编译器的新思路:告别"支配关系",拥抱"自由变量"
文章目录
最近看到一个关于编译器分析优化的新思路,感觉很有趣,本文来简单介绍一下。
1、背景:编译器里的"老规矩",以及它为什么开始掉链子
虽然我之前写的文章都有涉及过,但论文需要有这个背景以及对比说明,所以这里还是讲下 SSA 和支配关系,不感兴趣可跳过。
注:本文有 AI 辅助创作,确实排版和阅读都比纯手工更好。
1.1、先理解编译器在干什么
当你写好一段代码,编译器不会直接把源代码翻译成机器指令——它会先把代码变成一种叫做 中间表示(IR, Intermediate Representation) 的内部形式,然后在这个形式上做各种优化(比如消除重复计算、循环展开、内联函数等),最后才生成机器码。
中间表示的设计直接决定了编译器能做什么优化、做得多快。
1.2、SSA:让编译器"看得更清楚"的一种约定
主流编译器(LLVM、GCC)使用的中间表示叫做 SSA(Static Single Assignment,静态单赋值)。它有一条核心规则:
每个变量在整个程序中只被赋值一次。
这听起来很限制,但实际上极大简化了分析。这里用简单的代码说明一下 SSA 的优势:
|
|
错误的分析可能会认为这里的 y 和 z 是相等的,因为它们有一样的定义赋值 (x+1)。但 x 的值取决于它所处的位置,依赖于上下文,所以这里并不相等。
|
|
如果转成 SSA,就清晰了,现在只有 x1 和 x2 相等,y 和 z 才可能相等。
1.3、支配关系:SSA 的核心基础设施
SSA 依赖一个叫做 支配关系(Dominance) 的概念来判断"变量的作用范围"。
用一个类比来解释:想象程序的执行路径是一座城市的路网,程序入口是市中心。如果去往某个路口 B,必须先经过路口 A,那我们就说"A 支配 B"。
把所有的支配关系组织起来,就是一棵支配树(Dominator Tree):
|
|
如果变量 x 在节点 A 定义,那么 A 所有的子孙节点都能"看到" x。这就是 LLVM 等编译器判断"变量在哪里可用"的核心机制。
1.3、这套机制哪里出了问题?
问题一:支配关系太"保守"了
支配关系基于控制流(程序执行的路径)而非数据流(变量实际的依赖关系)。路径上的代码不一定真的用到了某个变量,但支配关系会把它们全部纳入变量的"影响范围"。这就像因为你必须经过一个路口才能到达目的地,就认为你的旅程"依赖"那个路口——即使你在那里什么都没做。
问题二:高阶函数根本没有控制流图可言
现代编程语言(如 JavaScript, Swift, Rust,以及各种函数式语言)大量使用了高阶函数(Higher-Order Functions)和闭包(Closures)。你可以把函数像变量一样传来传去,甚至深层嵌套定义。函数式语言中,函数是"一等公民"——可以作为参数传递、作为返回值返回、存储在变量里。这类程序没有固定的"执行路径",也就没有控制流图,支配关系根本无从谈起。LLVM 要处理这类程序,必须先把它"降级"成没有高阶函数的形式,这个过程既繁琐又损失信息。
这篇论文提出的方案:用"自由变量"取代"支配关系"
论文的核心主张很简单:与其从控制流出发推断数据依赖,不如直接问每个函数——“你用到了哪些不属于自己的变量?" 这些变量就叫做自由变量(Free Variables),它们比支配关系更直接、更精确地反映了程序的依赖结构。
2、核心问题:一个具体的例子
2.1、程序结构
来看一段嵌套循环的代码(改写自 C 语言的循环语义):
|
|
注意一个关键事实:内层循环体(j = j + 1)只用到了 j 和 n,完全没有用到外层循环变量 i。内层循环确实以 i 的值为起点(j = i 这行),但这个赋值在内层循环开始前就完成了,内层循环运行的时候压根不需要知道 i。
2.2、传统方法(支配树)的误判
假设我们要对外层循环做循环展开(loop unrolling)——把循环体复制多份,减少分支判断的开销。
循环展开意味着:所有依赖循环变量 i 的代码,都需要被复制一份。
传统编译器用支配树来回答"谁依赖 i“这个问题。从控制流的角度看,程序入口到达内层循环,必然先经过定义 i 的外层循环头——因此,支配树会把内层循环也放在外层循环的"子树"里,判定内层循环依赖 i:
|
|
结果:展开外层循环时,内层循环也被复制了,代码膨胀了一倍,但没有任何必要。
2.3、论文方法(自由变量)的精确判断
论文的方法不看控制流,而是直接问每段代码:"你用到了哪些不是自己定义的变量?”
