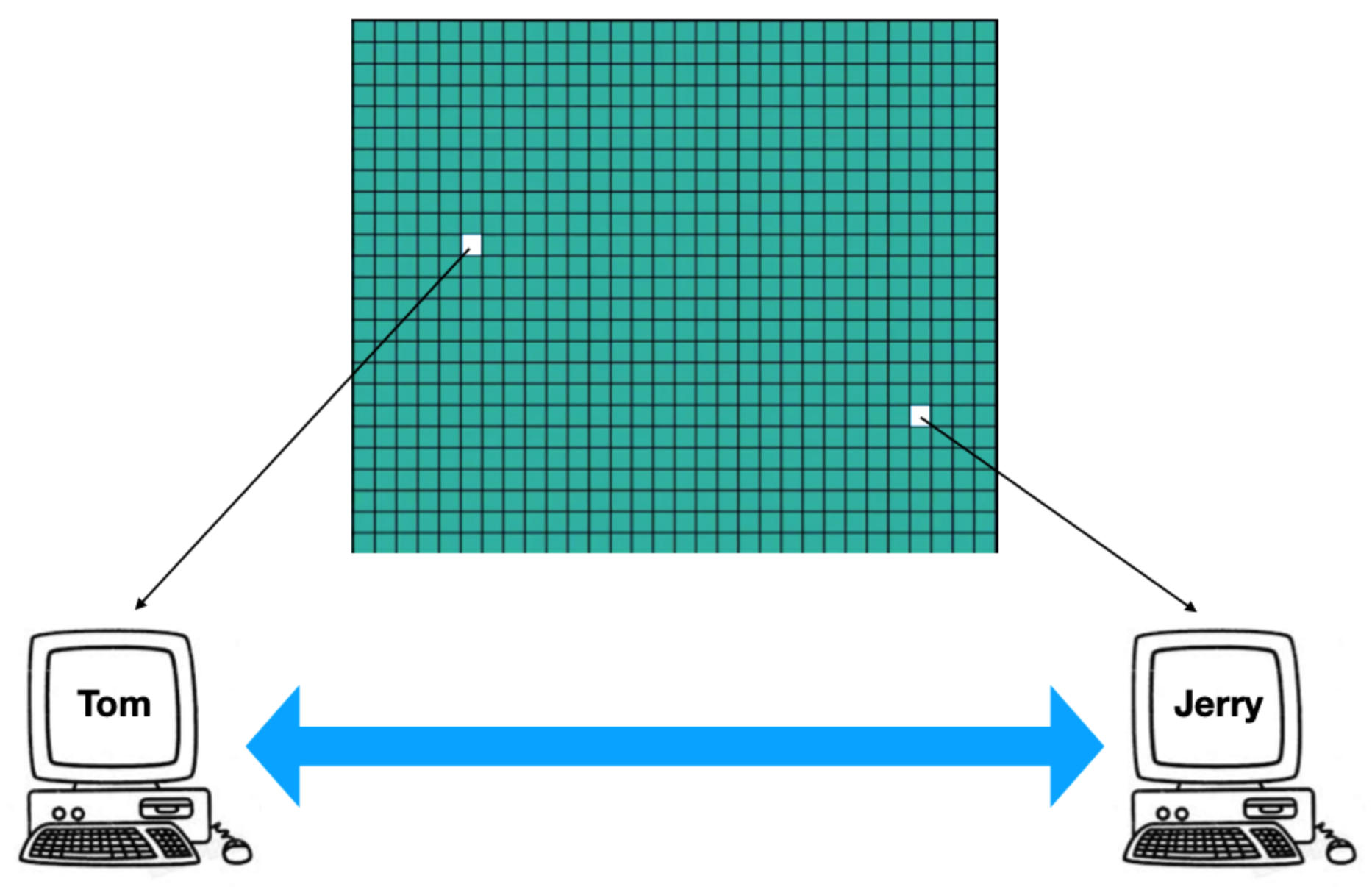
2.1、tracker
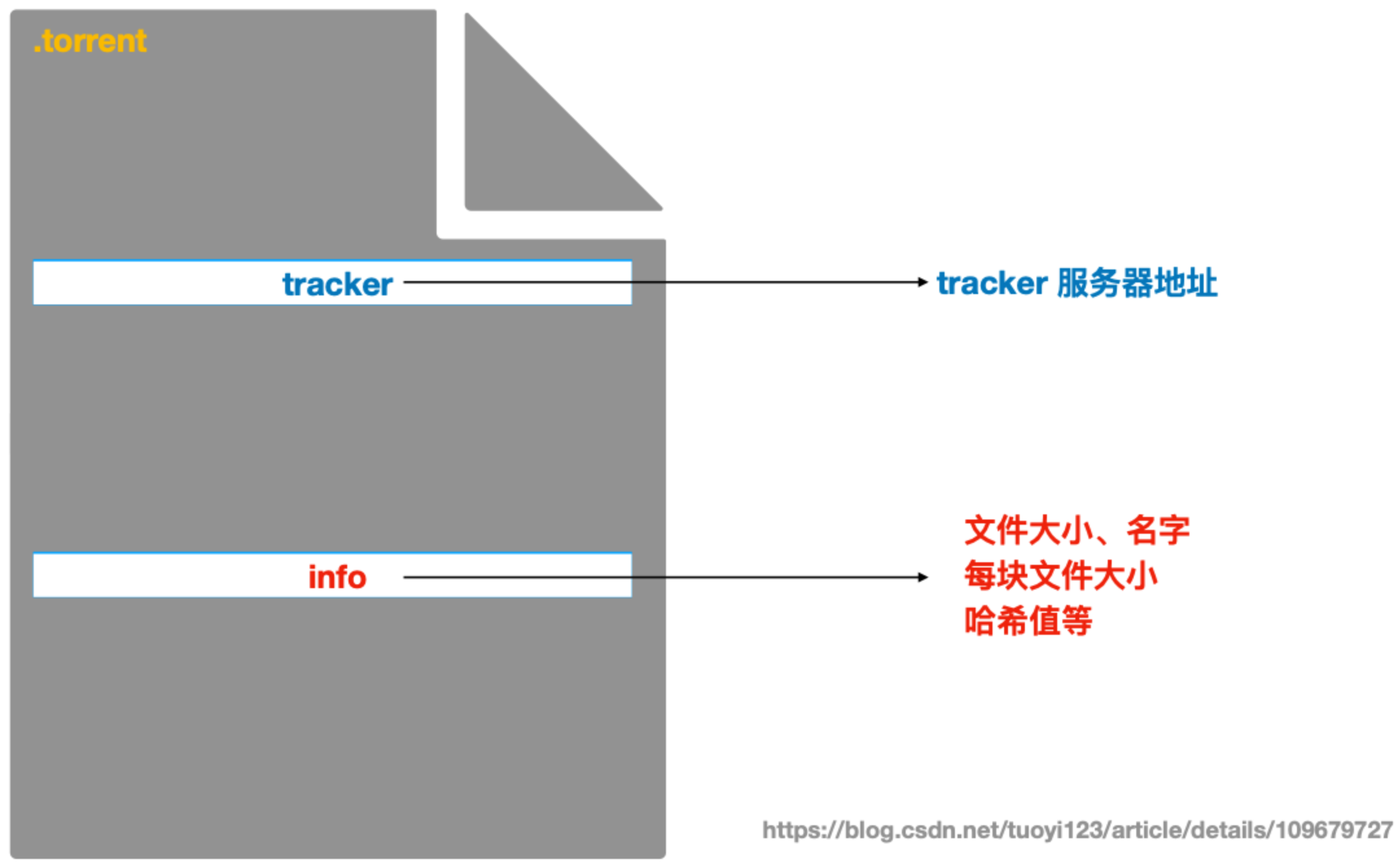
制造种子文件(.torrent) 需要包含有下载信息,主要有文件名、大小、分块后每块的大小和哈希值,以及 tracker 服务器的地址。
通过 tracker 的地址,我们才能找到其他下载者的联系信息,然后进行组队下载。
