【论文阅读】C++ 二进制插桩检测程序缺陷
文章目录
本文是对硕士学位论文《基于二进制指令插桩的C++程序缺陷检测技术的研究与实现》的阅读笔记,作者对于 C++ 程序缺陷以及检测手段都有很详细地描述,感兴趣的建议看原论文。
1、程序缺陷检测技术手段
1.1、静态分析
静态分析指不运行程序,直接对应用程序的源代码或者机器码等进行缺陷分析。
1.2、动态测试
动态测试指通过直接运行程序的方式对应用程序进行缺陷检测。
1.3、对比
| 静态分析 | 动态测试 | |
|---|---|---|
| 优势 | 可以比较全面覆盖程序所有执行分支 | 准确率高 |
| 劣势 | 准确率与运行开销之间难以平衡;误报率较高,需对结果人工验证 | 在构造设计测试用例上需花费较多时间;漏报率较高,只能测某条路径的缺陷,需多次测试;拖慢程序的运行时间 |
| 基本操作 | 先通过对应用程序的代码进行语法分析、数据流分析等工作,再将这些分析之后得到的控制流、数据流和已有的缺陷模式进行匹配 | 构造测试实例、执行程序、分析程序的输出结果 |
| 相关工具 | lawfinder、fortify、coverity | SystemTap、 Gprof |
2、C++ 程序缺陷
2.1、内存泄漏
内存泄漏特指在程序的执行过程中,通过使用库函数或者调用操作系统 API 动态分配了堆内存之后,丢失了用于释放该块内存的指针,从而导致申请的堆内存无法被释放的行为。
尽管在进程结束时操作系统会将该进程占有的,包括动态申请的堆内存在内的,绝大部分资源进行回收。