- 内层循环体用到的变量:
j,n——没有i - 因此,内层循环的自由变量集合里没有
i - 展开外层循环时,内层循环无需复制
关键洞察:控制流告诉你"谁在谁之后执行”,但不能告诉你"谁真正用到了谁的数据"。自由变量直接回答后一个问题,因此更精确。
3、核心创新:λG 演算
3.1、从"基本块"到"函数":一个思想实验
SSA 的基本单元是基本块(Basic Block):一段顺序执行、没有分支的代码,块之间通过跳转(jump)相连。每个块的入口可能有来自多个前驱块的变量,SSA 用一种叫 φ 函数(phi function) 的特殊语法来合并它们:
|
|
这个语法很别扭——φ 函数本质上是在说"根据你从哪里来,我的值不同"。
论文的核心观察是:φ 函数就是函数参数! 如果我们把每个基本块改写成一个函数,跳转改写成函数调用,那么 φ 函数自然消失——不同前驱块给函数传不同的参数就行了。
这种风格叫做 CPS(Continuation-Passing Style,连续传递风格):程序不通过返回值传递结果,而是通过调用"下一步该做什么"的函数(称为"延续")来前进。
3.2、λG 的对应关系
| 传统 SSA 的概念 | 对应的 λG 概念 | 直白解释 |
|---|---|---|
| 基本块(Basic Block) | 函数(Function) | 每个块变成一个函数 |
| φ 函数 | 函数参数 | 条件赋值变成参数传递 |
| 跳转(goto) | 函数调用(Application) | 控制转移变成函数调用 |
| φ 函数的参数 | 调用时传入的实参 | 块入口的合并变成调用处的选择 |
| 循环展开 / 函数内联 | β 归约 | 统一为同一个代换操作 |
| 支配关系 | 自由变量 | 核心替换 |
| 支配树 | 嵌套树(Nesting Tree) | 核心替换 |

3.3、λG 程序长什么样?
用前面的嵌套循环举例,λG 表示如下(已添加注释):
|
|
注意这个结构的特点:所有函数都平等地放在同一层(flat map),没有显式的嵌套关系。就像一锅汤里漂着各种食材,函数之间的关系完全通过"谁调用了谁"和"谁用了谁的变量"来体现——这就是论文所说的 “函数汤”(soup of functions) 的概念。

3.4、自由变量是什么?直观理解
对于函数汤里的任意一个函数,它的自由变量就是:函数体里用到的、但不是自己的参数的那些变量。
拿 bi 举例:
|
|
bi自己的参数:空([],没有参数)bi函数体里用到的变量:hj(函数名也是变量)和i- 因此
bi的自由变量 ={hj, i}
再看 hj:
|
|
hj自己绑定的变量:var_hj(即参数j),以及局部变量j2- 函数体里用到的其他变量:
n(来自最外层的f),bj,xj - 因此
hj的自由变量 ={n, bj, xj}
关键:hj 的自由变量里没有 i! 这正是我们在第二节里观察到的:内层循环不依赖外层循环变量 i。
用公式表达(FV 是 free variables 缩写):
$$FV(\ell) = \text{函数体中出现的所有变量} \setminus {\text{函数}\ell\text{自身绑定的变量}}$$
4、关键机制:高效地维护自由变量
4.1、为什么维护是难题?