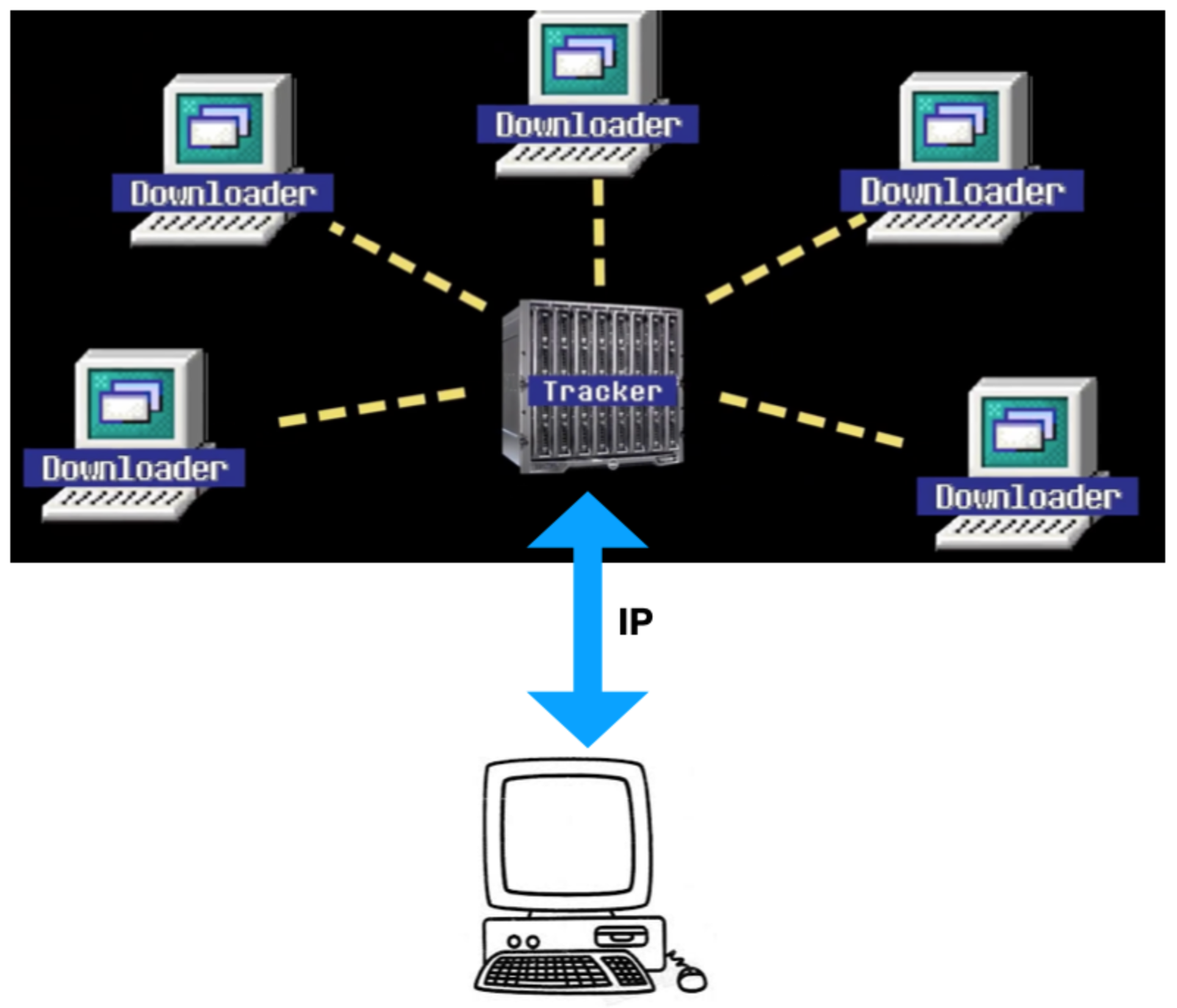
但如果无人在线,或者 tracker 服务器被封禁,就下载不动了。
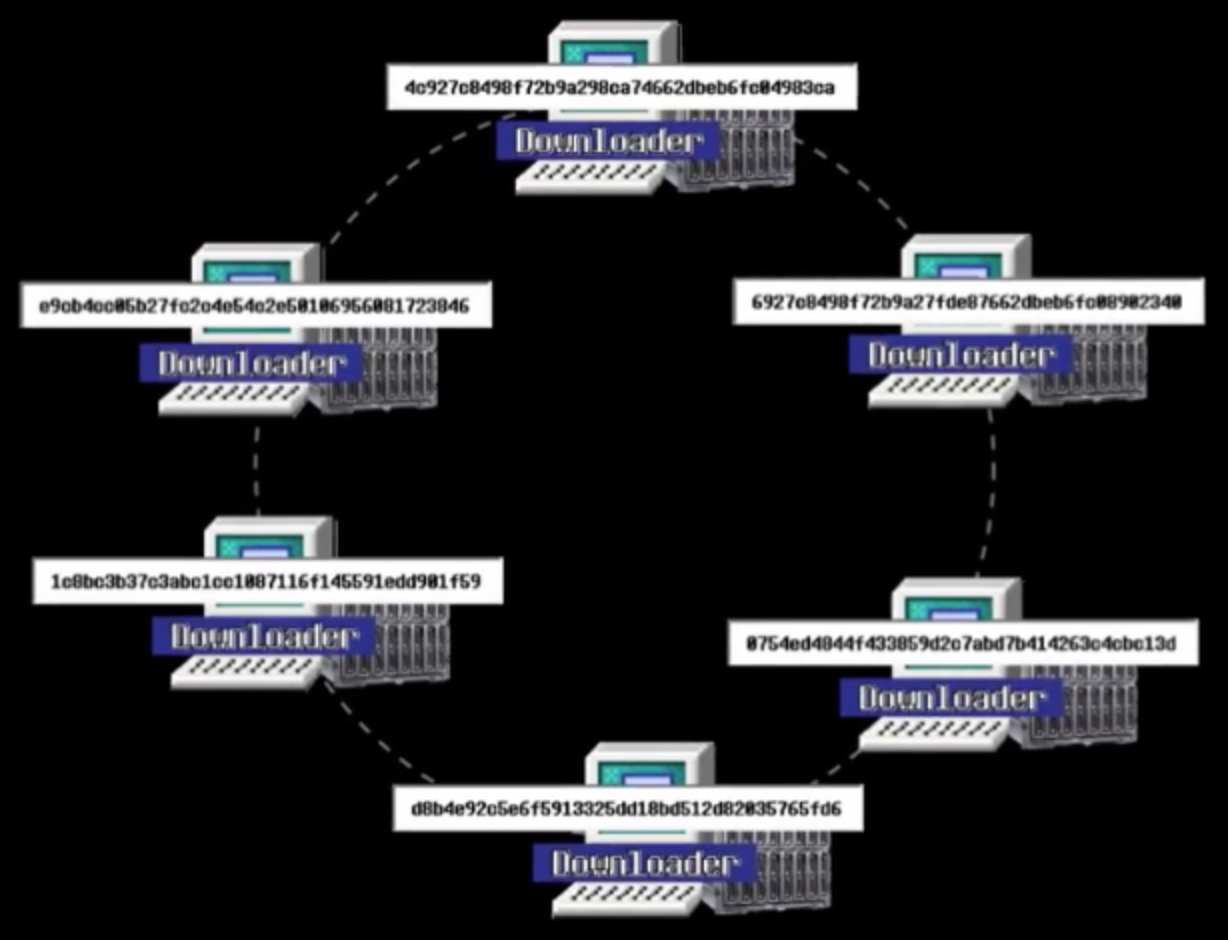
2.2、磁力链接
为了摆脱对 tracker 服务器的依赖,现在会用到磁力链接的方式。
无论文件多大,都能转成 16 进制 40 个字符的哈希值串,每个人会把自己持有的资源转成哈希值。