但是对于那些需要长时间运行的程序,内存泄漏仍会造成非常大的危害。因为不停的申请堆内存而不释放,进程以及操作系统的可用存储空间会越来越少,最终严重影响系统效率,并且接下来的内存申请操作都会失败。在些情况下,操作系统甚至会直接杀死那些内存使用过多的进程,以保证系统的稳定性。
2.2、内存释放错误
C++ 程序开发者不仅仅可以通过 brk、mmap 等系统调用来申请堆内存,还能通过 malloc、realloc 等库函数,以及 C++ 语言中的 new/new[] 操作符来申请堆内存。而在进行内存的释放时,也必须根据堆内存申请的具体方式选择对应的释放手段。所以如果申请和释放的方式不匹配的话,很容易引发未定义行为,从而影响程序的正常运行逻辑。此外,对无效的地址进行释放,同样也会造成未定义行为,比如重复释放同一个指针。
由于错误的释放方式通常都会导致未定义行为,而未定义行为都是根据具体编译器的实现以及每次程序的运行状态不同而变化的。这些未定义行为使得内存释放错误也变得难以定位。
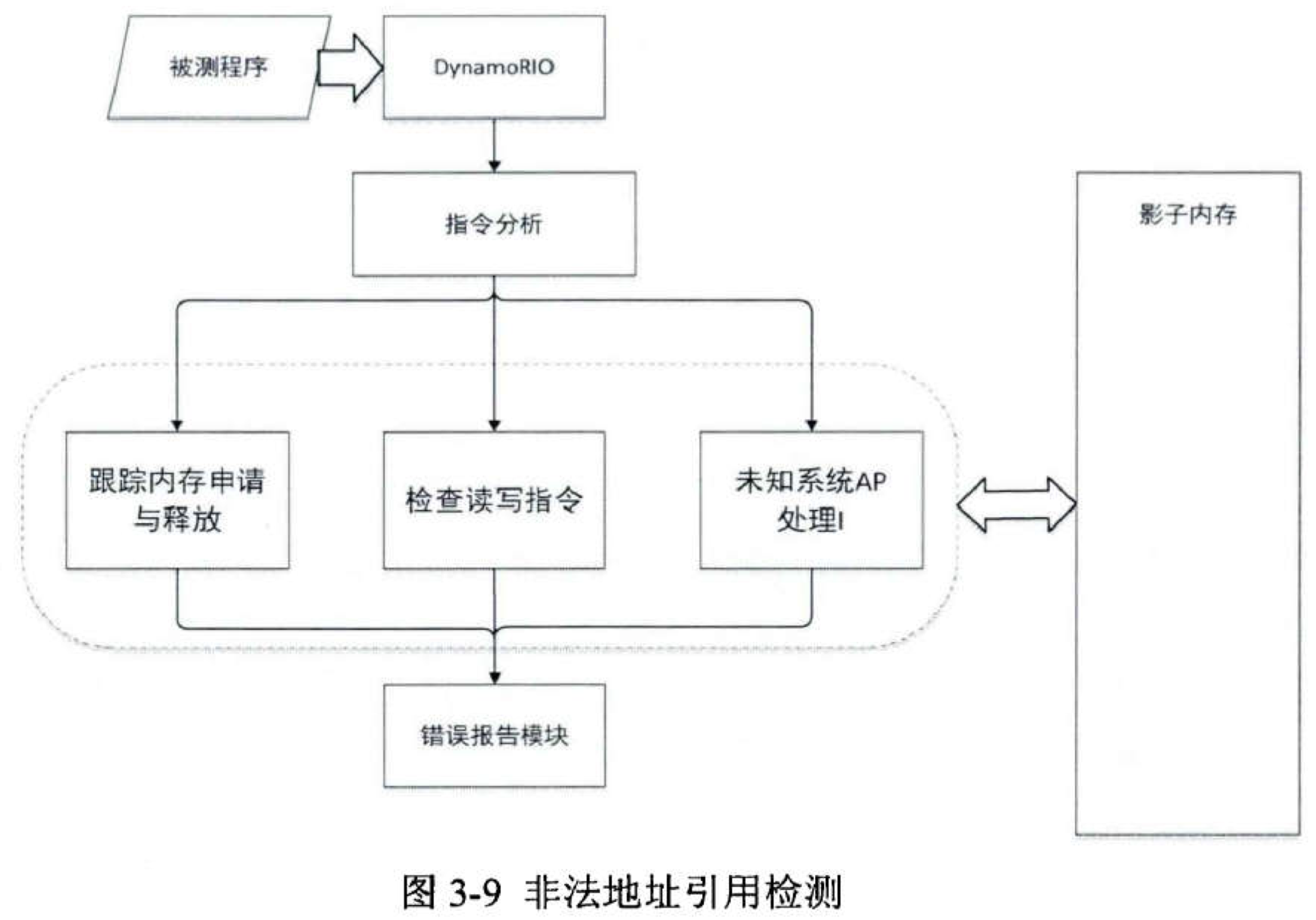
2.3、非法地址引用
非法地址引用是指应用程序试图去读写错误的内存地址的行为,这类错误往往能够导致程序出现逻辑错误甚至直接崩溃。这类错误可以分为两大类,一种是试图读写无效的内存地址,另外一种则是试图去读取未初始化的数据。