编译器的优化 Pass 会反复改动程序——内联一个函数、删除一个参数、改写一个条件分支……每改动一处,相关函数的自由变量集合就可能变化。
最朴素的做法是"每次改动后,对整个程序重新计算一遍自由变量"。但对于百万行代码规模的程序,这代价太高了。
4.2、懒计算 + 缓存 + 局部失效
论文的解决方案思路类似浏览器缓存:
- 懒计算(Lazy Evaluation):不主动计算,等到"有人问起"时再算。
- 结果缓存(Caching):算出来之后存下来,下次直接用。
- 局部失效(Local Invalidation):改动某个函数
ℓ时,不清空整个缓存——只把依赖ℓ的那些函数标记为"缓存失效"。
具体来说,每个函数维护三样东西:
|
|
举个具体例子:假设函数 bi 被修改了,而 f 依赖 bi 的自由变量。那么只有 f(以及所有依赖 f 的函数)需要重新计算,与 bi 无关的函数完全不受影响。
4.3、处理循环依赖(递归):不动点迭代
上面的方案有一个漏洞:递归函数会造成循环依赖——hj 的自由变量依赖 bj,而 bj 的自由变量依赖 hj。如果只是顺着依赖链往下走,会陷入无限循环。
解决方案是不动点迭代:反复计算,直到自由变量集合不再变化(“不动了”)。
论文用一个全局计数器 run 来控制这个过程。每个函数的 mark 的含义如下:
mark 的值 |
含义 |
|---|---|
0 |
缓存已失效,需要重新计算 |
run - 1 |
上一轮迭代的结果,可能还不完整 |
run |
本轮已在计算中(检测到环路,先返回当前结果) |
| 其他值 | 缓存完全有效,直接返回 |
关键设计:当检测到环路(mark = run)时,不报错,而是返回当前已知的部分结果。下一轮迭代会把遗漏的变量补上,直到两轮之间的结果完全相同——这就是"不动点"。
对于没有循环依赖的程序,一轮迭代就能收敛。有递归时,最多需要迭代 d(G) + 2 次,其中 d(G) 是程序中循环嵌套的"深度"(技术上称为循环连通度)。
为什么这比传统方法好? 传统 LLVM 每当程序被修改,就要重新计算整棵支配树——这是一个全局操作。而本文的方案只局部失效受影响的缓存,对大型程序的增量编译非常友好。
5、嵌套关系与嵌套树
5.1、从自由变量推断"谁属于谁"
有了自由变量,我们可以定义一种函数间的从属关系:
如果函数
ℓ2的自由变量中包含了函数ℓ1的参数变量(记作var_ℓ1),那就说ℓ1嵌套ℓ2,写作 $\ell_1 \succ \ell_2$。
直白地说:"ℓ2 需要用 ℓ1 提供的东西,所以 ℓ2 在某种意义上’属于' ℓ1"。
这种嵌套关系具有传递性:如果 f 嵌套 g,g 嵌套 h,那么 f 也嵌套 h。把所有嵌套关系组织起来,就形成了嵌套树(Nesting Tree)。
5.2、嵌套树与支配树:一个对比
回到前面的嵌套循环例子,两种方法给出的树形结构有实质性的区别:
|
|
支配树说:hj(内层循环头)在 bi 的子树下——因为从程序入口到 hj,必须先经过 bi(控制流路径的要求)。
嵌套树说:hj 与 hi 平级,都是 f 的直接子节点——因为 hj 的自由变量是 {n, bj, xj},其中 n 来自 f 的绑定(let n = var_f.0),不包含 hi 的参数变量 i,所以 hj 根本不"属于" hi,而是直接挂在 f 下,与 hi 并列独立。
这个区别为什么重要? 当我们要展开外层循环时,只需要复制嵌套树中属于外层循环(hi)的那些函数。
- 支配树方案:
bi的整个子树都要复制,包括hj,bj,xj(3 个函数) - 嵌套树方案:只需复制
hi子树中的bi和xi(2 个函数);hj、bj、xj挂在f下而非hi下,与外层循环完全独立,两个展开副本可以共享同一份内层循环
5.3、核心定理:嵌套蕴含支配
论文证明了两种关系之间的严格包含:
定理:如果 $\ell_1 \succ \ell_2$(嵌套),那么在控制流图中,$\ell_1$ 也支配 $\ell_2$。
但反过来不成立:支配不一定嵌套。
用一句话概括:嵌套关系比支配关系更严格。 嵌套是真正的数据依赖,支配只是控制流路径上的先后关系——后者是前者的"粗糙近似"。这就是为什么嵌套树更精确:它排除了那些"控制流上有先后关系、但数据上没有依赖"的情况。
6、高阶函数的自然支持
6.1、什么是高阶函数,传统方法为什么卡壳?