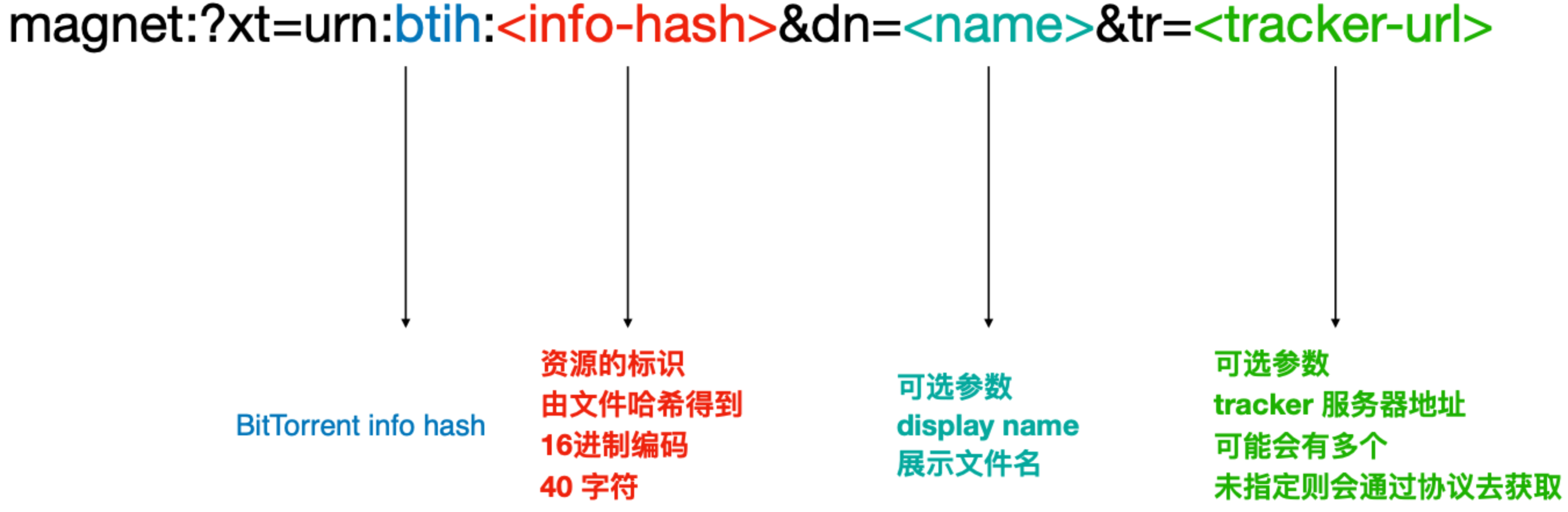
也就是说,把所有人都变成一个小型 tracker 服务器,每个人都拿着一份动态更新的地址和文件信息。
2.3、DHT (Kademlia)
由于直接广播寻找资源会造成广播灾难(冗余、带宽浪费),这里引入其中一种 DHT 实现的协议 —— Kademlia 协议 来解决这个问题。通过计算节点间的距离,抛弃了部分节点,从而防止广播。

