cola: 多人协作文档无冲突复制数据类型
文章目录
看到有个 Rust 实现的无冲突复制数据类型(CRDT) 包 cola,可用于实现实时的多人协作文档编辑。之前没有了解过这块,感觉挺有趣的,本文简单记录一下。
1、CRDT
在分布式计算中,CRDT (Conflict-free Replicated Data Type、无冲突复制数据类型),是一种可以跨多个站点同时复制和修改的数据结构的总称 (即实现方式不唯一,本文只介绍 cola 里的实现)。
CRDT 具有以下特征:
- 去中心化。可以独立、并发地更新任何副本,而无需与其他副本协调。
- 自动化。算法 (本身也是这种数据类型的一部分) 可以自动解决可能发生的任何不一致问题。
- 收敛。尽管副本在不同的时间点可能会有不同的状态,但可以保证它们最终会收敛到一致的状态。
CRDT 是一种乐观复制的算法,很好地解决了乐观复制并发操作时更新不一致的问题。
乐观复制(也称为延迟复制)是一种允许副本发散的复制策略。传统的悲观复制系统试图确保所有副本从一开始就相同,就好像数据从一开始就只存在一个副本。乐观复制消除了这种情况,有利于最终一致性。这意味着只有当系统静止一段时间时,副本才能保证收敛。这样一来,更新数据时无需等待所有副本同步,增加了并发度和并行度。权衡是不同的副本可能需要稍后进行显式协调,这可能会使协调变得困难或无法解决。—— 乐观复制 Optimistic Replication