高阶函数是指"接受函数作为参数"或"返回函数作为结果"的函数。在 Haskell、OCaml、Rust(闭包)、甚至现代 JavaScript 中,这是非常普通的写法。
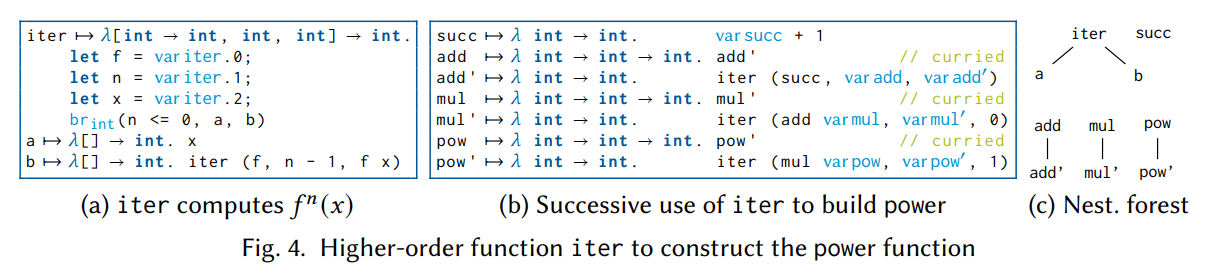
来看一个经典例子——用一个通用的"重复应用"函数构建算术运算:
|
|
这段代码在函数式语言中司空见惯,但对传统编译器来说是个难题:iter 接受函数 f 作为参数,而 f 到底是 succ、(add m) 还是 (mul m),在编译时不确定。传统 CFG 无法表达"函数是参数"这件事,必须先把这些高阶用法"降级"成低阶形式(通常通过闭包转换等技术),这个过程复杂且损失信息。
6.2、λG 如何自然处理?
在 λG 中,函数名和普通变量没有区别——它们都可以自由地出现在表达式里,传来传去。因此,iter 接受函数参数这件事,和接受整数参数没有任何区别。
更关键的是,嵌套树能从自由变量中自动推断出正确的依赖结构:
|
|
add的内部体自由变量包含m(来自add的参数),所以属于addmul的内部体传给iter的是(add m),其中m来自mul的参数,所以属于muliter、succ、add、mul、pow互相之间没有自由变量依赖,所以形成独立的"树"
整个分析完全不需要人工干预,也不需要先做任何降级变换。
这是本文最重要的贡献之一:第一阶程序和高阶程序在 λG 中是统一的,不存在"高阶是特殊情况"的问题。
7、β 归约:更聪明的函数内联
7.1、什么是函数内联?
函数内联(Inlining) 是一种常见优化:把一个函数调用替换为函数体本身,省去函数调用的开销。比如:
|
|
在 λG 中,内联就是做 β 归约——这是 lambda 演算中最基本的操作:把 (λx. 函数体) 参数值 替换为"函数体中所有 x 都被换成参数值"的结果。
7.2、传统内联为什么麻烦?
在 CFG 中内联一个函数,需要:
- 重新计算支配树(因为 CFG 结构变了)
- 找出所有可能受影响的基本块(遍历支配子树)
- 复制相关的块,并更新所有变量名和跳转目标
- 重新插入 φ 函数,重建 SSA 形式
这是一个涉及全局分析的操作,即使只内联一个小函数,也可能触发大规模的重建。
7.3、λG 的 β 归约为什么更快?
β 归约的核心问题是:内联一个函数时,哪些代码需要被复制?
答案其实很简单:只有包含了被替换变量的那些子表达式才需要复制。
而判断"哪个子表达式包含了变量 x"——正是自由变量集合直接回答的问题!