这里无效的地址不仅仅指那些只有操作系统内核才能访问的内存区域、以及尚未分配的堆区内存这类操作系统层面的无效地址,也包括的库函数层面的无效地址。很多内存分配器,如标准库中的 malloc 函数,在具体实现时都会事先通过操作系统的 API 向操作系统申请一整块堆内存,当其他模块调用相应的接口来申请堆內存时,再由分配器从这些已经申请好的内存中截取合适大小的内存,并将其地址返回给调用的模块。这意味着对于除内存分配器本身之外的代码,尽管操作系统分配了一整块连续的内存,但是只有由分配器所返回的那一部分内存是可以正常访问的。
通常情况非法地址引用会造成程序直接崩溃,但是读写那些仅由库函数可见的部分,以及使用未初始化的数据却能造成未定义行为。如同上文所提到的,在 C++ 语言中,那些能够造成未定义行为的错误往往都是很难定位与修复的。
2.4、缓冲区溢出
缓冲区溢出发生的原因主要有两种,一种是因为程序中客户代码的逻辑错误从而导致的缓冲区溢出,如数组越界错误;另外一种则是因为在调用库函数以及操作系统 API 时,传递了错误的参数从而导致的缓冲区溢出,比如在 memcpy、strcpy 等标准函数时发生缓冲区重叠,在使用 POSIX 标准的 read 函数时指定了错误的缓冲区长度等等。
缓冲区溢出错误在各种操作系统和应用软件中广泛存在,缓冲区溢出错误往往能够造成非常严重的损失并且难以发觉,因为只有被写坏的数据和由于缓冲区溢出而读到的无效的数据被使用时才会造成程序的逻辑错误,从缓冲区溢出到程序出现未定义行为的过程中存在一定的延迟。更严重的是,当程序中的函数返回地址等敏感数据被修改时,会直接影响到程序的执行控制流,一旦被黑客利用,甚至可以直接将程序控制流跳转到恶意代码的起始地址上,从而达到恶意代码注入的目的。
3、程序插桩技术
3.1、源代码插桩