1.1、CmRDT
CRDT 可以大致分为两类:state-based (基于状态的) 和 operation-based (基于操作的)。
本文要介绍的 cola 属于后者,基于操作的,也称之为 CmRDT (Commutative Replicated Data Type、可交换复制数据类型)。
CmRDT 基本思想是设计一种核心的数据结构,并在其上通过使用的操作命令来进行交换/交流,使得它们在每一个副本节点的操作顺序不重要 (即只关注操作本身,而非顺序)。交换性使得数据结构的最终状态,仅仅是由其初始状态和应用于它的操作集合来生成。
2、多人协作文档问题
当多个节点同时在编辑同一个文档时,都在修改自己的副本,插入或删除文本,然后还需要看到应用于其他副本的更改,节点之间通过网络互相传送操作命令,要保证一致性,是非常困难的。
原文有动图会更加清晰,本文只做截图讲解,可能也会适当去掉一些细节。
2.1、记录编辑的偏移量?
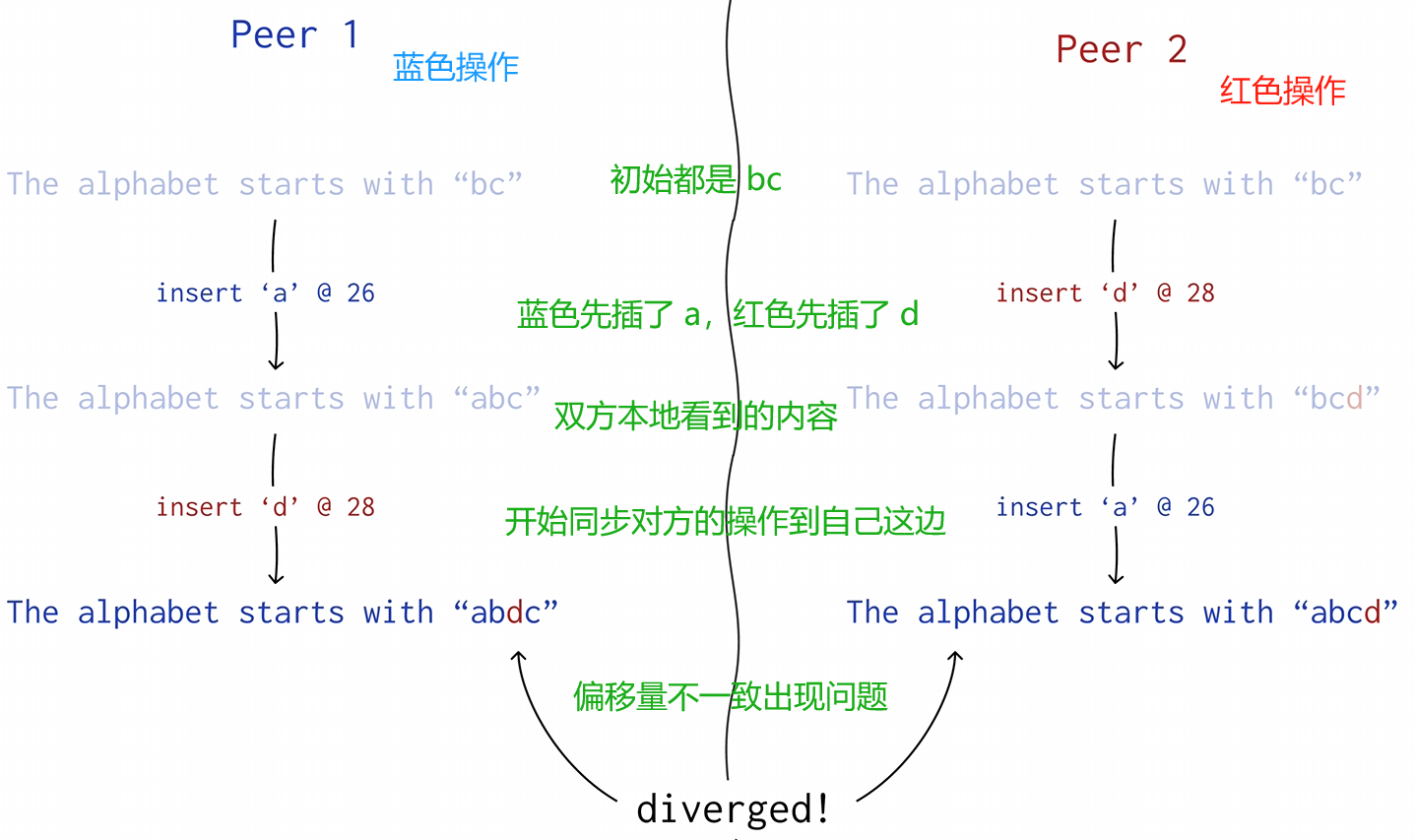
我们可以选择记录下编辑副本时的偏移量,比如插入 insert "abc" at offset 8 和删除 delete between offset 10 and offset 13。
