尾调用优化简介
文章目录
看了篇 WebAssembly 实现尾调用的文章,其中关于尾递归调用的优化描述不错,本文简单介绍一下。
1、尾调用
递归调用会由于过深的递归栈,可能导致出现栈溢出(stack overflow) 问题。而如果一个递归调用发生在尾部(在函数返回之前),那么就可以认为是尾递归。
这在 CPS(Continuation-passing style、延续传递方式) 是一个关键概念,在函数式编程会有所体现,其一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数。
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用(side effect)。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
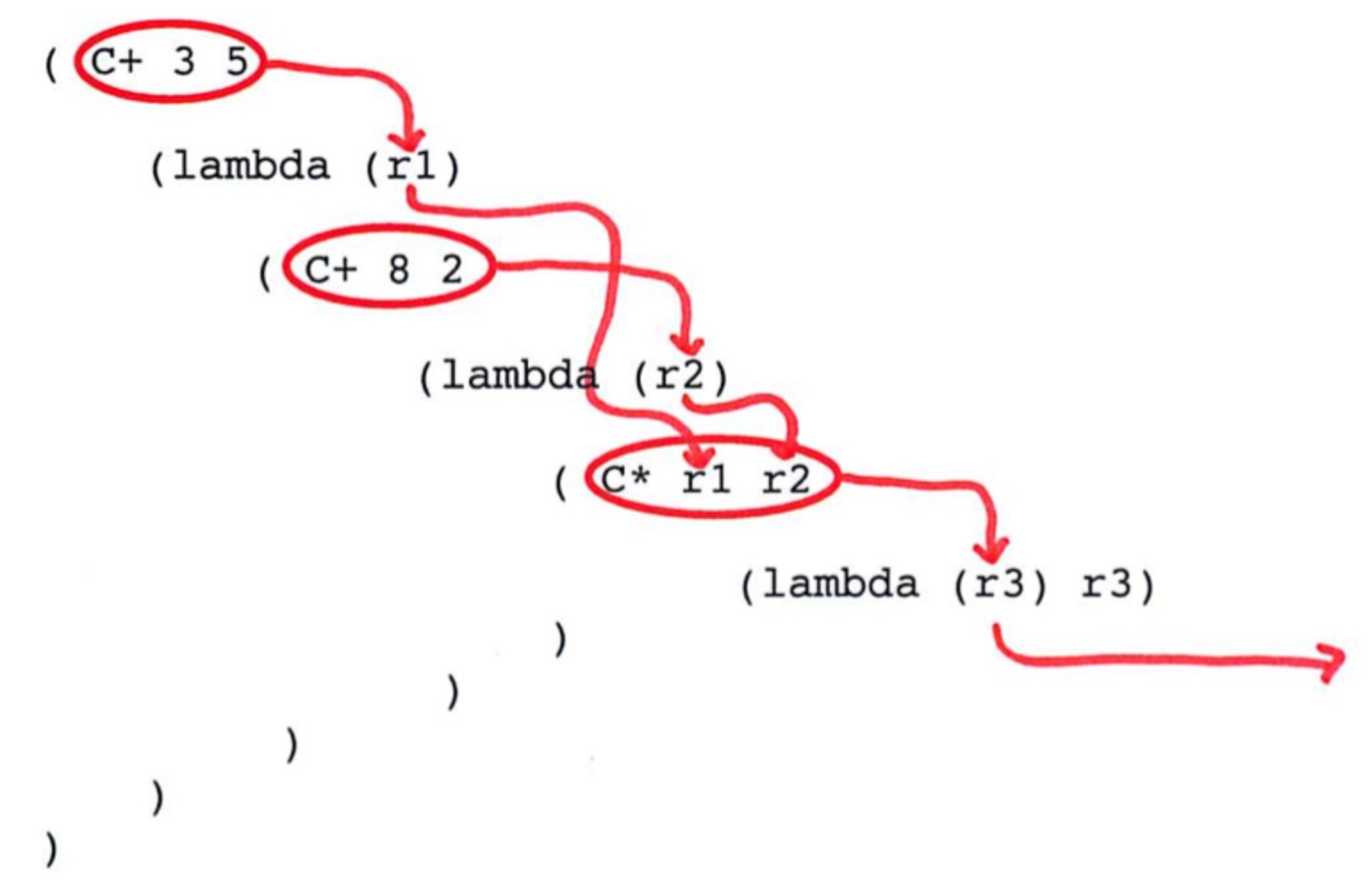
如果 caller(调用方) 的调用栈(stack frame) 可以在跳转到 callee(被调用方) 之前复用,就可以调整尾调用(tail calls)。用来避免过多的栈消耗。
2、示例