具体步骤:
- 要内联函数
f(把f的调用点替换为f的函数体) - 遍历程序中的每个子表达式
e - 如果
var_f ∉ FV(e):e与f无关,直接共享,不复制 - 如果
var_f ∈ FV(e):e依赖f,需要复制并在副本中做替换
不需要支配树,不需要全局预处理——自由变量集合就是所需的全部信息。这使得 β 归约在实践中通常比 LLVM 的内联更快。
8、η 展开:解决"一鱼两吃"的尴尬
8.1、问题场景:“已知函数"与"未知函数”
编译器对函数的优化能力,取决于它是否"认识"这个函数:
- 已知函数(known function):编译器知道这个函数只在哪几处被调用,可以做针对性的优化(比如删除调用者都不用的参数)
- 未知函数(unknown function):函数被作为参数传递,编译器不知道最终在哪里被调用,不能随意改变其接口
问题出现在:一个函数既被直接调用,又被当作参数传给别人。
|
|
对于 double 的第一种用法,编译器想做针对性优化;对于第二种用法,编译器必须保守。两种需求冲突了。
8.2、η 展开:把函数"分裂"成两个版本
解决方案是η 展开(eta expansion):为那个"被当作参数传递"的用法创建一个薄薄的包装函数:
|
|
现在 double 变成了"完全已知的函数"(只有直接调用),编译器可以放心地做各种优化(比如根据调用点特化版本、删除未使用参数等),完全不影响 double_η 那一路。
8.3、与 CFG 中"关键边消除"的对应
在传统编译器中,有一个类似的操作叫关键边消除(Critical Edge Splitting):当一条边的起点有多个后继、终点有多个前驱时,插入一个空的中间基本块,以便在这条边上插入优化代码而不影响其他路径。
η 展开就是 λG 中的等价操作,但更通用——它不只处理控制流中的"尴尬边",也处理数据流中的"一鱼两吃"问题。
9、高效数据结构:如何存储"自由变量集合"
9.1、问题:集合操作要快,也要省内存
自由变量集合需要支持这些操作:求并集(合并两个函数的自由变量)、查成员(某个变量是否自由)、求差集(去掉某个变量)。这些操作必须足够快,因为编译器每时每刻都在做。
此外,大量函数可能共享相同的子集(比如都用到了顶层的 n),如果每个函数各存一份,内存开销会爆炸。
9.2、三层实现策略:小集合用简单结构,大集合用复杂结构
| 集合大小 | 实现方式 | 为什么这样选 |
|---|---|---|
| 空集 | 空指针 | 零开销 |
| 单元素集合 | 直接指针(指向那个变量) | 零额外内存 |
| ≤ 16 个元素 | 哈希-共享有序数组 | 元素少时,数组比树更快(缓存友好) |
| > 16 个元素 | 索引字典树(Indexed Trie) | 天然支持前缀共享,节省内存 |
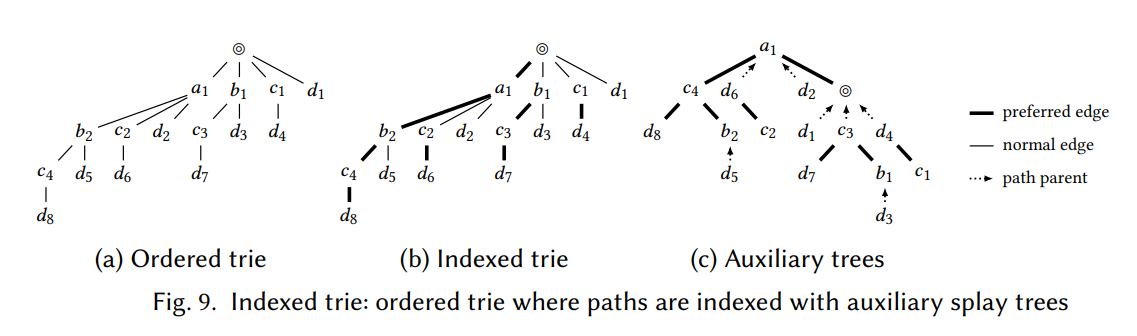
9.3、字典树:用"前缀共享"省内存
字典树(Trie) 是一种树形结构,其中从根到叶的路径代表一个"单词"(这里是变量的标识符编码)。相同前缀的"单词"共享同一段路径。
举个例子:集合 {n, bi, bj, xi} 和 {n, bi, bj} 在字典树中共享 n → bi → bj 这段前缀,只有 xi 那个分支不同。这意味着两个集合可以共享大量内存,而不是各存一份。
|
|
9.4、伸展树加速路径操作
字典树有个问题:沿着一条很长的路径走下去,每步都要做一次指针解引用,对 CPU 缓存很不友好。
论文在字典树上额外叠加了一层伸展树(Splay Tree)索引,思路类似于算法竞赛中的"链切树(Link-Cut Tree)":
- 把字典树的路径切分成若干段"偏好路径"