但这种方式是有问题的,因为偏移量只是取决于编辑时文档的状态,双方的文档的偏移量不一定一致。
2.2、引用在文档中的上下文位置信息?
我们不能只交换偏移量,而忽略了它们所处的上下文。我们可以使用字符来引用其在文档中的位置,比如插入 insert "abc" after the 'd' 和 删除 delete between the 'f' and the 'o'。
这样就带上了上下文信息了,但是如果文档中存在多个 ’d' 的话,要进行删除操作的话,要怎样才能知道删除哪个 ’d'。我们可以加上时间戳 (按顺序递增的数字即可),分配给每个操作的字符。
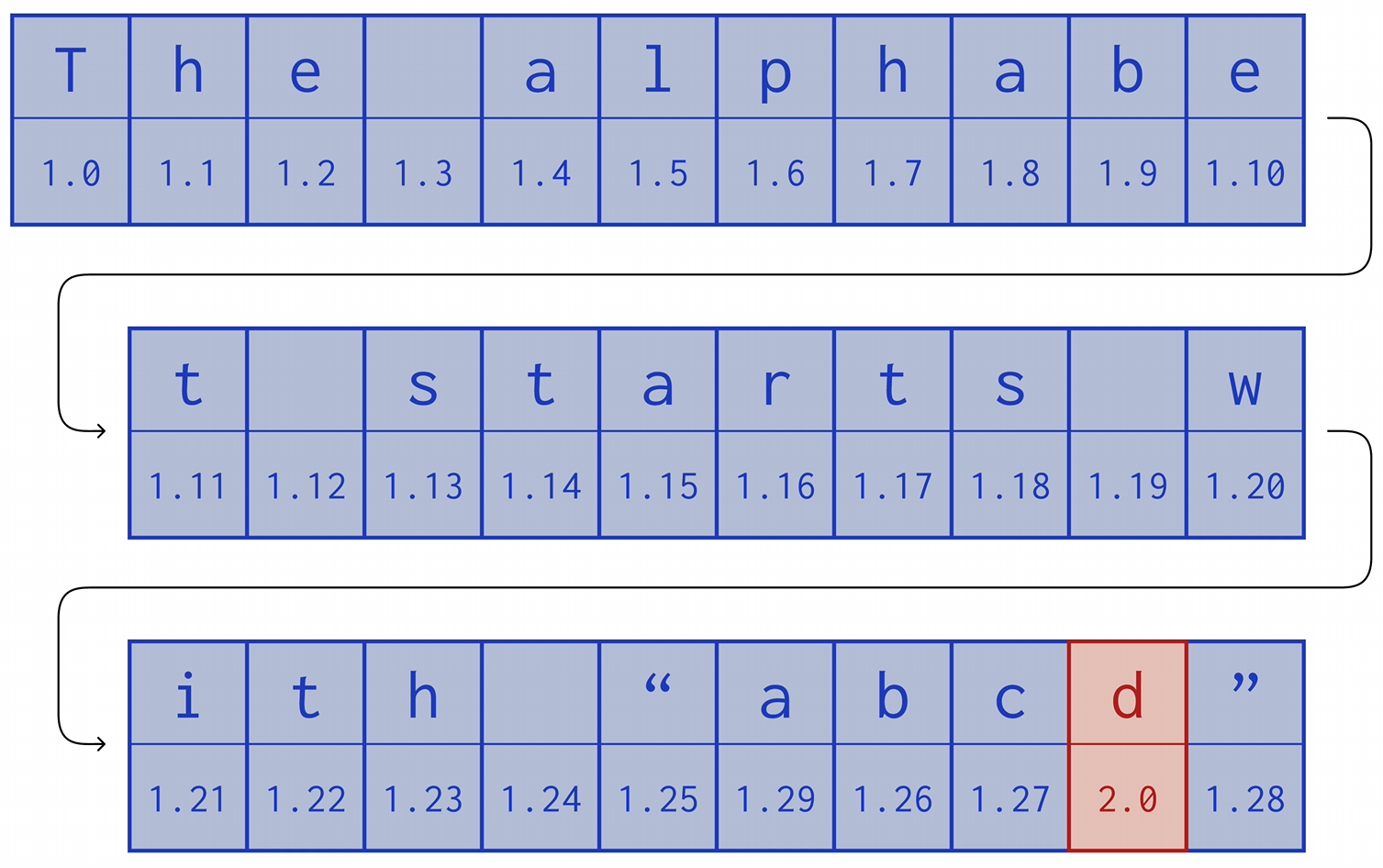
由于每个节点只能插入第 n 个字符一次,因此这个数字是可以作为该文档中位置的稳定标识符。但同一个文档,可能会有许多的第 n 个字符,因为每个节点都可以写自己的第 n 个字符,为了区分,还要为每个节点加上唯一标识符 ReplicaId,并使用 ReplicaId.n 来标识该节点下的第 n 个字符。