|
|
每种语言都有自己的调用约定(calling convention),这里我们用 c++ 代码转换成机器码层面,就可以看出栈的消耗了,包含有 prolog(入栈操作、保存数据) 和 epilog(出栈操作、还原数据)。
栈数据主要在 fp(frame pointer、%rbp、帧指针,指向当前栈的第一个字节) 和 sp(stack pointer、%rsp、栈指针,指向栈顶) 间,在 fp 和 sp 之间的就是函数栈的数据了。由于寄存器有限,用栈来存储数据进行传递是很常见的。
在执行函数体时,会先保存栈数据,其中也会把帧指针 %rbp 入栈。
下图是栈帧的逻辑:
|
|
对于尾调用而言,这么多重复的 prolog 和 epilog 是很大的浪费,所以才有了尾调用消除(tail call elimination),将 callee 认为是 caller 的一个扩展。
3、优化
消除重复的栈帧,不止可以避免运行时栈溢出的问题,还可能优化递归调用执行的性能。
我们简化一下调用链 print_factorial → factorial 0 → factorial 1 为 A → B → C。
在这里我们实现尾调用的优化,把 A 和 B 做合并,也即 B 可以直接复用 A 的栈帧,然后让 C 执行完,直接返回到 A。
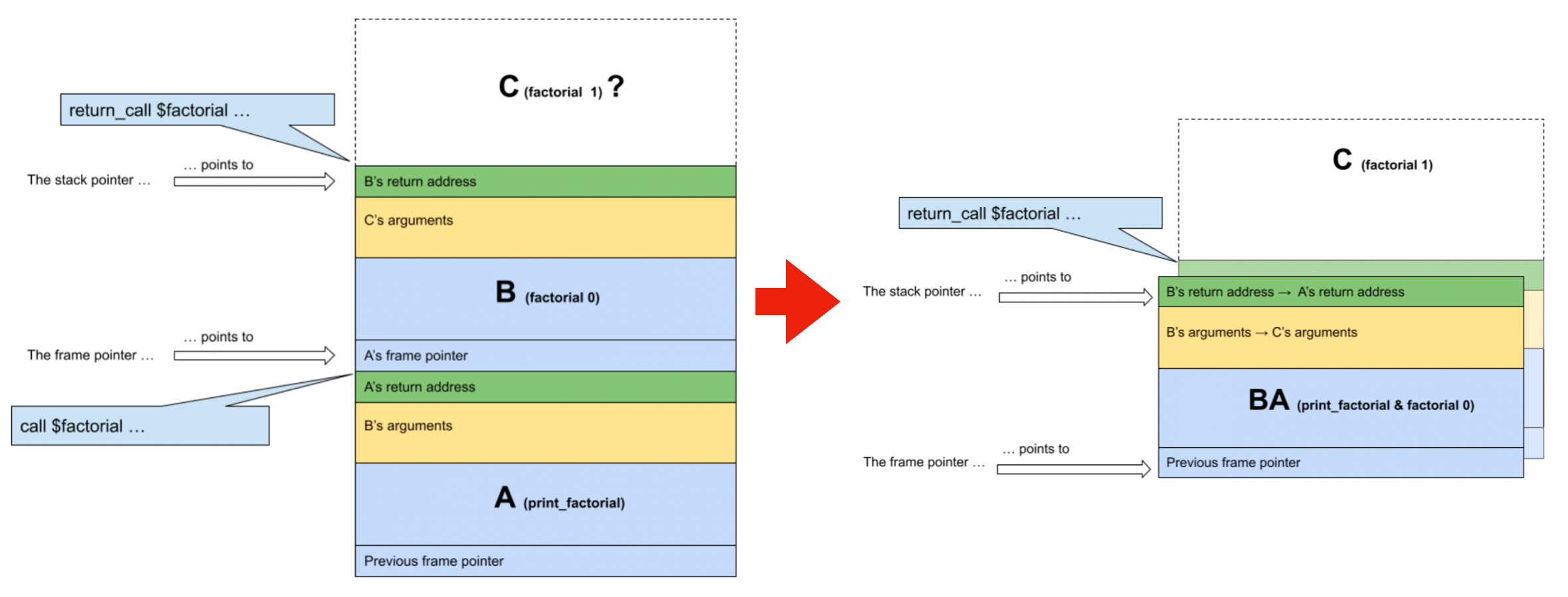
由于 B 函数含有 return_call 指令,所以可以复用栈;在跳转到 C 之前可以把 A 和 B 做合并。这时候需要保证 C 会直接返回到 A,使用 jmp 指令调用 C 而不是 call 指令,可以保证 lr(linker register、返回地址) 不会被重写。 重新计算新的栈偏移,然后存储从 B 到 A 所需要的数据(即复用 A 的栈来存储 B 原本栈上的数据)。如此往复,继续优化。
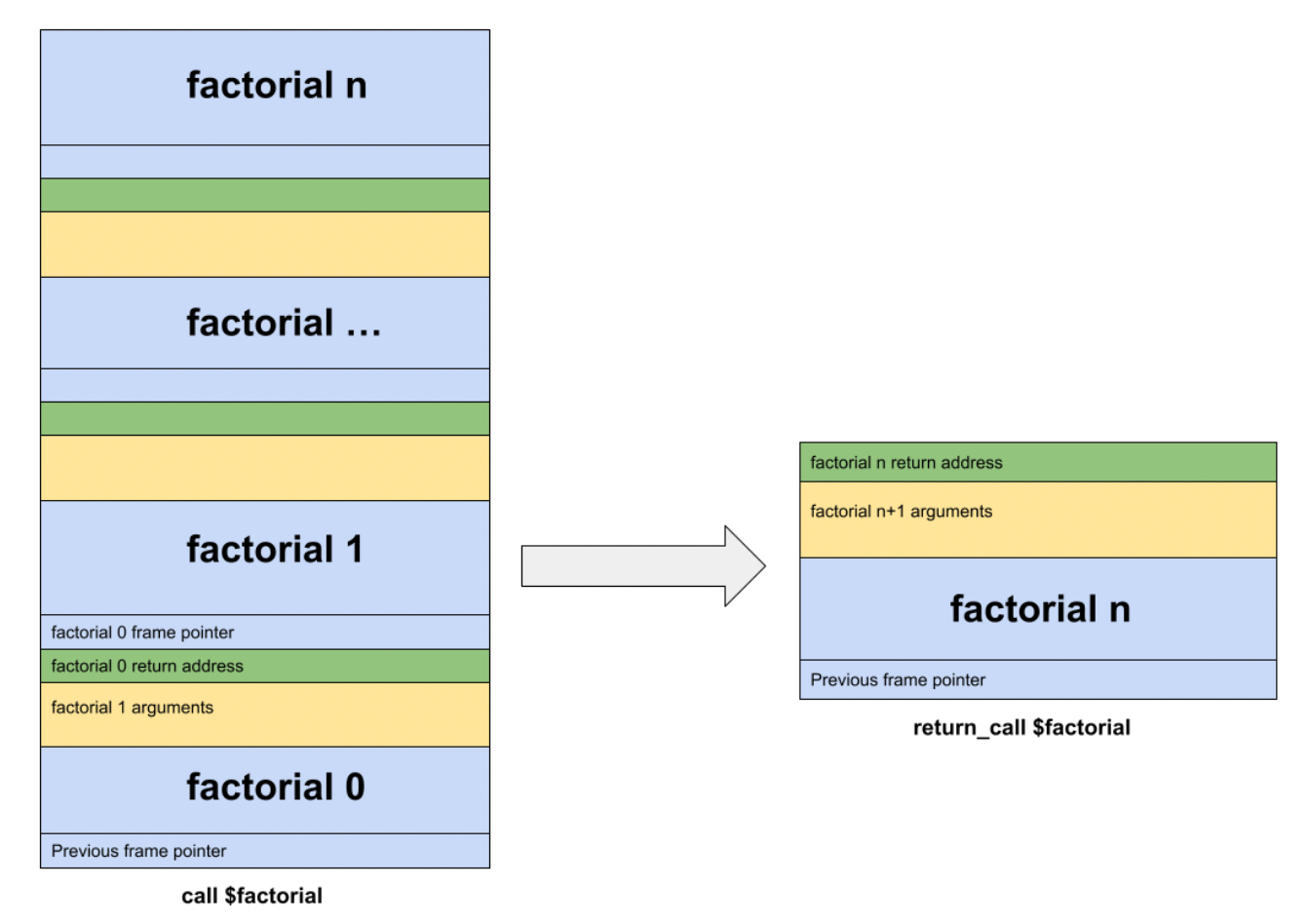
最终可以有机会把尾递归的调用的大部分重复冗余栈帧,给优化掉。对于尾递归调用这个过程,比较像是把尾递归转换成循环来进行处理。
在 LLVM 当中,除了常规的限制,不同的指令集,对于尾调用是否进行优化,还会有一定的限制,具体限制在官方文档这里能找到,比如在 AArch64 上的限制是没有可变参数(variable argument lists) 的存在。
参考
文章作者 calssion
上次更新 2023-04-01