这里的距离是指逻辑上的距离,使用异或来进行计算。异或满足以下几个几何要求:
- 异或自身为 0。A xor A = 0。
- 对称性:A xor B = B xor A。
- 三角不等式:A xor C <= (A xor B) + (B xor C)。
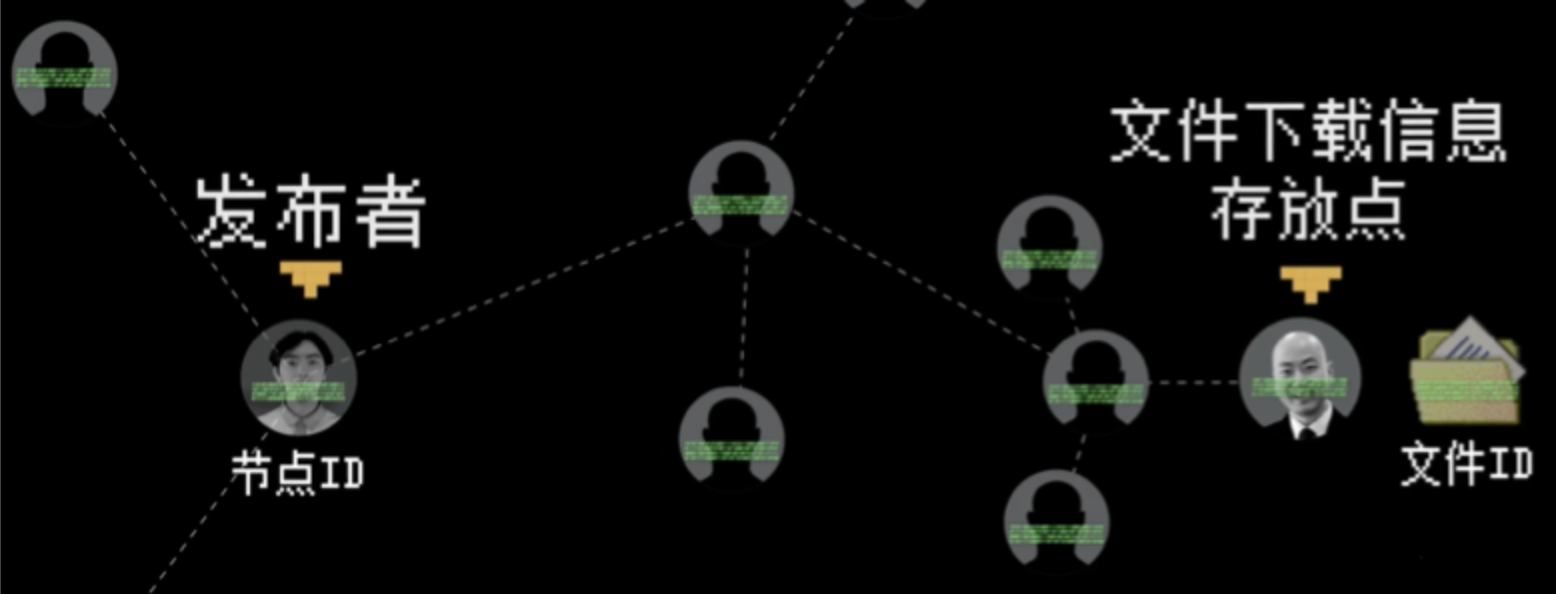
