C/C++ 尾调用优化案例
文章目录
看到一个尾调用优化的案例,把 Protobuf 解析速度提升了两倍,达到 2+GB/s,简单做了下笔记,详细可以看看原文。
实际上原文也解释了两倍性能提升不只是因为尾调用优化,但它还是属于其中比较关键的优化。
尾调用优化
之前写过关于尾调用优化的文章,如果一个调用发生在函数执行的末尾,那么 callee 可以尝试优化成直接复用 caller 的栈帧。
|
|
这么优化有几个好处:
- 减小了栈内存的消耗,防止栈溢出(stack overflow)。
- 更加高效的跳转指令。(x86 用 jmp 代替了 call,arm 用 b 代替了 bl)
- 可以帮助尽可能地把重要数据保留在寄存器中,而不用重新从栈或内存加载。
- 减少函数中执行不频繁/执行慢的区域指令的影响,通常是处理异常返回。
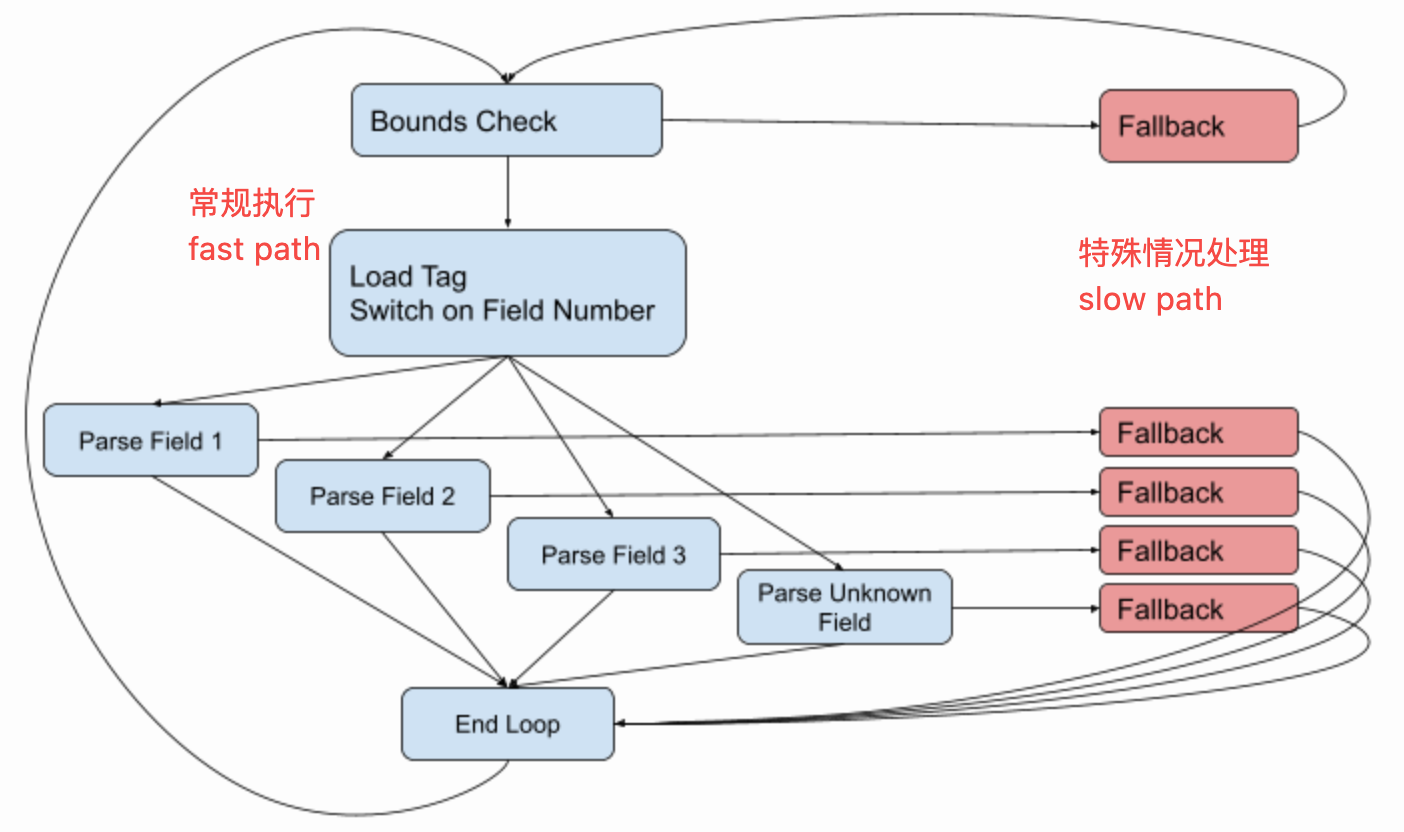
musttail
通常优化级别开到 -O2,Clang 编译器就能够判断去进行尾调用优化,不过并不能够完全保证,因为编译器需要考虑更多的边界条件,来保证其正确性和完备性。
Clang 提供了 [[clang::musttail]] 和 __attribute__((musttail)) 来让开发者提示编译器进行尾调用优化,即使在没有开启编译器优化级别的情况下也生效,目前这个属性已支持 C、C++、OC。

上图是没有开启优化级别时代码和对应汇编指令的情况,减少了栈操作的指令。当然实际操作会开启优化级别,Protobuf 解析的优化就是在每个处理类型数据的函数中,加上了尾调用优化的这个保证。
参考
文章作者 calssion
上次更新 2023-05-22