手动在需要收集信息的地方插入探针,之后重新编译运行被测程序。
3.2、静态二进制插桩
直接对程序编译之后的二进制机器码进行插桩。
3.3、动态二进制插桩
在程序运行时,直接接管被测程序并且截获其二进制指令并插入探针。
被广泛用于程序分析(性能分析-cache 命中等)、体系架构研究(对处理器进行信息收集)、二进制指令翻译(替换平台不支持的指令)。
3.4、对比
| 优势 | 劣势 | |
|---|---|---|
| 源代码插桩 | 能够准确地插入探针;插入探针的代码也能被进行编译优化 | 没有源码无法插桩;对编程语言敏感,难处理混编;不能对正运行的程序插桩;难以得到彻底控制,如访问寄存器等 |
| 静态二进制插桩 | 不需要源代码;能够获取到寄存器信息 | 编写难度大;平台相关,可移植性差;对动态链接库难以操作;不能对正运行的程序插桩 |
| 动态二进制插桩 | 不需要源代码;可以操作到动态链接库的代码;获得对程序的彻底控制;不需要重新编译程序 | 工具编写难度大;运行时开销高;抽象程度低,丢失如类型信息等 |
4、动态二进制插桩框架
4.1、Pin
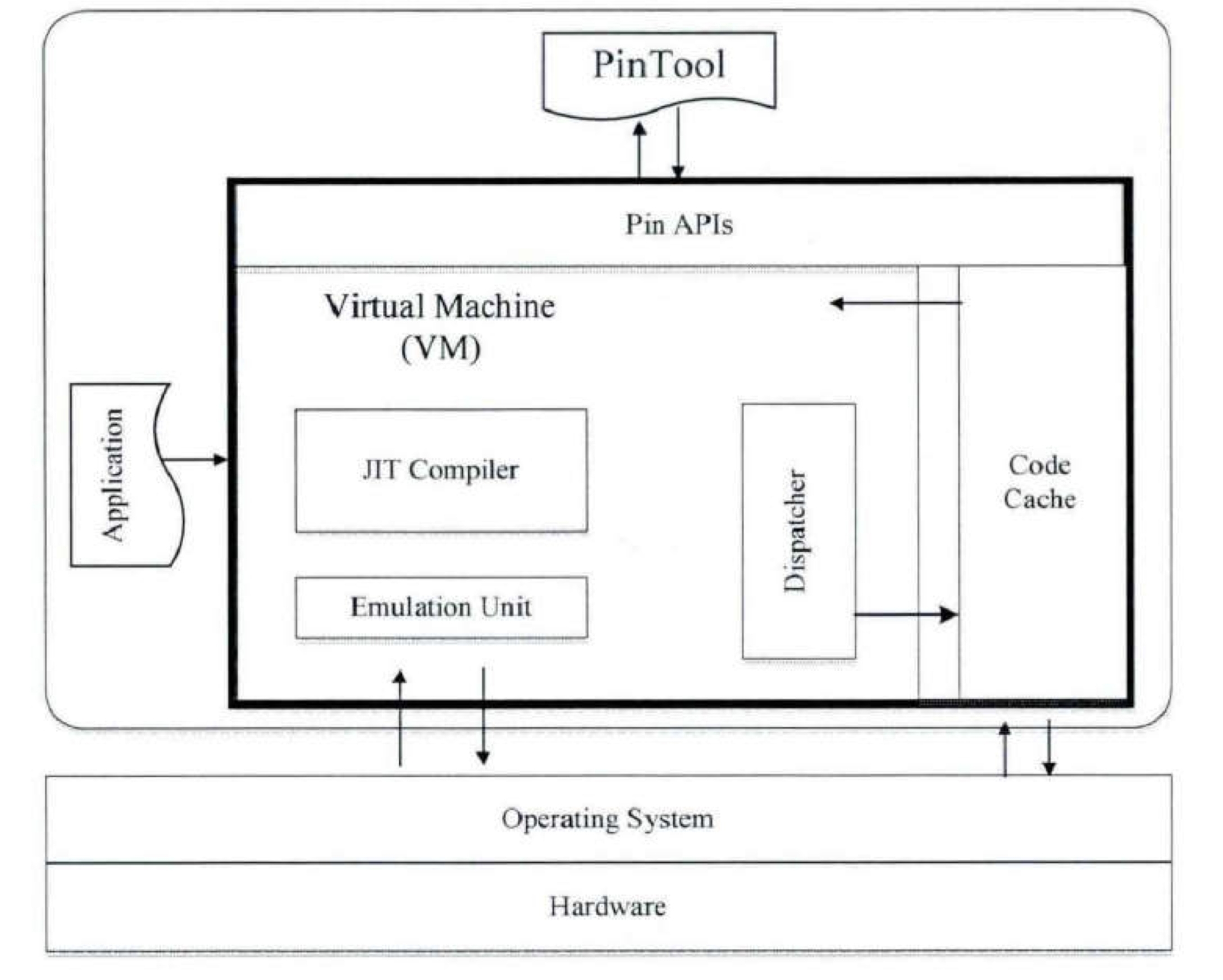
Pin 在框架内部实现了一台虚拟机,虚拟机内存包括了一份完整的运行时上下文,在读取被测程序的二进制机器码作为输入时,Pin 会根据被测程序中的跳转指令和 Pintool 的插桩粒度,将被测的二进制机器码切分成一个个小的代码块。