2.3.1、资源发布过程
资源发布者把资源转成文件 ID,计算自身知道的其他节点 ID 和文件 ID 的距离,为了避免广播,距离不是最短的会被抛弃。
每个距离最短的节点 ID 再去计算各自知道的,重复该该过程,就能得到一批距离文件 ID 最短的节点 ID,把文件的下载信息存放到这些节点当中。
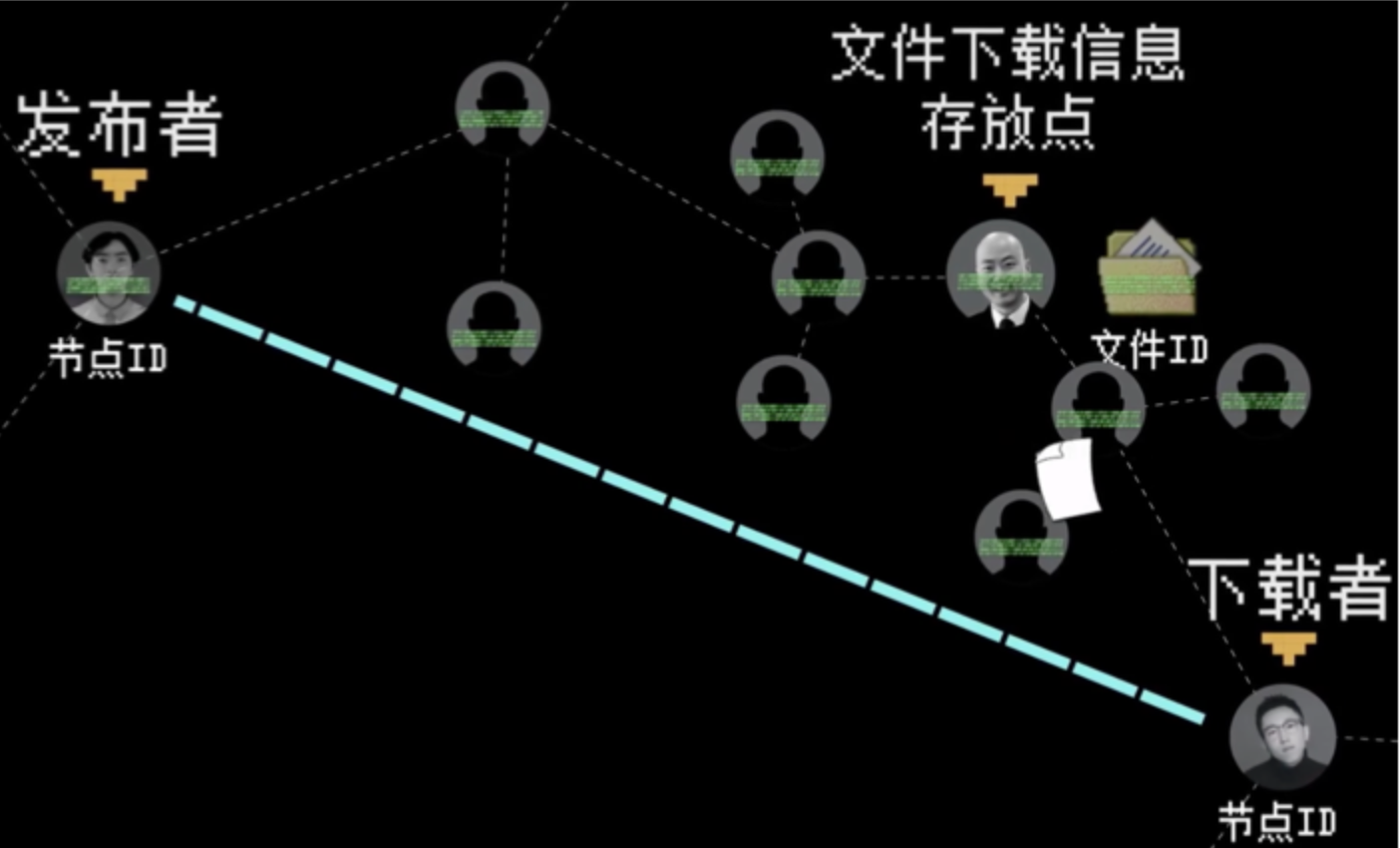
2.3.2、资源下载过程