- 每段偏好路径用一棵伸展树来表示(伸展树是一种自调整的 BST,最近访问的节点会被旋转到靠近根部,利用时间局部性)
- 查询/插入/删除的均摊复杂度为 $O(\log n)$
- 两个集合求交集:均摊 $O(\log n + \log m)$(利用字典树的结构跳过大段无关的元素)
这套数据结构设计的核心目标是:在大量自由变量集合共享结构的场景下,尽可能减少内存分配和拷贝开销。
10、实验结果
论文在 MimIR 框架(一个实验性编译器基础设施,由同一研究组开发)中实现了所有算法,并与 LLVM 的对应操作进行了性能对比。
10.1、三种测试场景
为了覆盖不同的自由变量复杂度,论文设计了三个合成基准:
-
循环级联(Loop Cascade):
n个串行循环,每个循环的变量依赖前一个循环——这是常规情况,自由变量集合不大。 -
累积循环级联(Accumulating Loop Cascade):同上,但所有中间变量都"活"到程序结束——这是自由变量集合最大的情况,压力测试集合操作。
-
循环嵌套(Loop Nest):
n个层层嵌套的循环——这是最坏情况,每增加一层嵌套,自由变量集合就要做一次"叠加"。
10.2、性能结论一览
| 操作 | 实际复杂度 | 与 LLVM 的对比 |
|---|---|---|
| 自由变量初始计算(非深嵌套) | $O(n \log n)$ | LLVM 支配分析约快 5 倍,但本文方法支持高阶、且支持增量更新 |
| β 归约(函数内联) | $O(n \log n)$ | MimIR 通常更快 |
| 嵌套树构建 | $O(n \log n)$ | 无直接对比 |
| 深层循环嵌套(Loop Nest) | $O(n^3 \log^3 n)$ | 最坏情况,实际程序中很少出现 |
一个具体数字:含超过 100 万个循环(约 300 万个函数)的程序,计算自由变量不超过 4 秒。
11、与相关工作的对比
| 系统/概念 | 与本文的关系 |
|---|---|
| LLVM/MLIR | 依赖支配树,每次 CFG 变化需全局重建;高阶函数必须先降级处理 |
| Thorin/MimIR(旧版) | 有"函数汤"的概念,但仍在函数汤上叠加 CFG 来计算支配关系,本文彻底移除了这一依赖 |
| Guile CPS soup | 同样是扁平化的函数映射,但仍用 CFG 计算支配,且不直接支持非 CPS 风格 |
| Kennedy 的 CPS IR | 使用显式词法作用域(嵌套结构),自由变量计算需要全局重分析,且需要"块浮升"操作 |
| DJ-Graph | 控制流分析中的 join-edge 与本文的"兄弟依赖"概念相似,但前者是控制流关系,后者是数据流关系 |
12、核心贡献一览
本文提出的新理论体系,其实是对传统 SSA/CFG 工具箱的一次系统性"翻译"——用基于数据流的概念替换基于控制流的对应物:
| 传统 SSA/CFG 概念 | λG 对应概念 | 替换的意义 |
|---|---|---|
| SSA 支配属性 | 良构性(Well-Formedness) | 等价的安全性保证,但不依赖 CFG |
| 支配关系 | 自由变量 | 精确的数据依赖,取代粗糙的控制流先后关系 |
| 支配树 | 嵌套树 | 更精确的层级结构,支持高阶函数 |
| DJ-图 | 带兄弟依赖的调用图 | 数据流版本的连接图 |
| 循环树 | 带 SCC 的调用图 | 递归结构对应控制流中的循环 |
| 直接递归自然循环 | 直接递归 | 一一对应 |
| 互递归不可归约循环 | 互递归 | 一一对应 |
| 关键边消除 | η 展开 | 解决"函数多重使用"的冲突 |