这个 n 所标识的数字也被称为 temporal offset (时间偏移量),而 ReplicaId.n 被称为 Anchor (锚)。Anchor 非常重要,因为它们支持可以并发地进行插入和删除。插入会由单个 Anchor 标识,表示在哪里插入。而删除会有两个 Anchor 标识,一个表示删除区域的开始位置,另一个表示结束位置。
2.3、Lamport timestamp
我们还需要一种方法,来确定当前的插入操作,是否在另一个已经做了插入的环境中进行的,也就是如何区分其顺序性。
这里用到 Lamport timestamp 时间戳方式,是一种简单的逻辑时钟算法,用于确定分布式计算机系统中事件的顺序,以最小的开销提供事件的排序。
算法比较简单,就是每当一个节点插入一些文本时,它的时钟就会加一。而当它接收到远程的插入事件时,它就会把时钟设置为 max(current, remote_timestamp) + 1。
这就保证了操作的顺序性。
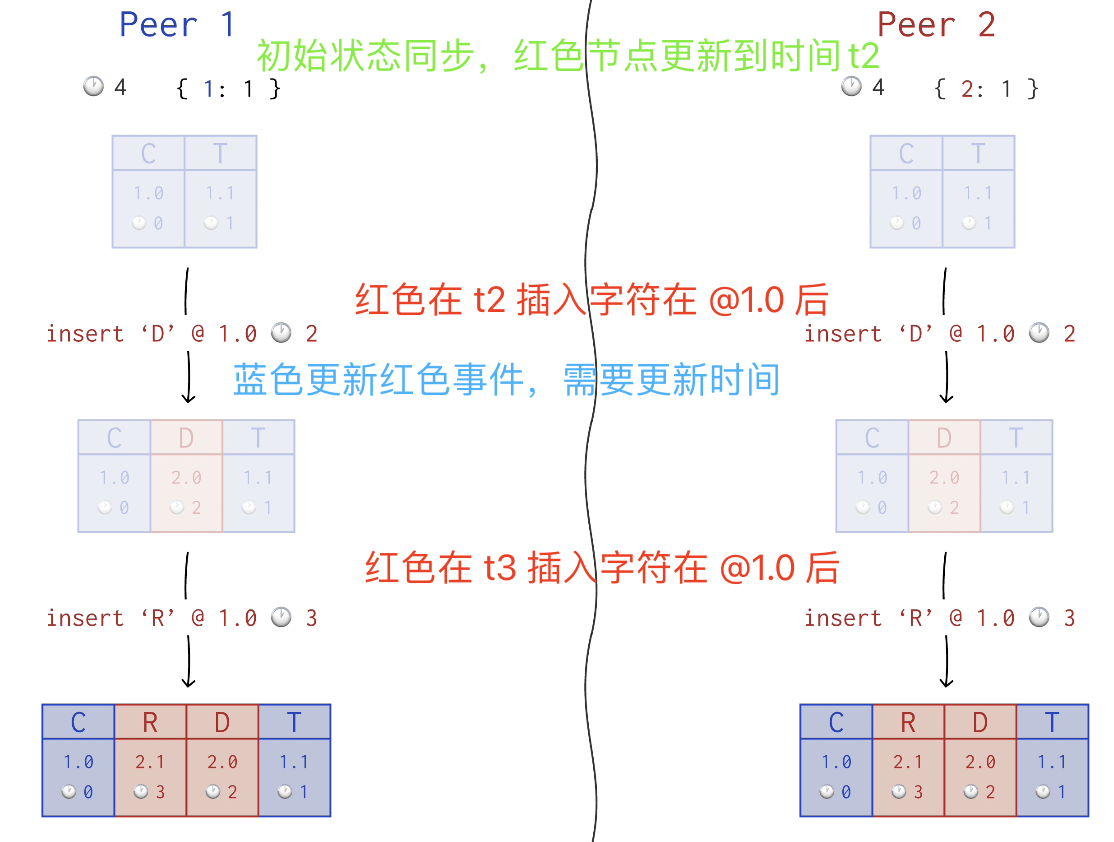
如果不同节点的两个插入操作具有相同的 Anchor(位置) 和时间戳,这时候怎么办?这时候就需要用到给节点所分配的 ReplicaId 了,具有相同 Lamport 时间戳的插入操作按其 ReplicaId 升序排序,最终还是可以保证每个节点得到一样的结果。
2.4、删除
不同于新增,删除更容易导致出现分歧。因为其他节点可能在编辑被删除的区域,而且多个删除如何才能保证最终一致性呢?