检测开始时,Pin 框架读取被测程序的二进制机器码,以代码块为基本单位插入 Pintool 中设置好的探针,再通过虚拟机的 JIT 编译器将该代码块翻译成能够直接在实际宿主机器上运行的二进制机器码,最后通过调度器 (Dispatcher) 将转换完毕的代码块缓存起来并在适当的时机调度运行。
4.2、Valgrind
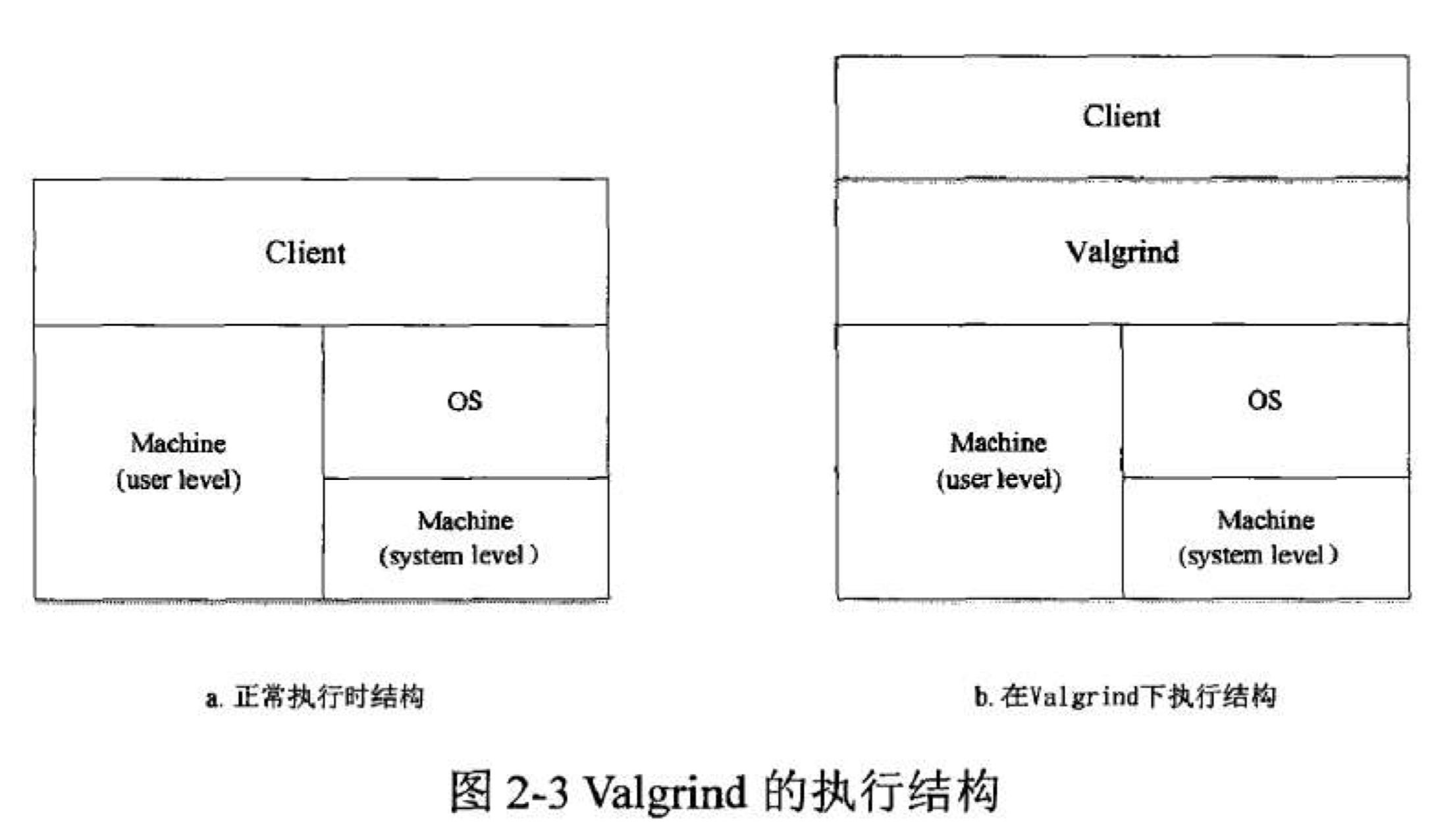
Valgrind主要由内核和工具构成,内核负责底层的二进制代码分析和 JIT 编译等工作,而工具则负责编写具体的插桩逻辑。在 Valgrind中,所有的机器码,包括探针代码,都会被翻译成一种统一的中间指令,这种中间指令在 Valgrind 中被称为 IR。
Valgrind 执行检测的过程可以分为以下几步:
1、初始化,启动器读取并分析指令,根据具体的系统启动正确的工具文件。
2、读取机器码并进行反汇编,将机器码翻译成 IR,并对 IR 进行第一次优化,包括展开复杂指令、消除冗余、死代码消除等。
3、对 IR 进行插桩,在反汇编之后的 IR 指令中插入指定的探针,并再次进行指令优化。
4、对 IR 指令进行寄存器分配,将虚拟的寄存器映射到实际的主机上去,最后根据宿主机的指令集对 IR 进行汇编,至此,代码块已经被插桩完毕并且可以直接在真实的硬件环境中运行。
5、将翻译插桩完毕的代码交由调度器(Dispatcher)进行调度运行。调度器还负责对已经翻译完毕的代码块进行缓存,以提高程序的运行速度。
4.3、DynamoRIO
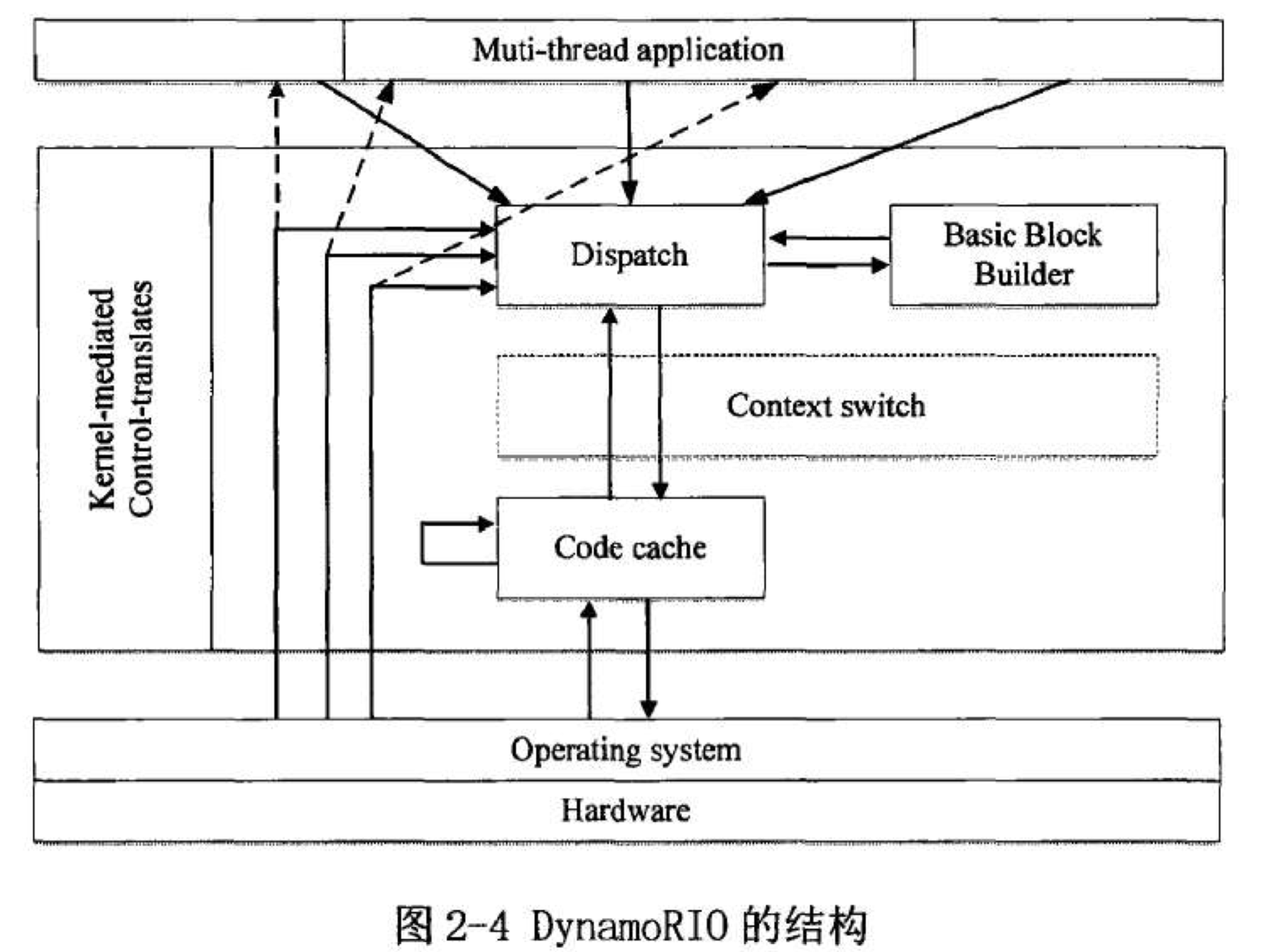