下载者同样计算距离与文件 ID 最短的路径,找到有文件下载信息的节点,即可和发布者建立连接进行下载。
这时候发布者充当的是服务器的效果,如果有更多的下载者就利用资源互传达到更快。下载完成后会变成新的资源节点,更新文件下载信息存放点。
2.3.3、k-bucket
我们对比的是 160 位二进制的 ID,节点数量可能非常多,采用的是异或算法,那就是高位尽可能相同时距离最短,这是一颗庞大的二叉树,遍历复杂度非常高,而且如果使用 map<ID,value> 结构也不利于更新。
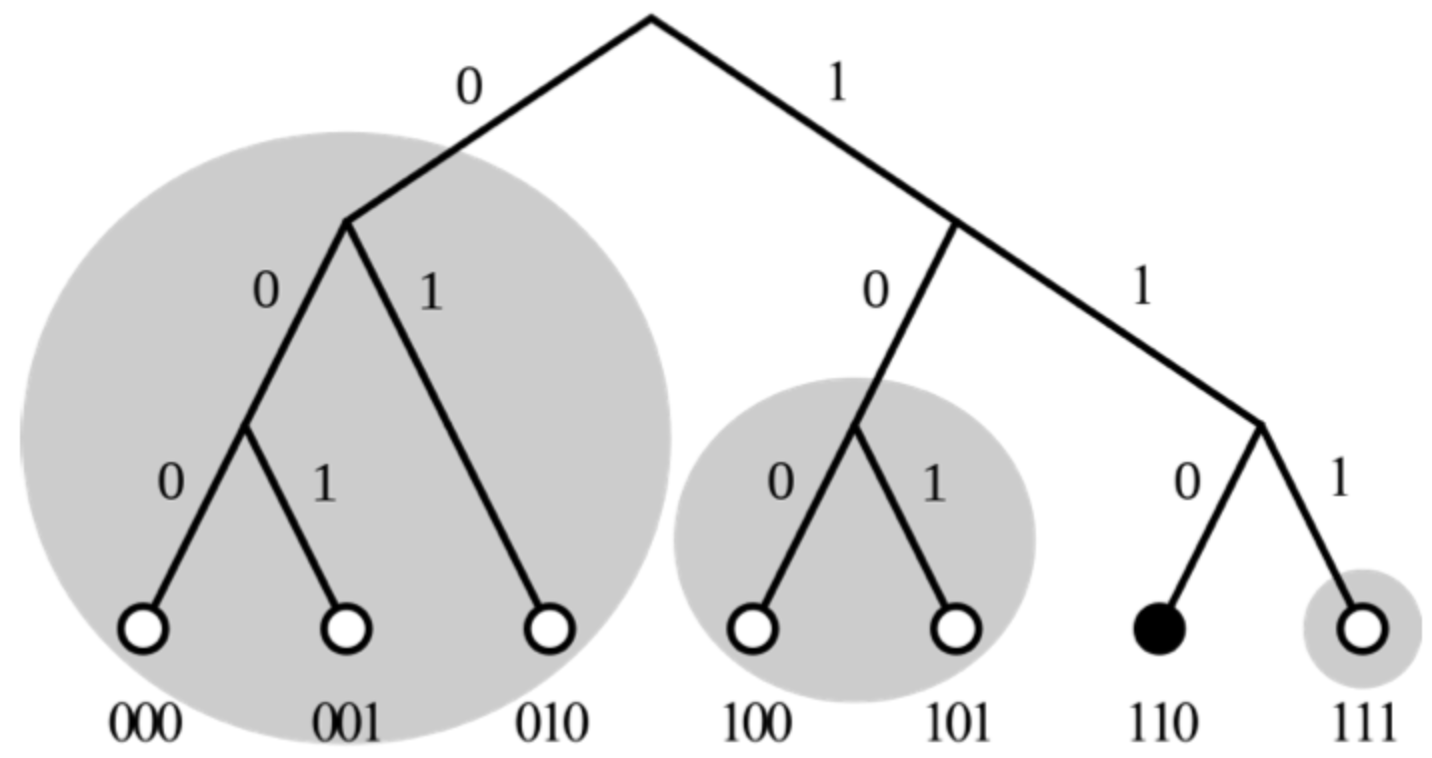
这里使用 k-bucket 的结构来进行存储加速查找算法,k 是每个 bucket 最多存放多少节点,在更新时:
- 如果未满,则直接加入。
- 如果满了,测试 ping,淘汰阶段。