这里用到了 tombstones,即先标记这些会被删除的字符为已删除状态,不真正地移除,把真正的移除时机延后,虽然这会导致明显地增加了数据结构整体所占用的内存大小。
另外在删除事件中,保存一个映射关系,key 是 ReplicaId,而 value 是删除的节点对这些被删除内容的最后一个字符的时间戳。这被称之为 version vector,可以实现不同节点内容的对比,如果对比出现问题,则其他节点会等待集成删除,来保证版本的顺序性和正确性。
3、cola
上面已经讲完整体实现,这里简单讲下 cola 的实现。按原文的说法,cola 可能是该作者已知最快的文本 CRDT 算法了。
cola 把数据保存到一个链表结构当中,其中包括时间偏移量和 Lamport 时间戳,这里的图看起来是每个字符分配了一个块,实际上 cola 并不关心实际的数据,它只是提供块来进行存储,存储的内容由自己定义。
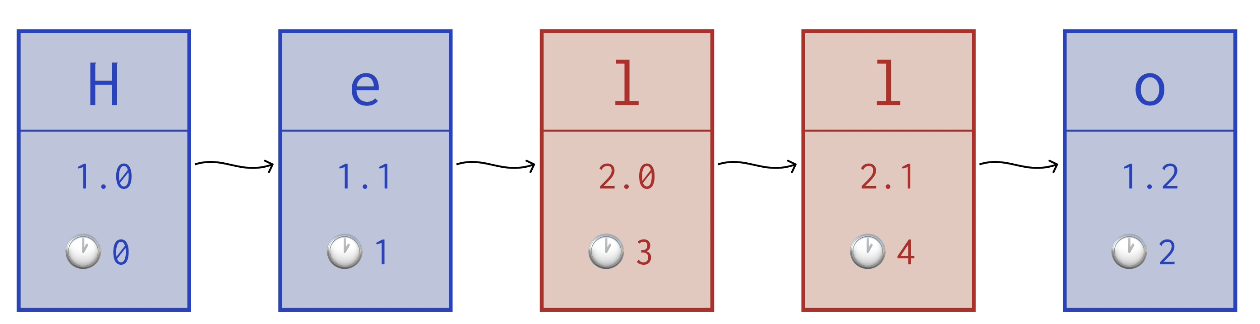