DynamoRIO 的内核主要由三个模块组成:调度器(Dispatch)、基本块构建器(Basic block builder)和代码缓存器(Code cache)。其中基本块构建器负责从被测程序中切分出基本块并完成插桩,代码缓存器负责缓存并管理已经插桩完毕的基本块,最后由调度器来截获被测程序的指令,完成内存事件的分发并协调各个模块之间的工作。
为了解决在解释执行过程中造成的运行时速度大幅降低的情况,DynamoRIO 使用了指令缓冲技术和分支预测技术来减少解释执行所带来的成本。
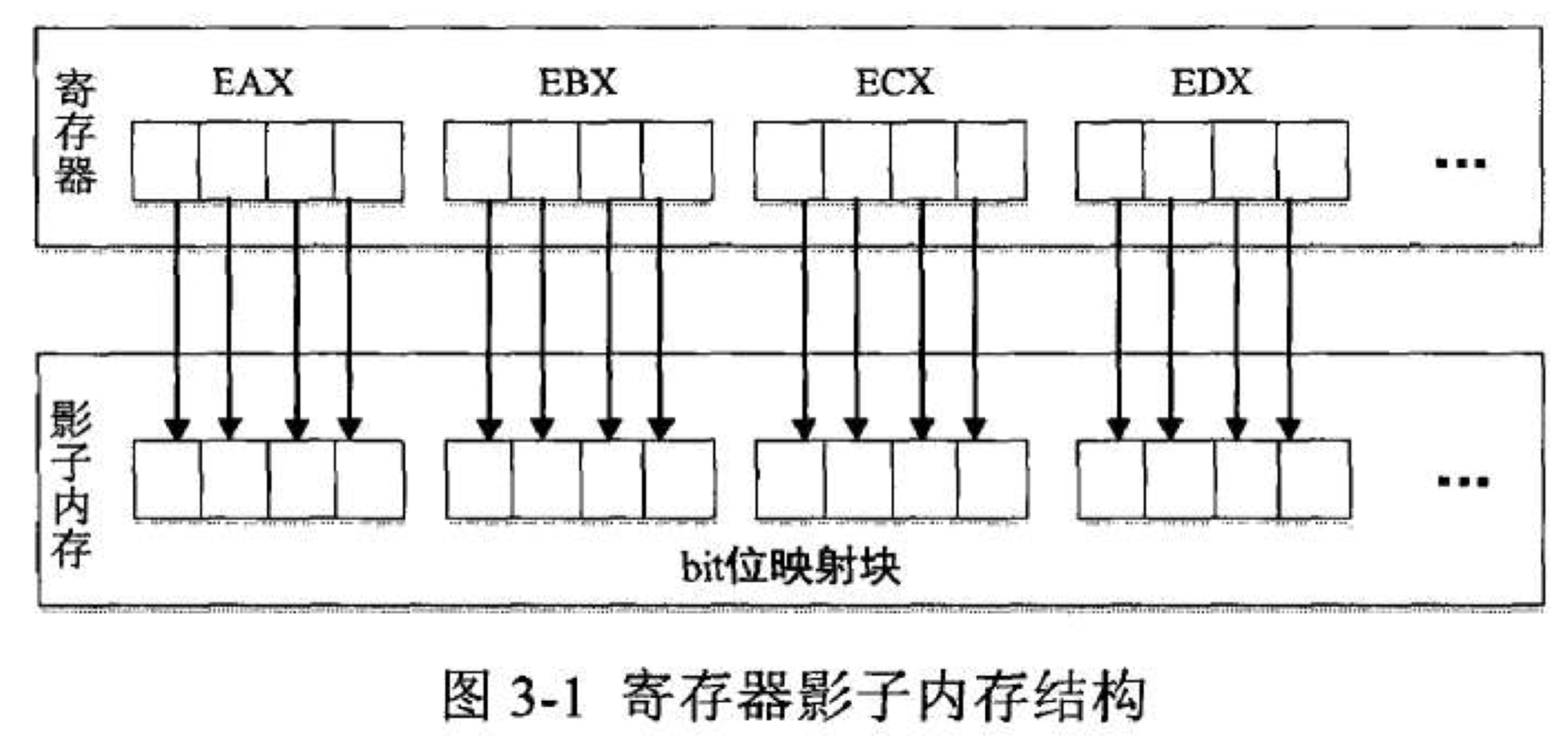
5、影子内存
5.1、定义
根据百度百科,影子内存(shadow RAM)是基本输入输出操作系统(BIOS)程序在随机访问存储器(RAM)中的一个备份,它们能被更快的访问。
影子内存技术的基本思路是通过使用额外的内存空间(影子内存),来映射被测程序的实际虚拟内存,在被测程序被执行的过程中,跟踪被测程序的内存操作序列,并将相关信息记录在影子内存中,最后根据影子内存所携带的信息完成对被测程序运行情况的跟踪和检测。
影子内存技术在实现上的难点在于平衡检测精度和跟踪程序指令并维护影子内存所带来的额外运行时开销。针对不同的编程语言,需要根据其具体的语言实现机制以及其具体的内存管理手段来进行对应用程序指令的跟踪以及影子内存的维护。同样的,在设计影子内存时还需要根据具体的需求来决定影子内存的映射粒度。
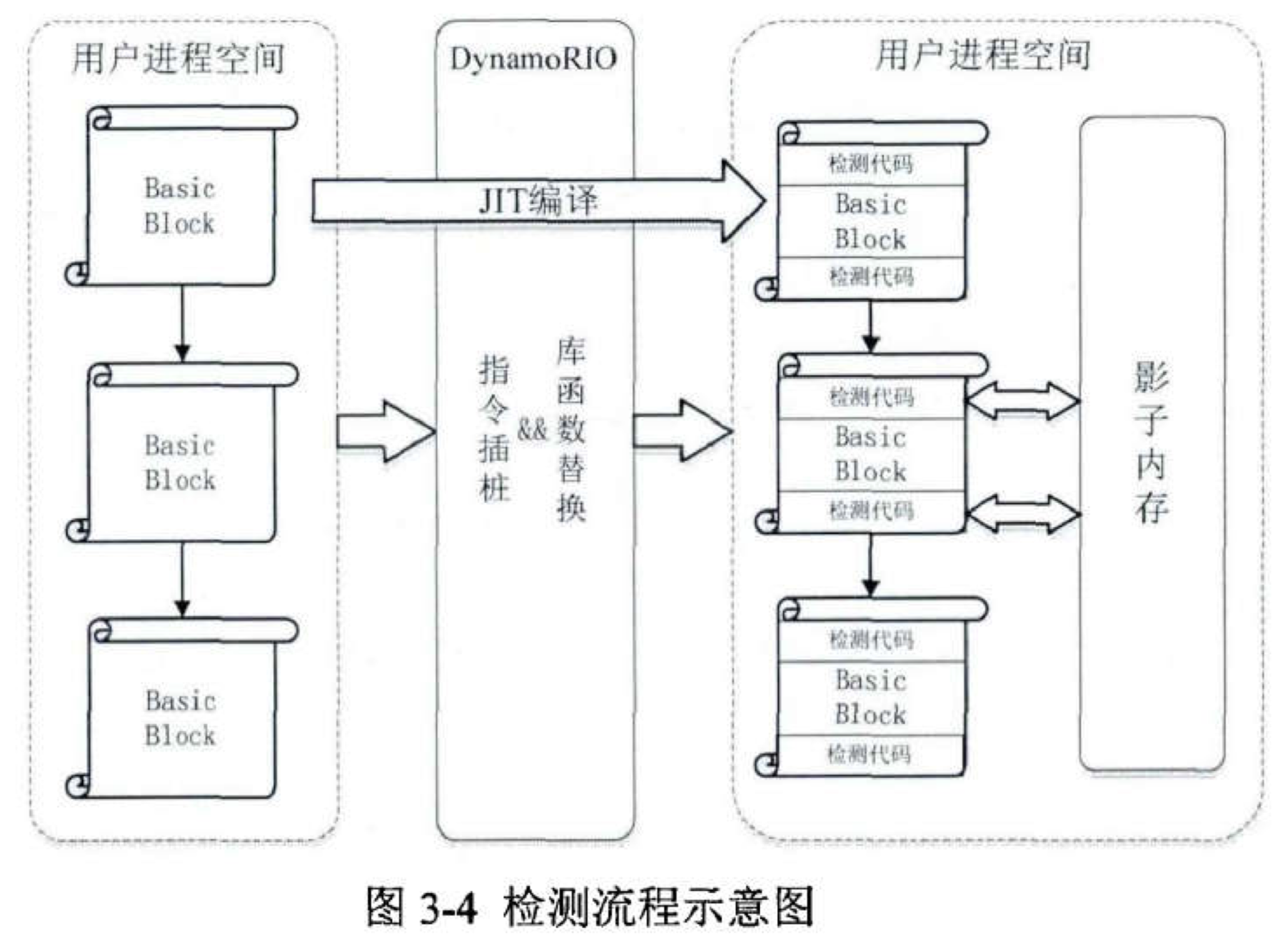
6、检测方法