比如这里的三叉树,尝试拆分二叉树,每次把自己不在的那部分子树进行划分,最后划分为 3 个 bucket。这里用 k = 2,即每个部分存放两个节点。
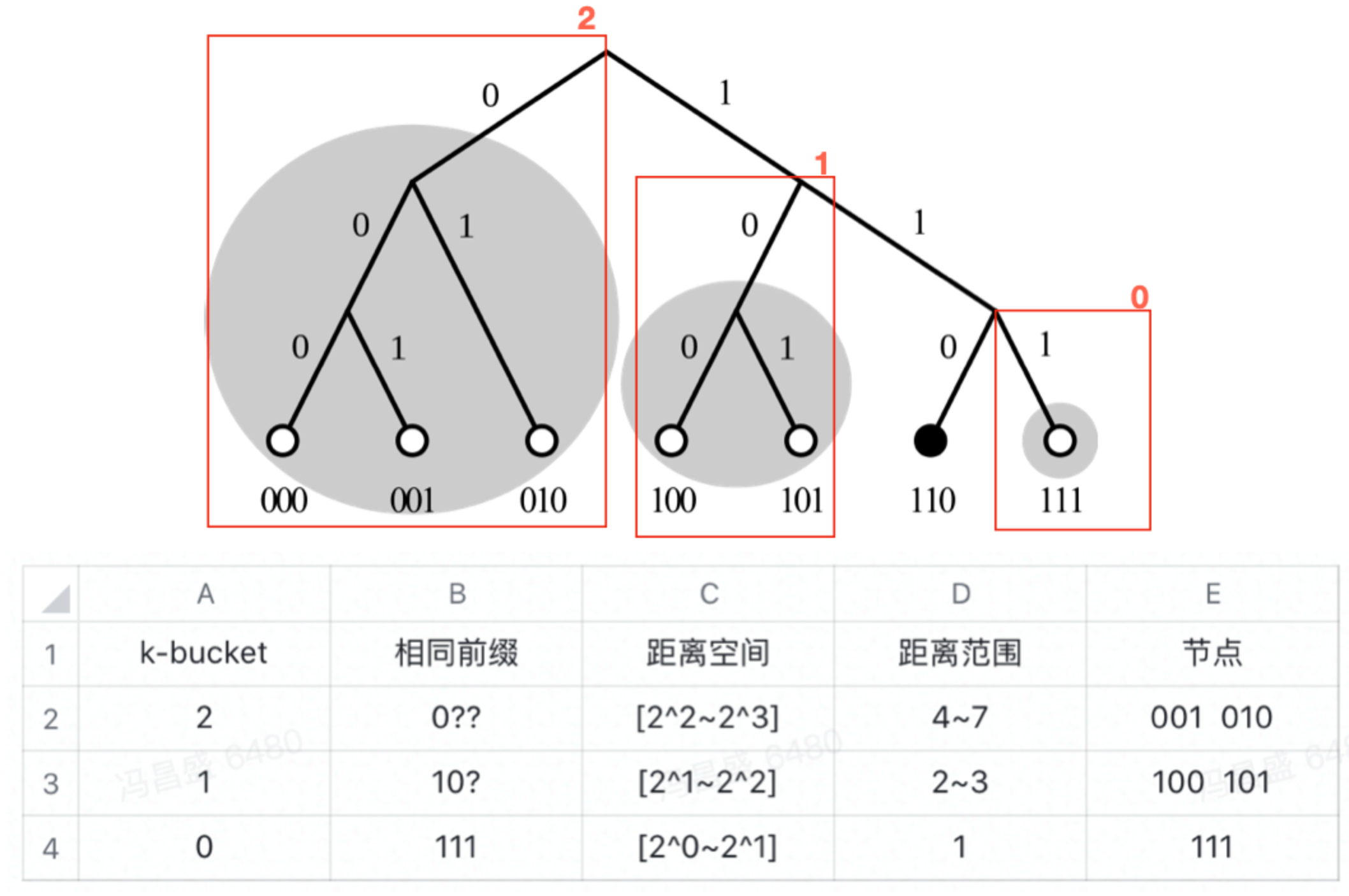
每个节点都有一份这个 DHT 的表,每次要找某个节点时,首先从表中找距离它最近的节点进行联系,然后那些节点再帮我们进行这种操作,最终找到对应节点的信息。
参考
文章作者 calssion
上次更新 2023-05-07