cola 做的一个重大优化是减少表示文档所需的块数量。如果我们有一堆与插入的每个字符相关联的元数据,那么我们就不可能获得高性能的实现。所以这里每当有一系列块的字符时间戳依次增加时,我们就可以将它们按游程长度编码 (run-length encode,是无损数据压缩的一种形式) 为单个块。
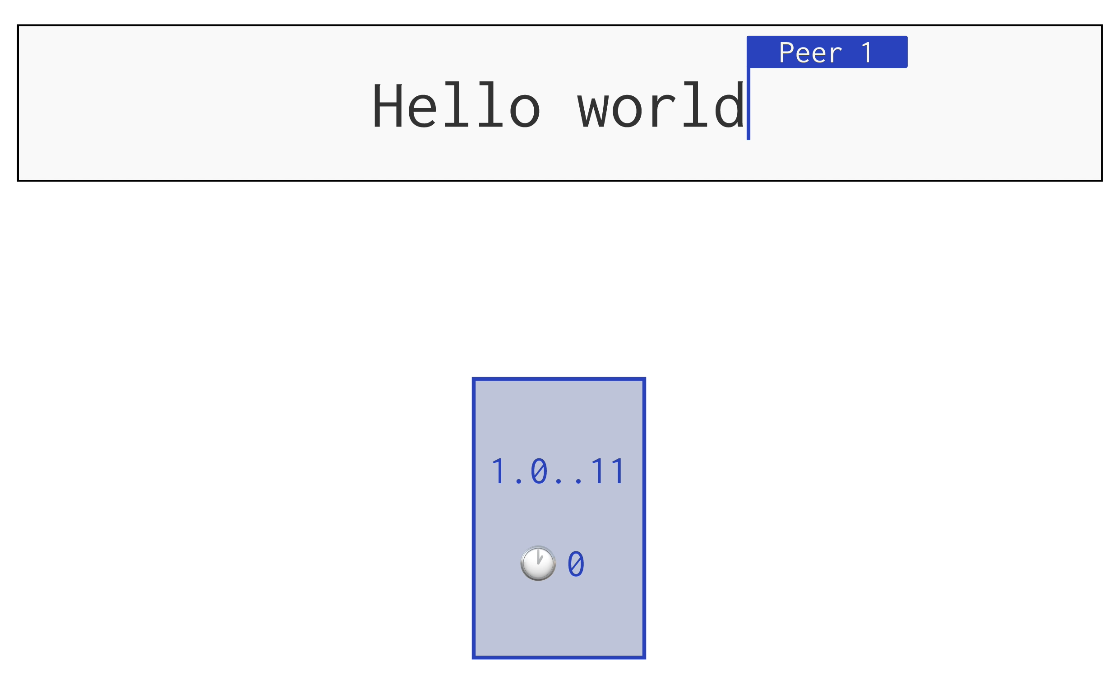
链表的线性结构会导致很多操作需要进行遍历,节点一多就非常影响性能,更好的选择是 B-tree。B 树是一种平衡树,其中每个节点可以拥有介于最小值和最大值之间的可变数量的子节点。 “平衡”仅仅意味着对于每个内部节点,其所有子节点都具有相同的高度。其节点存储其偏移量,这样我们寻找我们所需的数据时,就只需要对数时间了。原文还讲了 G-tree,这里就不做展开了。
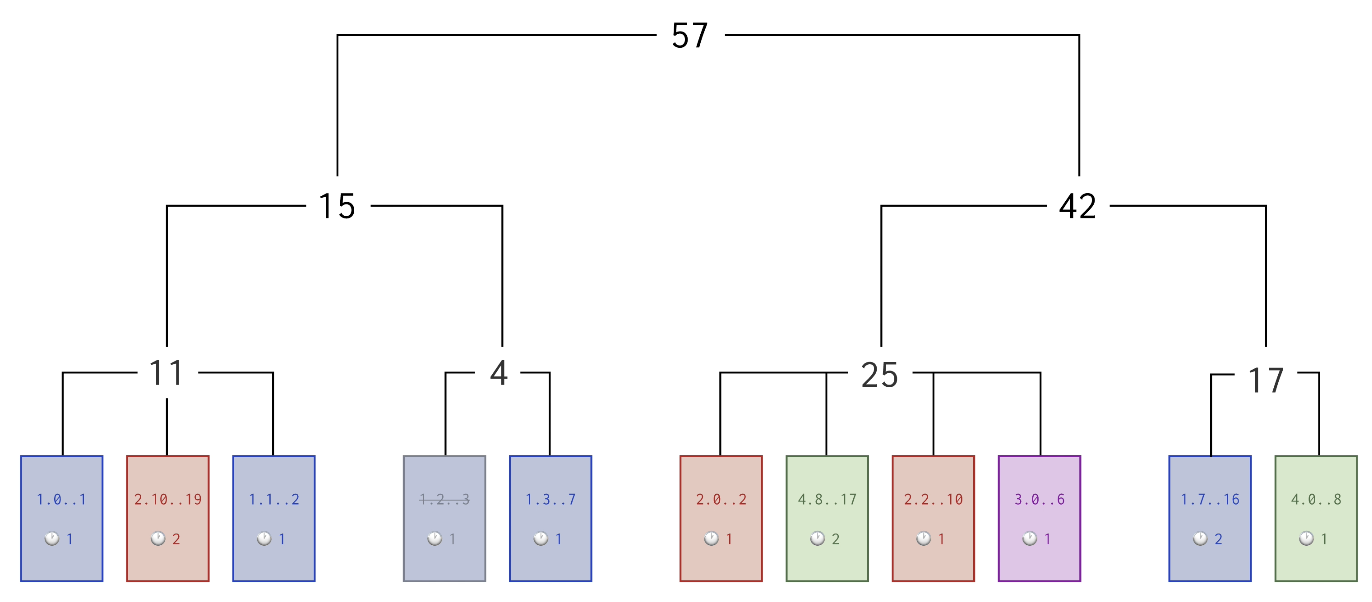
cola 的使用示例,在官方文档也有展示,总体而言,是一个实现多人协作文档的不错的选择。
参考
文章作者 calssion
上次更新 2023-09-18