13、总结与意义
这篇论文的核心信息是:
控制流不应是编译器分析的第一公民。数据依赖(自由变量)才是程序结构更本质的表达。
具体来说,本文做到了:
-
更精确的分析:基于自由变量的嵌套树比基于控制流的支配树更精确,避免了对无关代码的过度处理(如内层循环不依赖外层变量,就不应被视为外层循环的一部分)。
-
自然支持高阶函数:λG 统一了第一阶和高阶程序,高阶函数不再是需要特殊降级处理的"异类"。
-
增量更新:通过懒计算和局部缓存失效机制,编译器对程序的修改只需局部重新分析,而非全局重建支配树——这对增量编译和 IDE 实时分析尤其重要。
-
工程可行:所有算法和数据结构都在 MimIR 中实现,性能在现实工作负载下与 LLVM 相当甚至更优。
-
完备的理论保障:所有引理和定理都用 Lean 证明助手进行了形式化验证——不仅声称正确,而且机器验证了正确。
14、批判性思考:这篇论文的问题与局限
读完这篇论文,我认为它的学术价值是真实的——把自由变量提升为编译器的第一公民,配上完整的形式化理论和工程实现,这是一项扎实的工作。但学术论文不是产品说明书,以下几个问题值得认真对待。
14.1 与 LLVM 的对比:有多公平?
论文花了相当篇幅与 LLVM 做性能对比,但这个对比存在根本性的不对等:MimIR 支持高阶函数、多态类型、依赖类型、插件系统……这些特性使得 MimIR 的 IR 本身更"重",遍历成本更高。
更关键的是:LLVM 的内联操作之所以相对慢,部分原因是它会顺便执行大量安全检查和附加优化(比如 instcombine 指令化简)。论文把这些步骤单独剥离统计后,差距其实明显缩小了。
一个真正公平的对比应该是:在等价的表达能力和等价的安全约束下,两者的性能如何?
14.2 最坏情况:深层嵌套的幽灵
深层循环嵌套场景下,自由变量计算的复杂度达到 $O(n^3 \log^3 n)$。论文用"SPEC2006 实际程序最深嵌套只有 22 层"来打消顾虑。
但这个论证只对现有代码库成立,对未来代码未必如此:
- 着色器编译领域大量使用自动生成的代码,嵌套结构可以非常深
- 元编程和宏展开后的代码可能产生人工难以预料的结构
- 随着函数式风格在主流语言中的普及,深层嵌套的场景可能越来越常见
“现在很少见"不等于"以后也很少见”。这是一个需要持续观察的开放风险。
14.3 “先有鸡还是先有蛋”:构建 SSA 本身仍需支配关系
论文在相关工作一节悄悄承认了一个关键局限:
“dominance remains valuable in some contexts (e.g., classical SSA construction before SSA variables exist)”
也就是说,本文替换的是"SSA 程序内部的分析"中对支配关系的依赖——但把源程序转换为 SSA 形式这一步,经典算法(Cytron 1991)仍然依赖支配关系。
因此,本文描述的其实是"从已有 SSA 出发,做更好的分析",而不是"从头构建 SSA 都不需要支配关系"。前者是真实贡献,但比标题所暗示的更有限。(论文提到正在研究基于 Lemerre 工作的完整高阶 SSA 构造,但目前仍是开放问题。)
14.4 失效传播的最坏情况未被分析
论文的缓存失效机制优雅,但存在一个未被分析的最坏情况:
假设有一个被程序中几乎所有函数引用的"全局工具函数"(比如一个基础算术操作或内存分配函数)。每次修改这个函数,都会触发几乎整个程序缓存的递归失效——这等同于每次全局重新分析。
频繁修改此类"高连通度"函数的编译 Pass(比如常量传播)会不会导致性能退化?这不是纯理论问题:在工业级编译器中,这类场景并不罕见。
14.5 伸展树的均摊保证:对实时场景够用吗?