6.1、内存申请操作的跟踪
大部分内存分配库都是使用动态库的方式来实现的,在程序载入时可以通过符号表来获取到这些函数的函数名,所以可以通过 DynamoRIO 的函数替换功能,就能以带有信息记录代码的版本替换这些原来的动态内存申请操作。
6.2、内存泄漏检测
将被测程序已经申请的堆内存按照持有情况分为三类:一定可达的、一定不可达的、可能可达的。
一定可达的指属于进程持有的指针集合的内存块。
可能可达的指没有直接保存内存块的起始地址,但保存了指向内存中间某个位置的指针,这种情况较难判断内存是否泄漏。
一定不可达指不存在指向这些堆内存的指针。
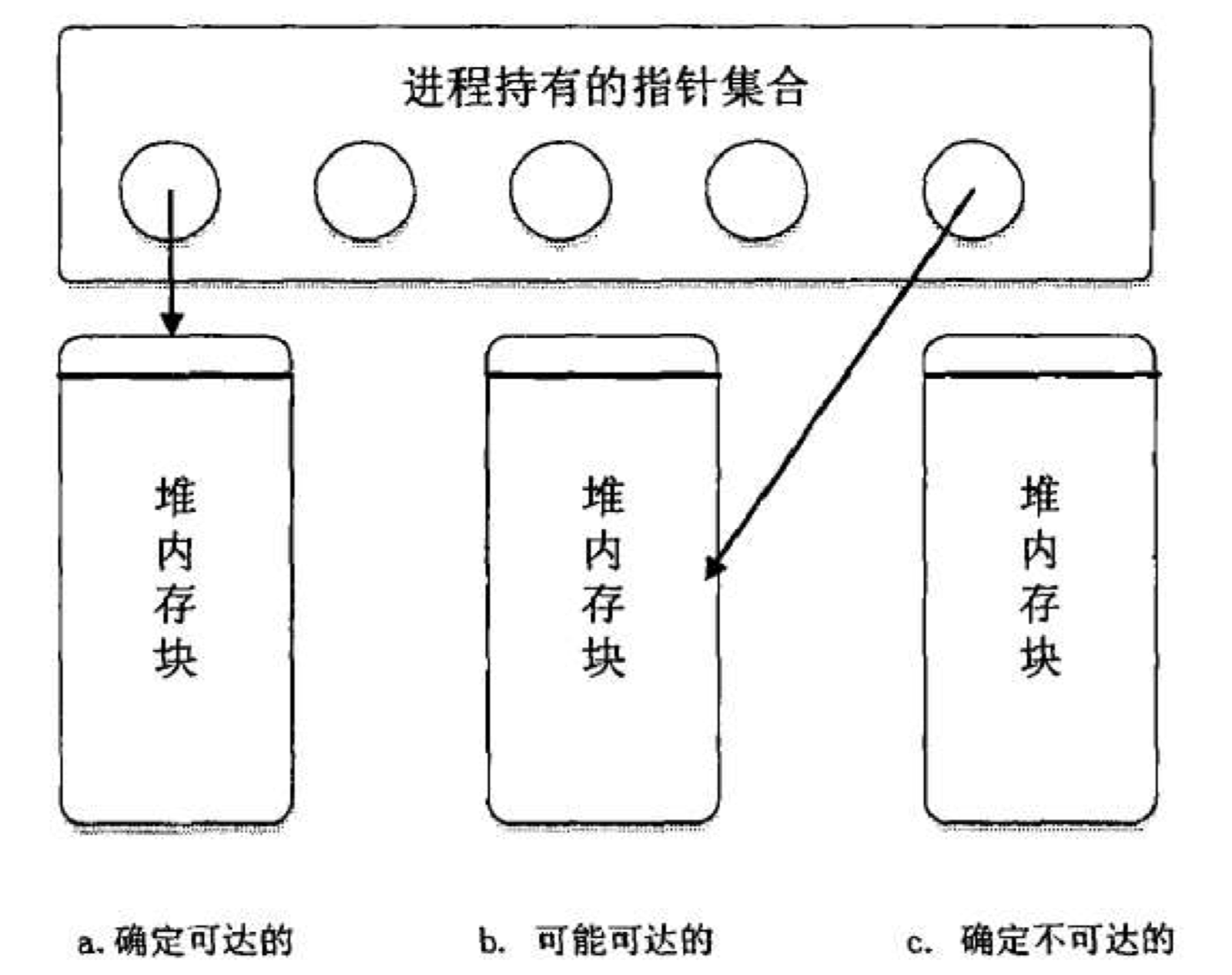
利用 C++ 内存对齐的特性,配合影子内存中保存的记录,在内存块中检验地址为 4 的整数倍的内存地址,就可以获取某一块内存中可能的指针。
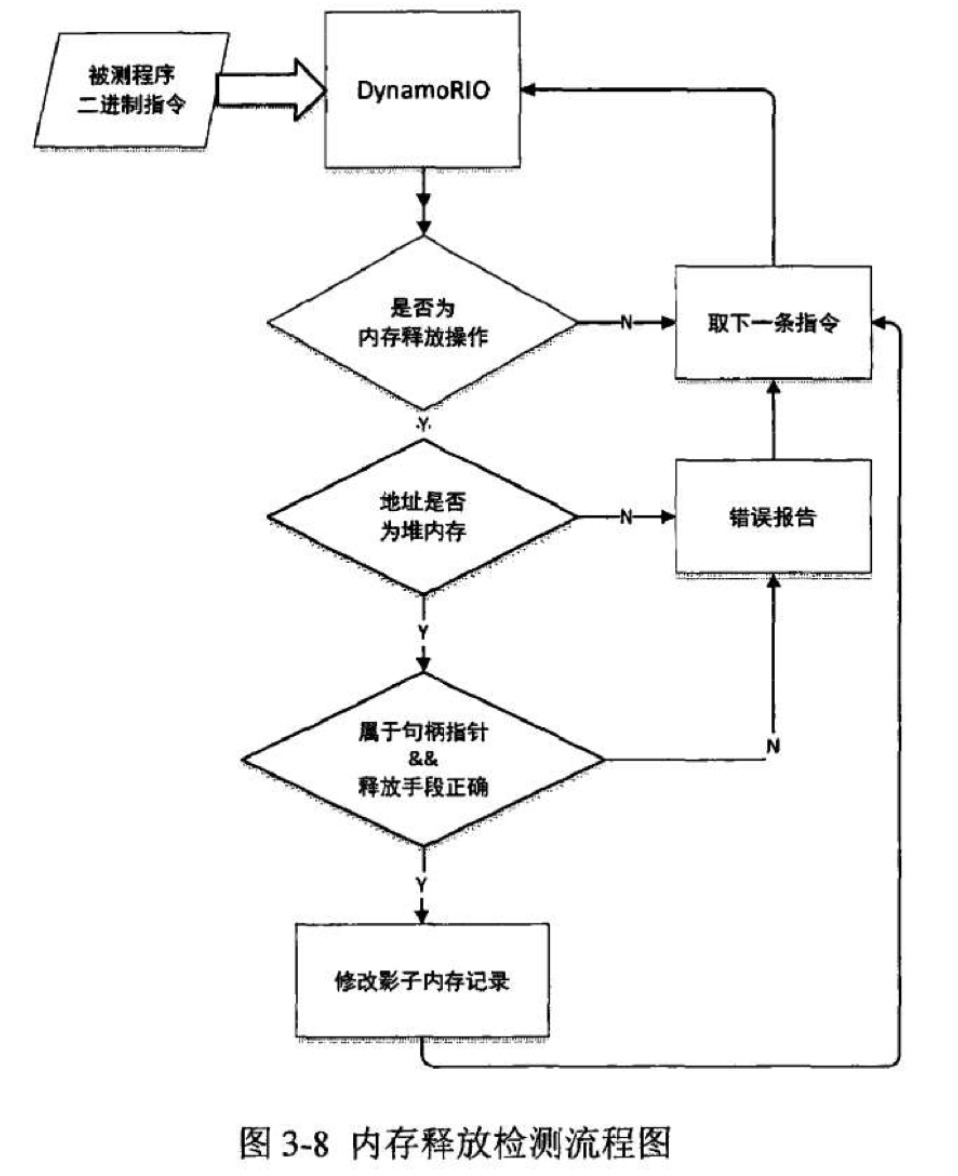
6.3、内存释放错误检测
通过 DynamoRIO 的函数替换 API,可以将这些内存分配/申请函数进行替换,在申请时将他们的调用信息记录到堆影子内存的申请信息表中。
同样的,通过对释放函数的替换,在函数释放之前,会在释放地址所对应的申请信息表中查找申请信息,如果释放的类型同申请信息表中记录的申请信息不匹配或者在申请信息表中找不到对应的句柄指针,那么会尝试对这些操作进行相应错误处理,并将错误记录到错误报告中。
6.4、非法地址引用
6.5、缓冲区溢出检测