论文使用伸展树提供均摊 $O(\log n)$ 的操作,这意味着大多数时候很快,但偶尔会有一次 $O(n)$ 的慢操作(在伸展树内部做旋转重整)。
对于离线批量编译,偶发的延迟尖峰可以接受。但对于IDE 的实时代码分析或增量编译中的即时反馈,延迟的可预测性同样重要。红黑树或 B 树能提供最坏情况 $O(\log n)$ 的保证,但论文选择了伸展树而没有讨论这个权衡的适用边界。
14.6 并行编译:一个被忽视的维度
所有实验都是单线程的。但现代编译器(特别是大型代码库的编译器,如 Rust 的 rustc)越来越多地利用并行化。
论文的 mark 方案依赖一个全局递增计数器 run。在并发环境中,多个线程同时修改不同函数并触发缓存失效,会引发数据竞争。这不是不可解决的问题,但解决它需要引入锁、原子操作或分区隔离——整个框架的设计复杂度会显著提高。
对于想在工业级编译器中采用此方案的工程师来说,这是一个不容忽视的实现挑战。
14.7 “函数汤"的可调试性问题
传统词法作用域(显式嵌套结构)有一个实用价值:编译器工程师可以直接阅读和理解 IR,变量的作用域一目了然。
在"函数汤"里,所有函数平铺展开,你需要手动计算自由变量才能知道"这个变量对那个函数可见吗”。当优化 Pass 产生错误结果时,调试难度会更高:
- 如何直观地判断自由变量计算出了什么问题?
- 调试器和 IR 可视化工具如何适配?
- 编译工程师的心智模型从"树状嵌套"切换到"汤+隐式结构",学习成本有多高?
论文提出嵌套树作为可视化辅助,但嵌套树本身需要额外构建,不是 IR 的一等组成部分。
14.8 一个更深的哲学问题:精确性是否总是更好?
论文的核心主张是"自由变量比支配关系更精确"——这在静态分析的意义上是正确的。
但"精确"有时候是有代价的。支配关系之所以成为主流,部分原因是它提供了一种保守但边界清晰的抽象,让编译器的各个 Pass 可以独立推理,而不需要了解彼此的实现细节。
自由变量是全局性的:一个变量是否自由,取决于整个程序的结构。当你写一个新的优化 Pass 时,你需要更仔细地思考"我的变换会如何改变自由变量集合,这些变化会波及哪些函数"。
支配关系的"不精确"在某种程度上是有意为之的抽象边界,它让 Pass 的组合更安全、更可预测。放弃这个边界,换来了精确性,但也换来了更高的认知负担——这个权衡是否值得,最终取决于目标用例(函数式语言编译器?系统语言?通用框架?)。
14.9 总体评价
| 维度 | 评价 |
|---|---|
| 理论贡献 | ★★★★★ 形式化完整,Lean 验证,核心定理清晰 |
| 工程实现 | ★★★★☆ MimIR 是真实系统,但生态和工具链仍不成熟 |
| 实验评估 | ★★★☆☆ 合成基准说服力有限,与 LLVM 对比不够公平 |
| 实用性 | ★★★☆☆ 对函数式/高阶语言编译器有直接价值;对 C/C++/Java 类语言的迁移路径不清晰 |
| 长远影响 | ★★★★☆ 有望成为下一代高阶语言编译器的基础设施,但需要更多跟进工作 |
一句话总结:这是一篇提出了正确问题、给出了有力回答的论文。它描述的是一条通向未来的道路,而不是一张已经完成的地图。对函数式编译器社区的价值是显而易见的;能否动摇 LLVM 这类工业级基础设施,仍然是一个需要时间验证的开放问题。
参考
- MimIR 框架:https://mimir.github.io
- 论文代码/数据(Zenodo):doi:10.5281/zenodo.19069679
- 理解 CPS 的入门书:Appel《Compiling with Continuations》
- SSA 与函数式编程的等价性:Kelsey《A Correspondence between Continuation Passing Style and Static Single Assignment Form》
- 原始 SSA 构造算法(依赖支配关系):Cytron 等《Efficiently Computing Static Single Assignment Form and the Control Dependence Graph》(1991)
文章作者 calssion
上次更新 2026-06-01