对于栈内缓冲区溢出,只要溢出的部分没有覆盖到其他的栈变量,这次缓冲区溢出所造成的影响其实是处在控制之中的。这种类型的栈内缓冲区溢出既不会写坏栈中存储的敏感数据,在读到未初始化的填充字节时,这些未初始化的填充字节也能够被影子内存很好的跟踪。对于影响到了其他变量的栈内缓冲区溢出,是可以通过边界影子内存追踪到的。这对于保护栈中保存的敏感数据十分重要。
由于栈内存的分配只跟栈寄存器 SP 中保存的栈指针有关,所以只需要对跟踪被测程序中对栈寄存器 SP 的操作,比如 POP、PUSH、CALL 等指令,然后根据具体的指令语义对栈影子内存进行跟踪即可。
缓冲区溢出的另一个重灾区是危险函数的不当使用,比如在使用标准库中的 strcpy 函数时,缓冲区的检查是由程序员完成的,这很容易出现诸如缓冲区重叠、缓冲区溢出等错误。在 C++ 的标准库函数中有非常多的危险函数,如 gets、 printf 等等。这些危险函数也是造成缓冲区溢出以及导致某些安全漏洞的主要原因。由于这些危险函数一般都是通过动态链接库完成并且可以直接获取函数名字的,所以可以通过 DynamoRIO 的函数替换,使用包裹后的函数替换掉原来的危险函数,并且在新的函数中加入边界检査是一种非常方便的做法。这种方案不需要修改源代码并且重新编译原来的函数就能完成缓冲区溢出检测。这些函数的替换版本中増加的额外检測代码主要为 strcpy、 memcpy 增加边界检査,memcpy 增加缓冲区重叠的检査等等。
参考
硕士学位论文《基于二进制指令插桩的C++程序缺陷检测技术的研究与实现》—— 何磊
文章作者 calssion
上次更新 2021-06-19