Outline: 代码分离编译优化
文章目录
outline 可以作为优化代码体积的利器,大致可以优化 12%-37% 的大小,但也可能带来 2%-6% 的性能劣化,本文简单介绍一下这项优化技术。
1、Machine IR Outline
相比于 inline 是把代码内联内置展开到调用点从而优化性能;outline 则是把几段相同的指令串外联抽离封装成一个独立的块(通常是组织成一个新函数) 从而优化代码体积,减少了重复指令数。
那么问题就是如何找到这些最长重复指令序列了,大致的算法是这样的:我们给每一条指令映射为一个唯一标识(比如这里是一个单词),然后使用后缀树(suffix tree) 来进行搜索匹配,这样就能找出重复指令序列了。
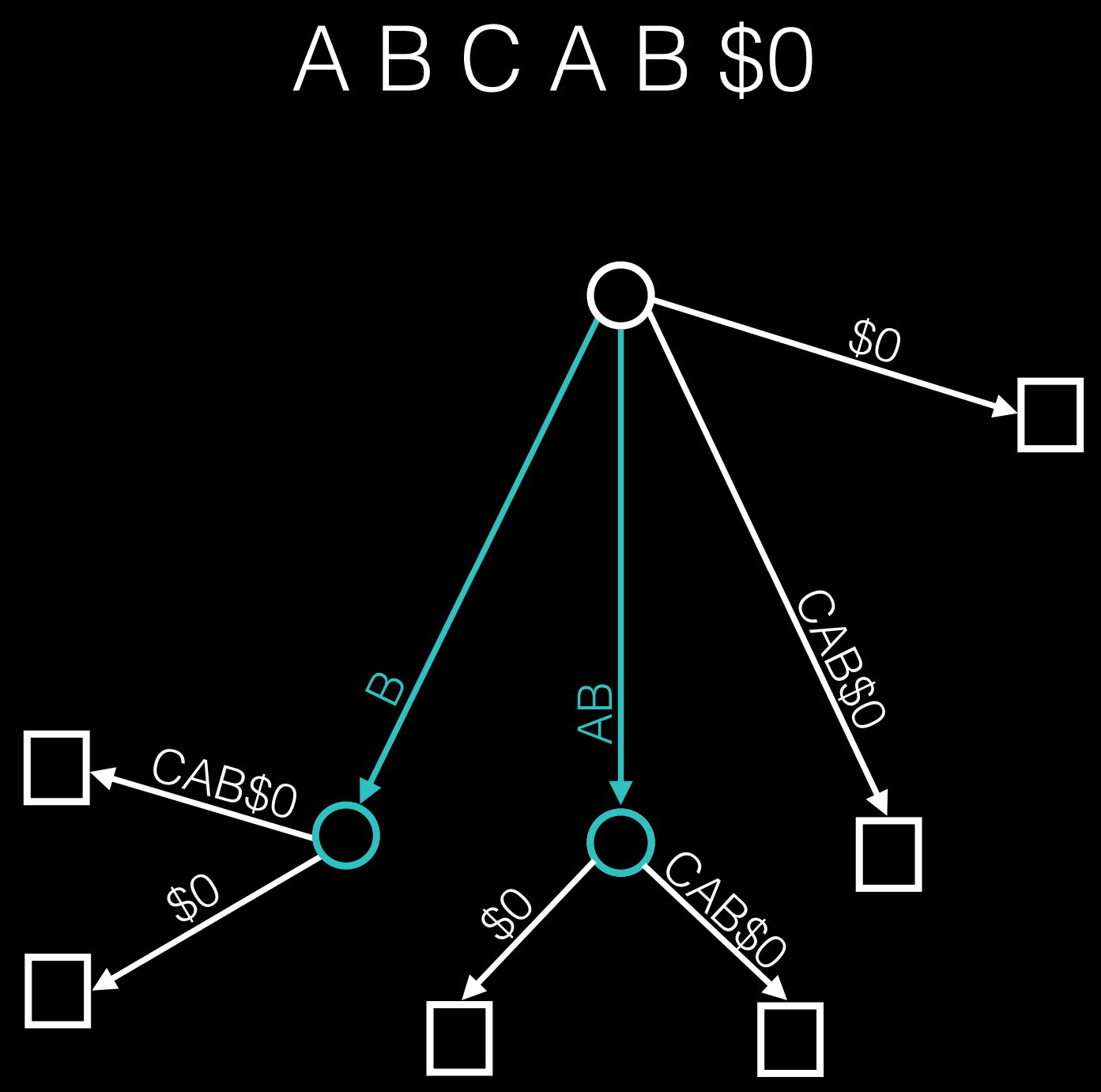
把不同的函数都拼接到一起,'$' 符号作为结尾,形成一个长串,然后作为输入给后缀树进行判别。
当然不是所有的指令都适合 outline,有些指令会比较危险。比如存在跳转指令的时候,外联后跳转位置就变了。比如在 arm 架构上,存在相对于当前 PC 值的相对地址跳转,可能就需要修正跳转的距离,也可能存在超出当前跳转指令支持的距离范围。
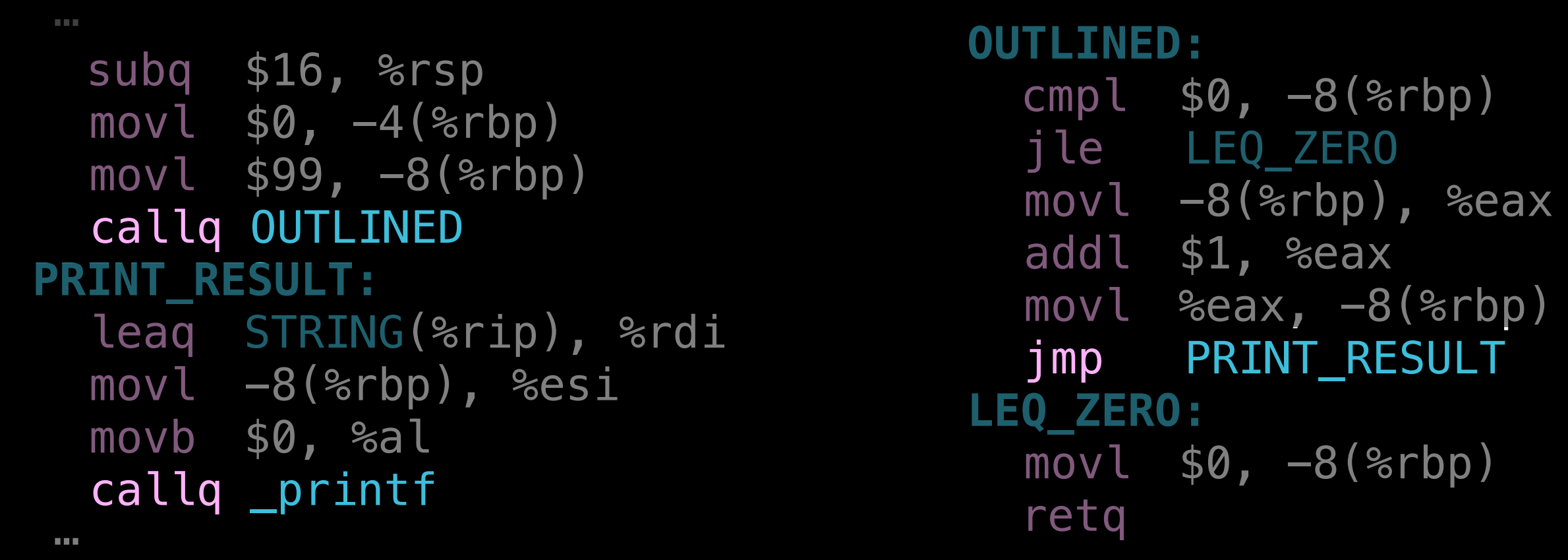
还有存在有条件跳转指令(conditional branch),比如下图的情况,callq 会将当前 PC 的下一条指令地址压入栈中,然后再去调用函数,执行完毕后在返回时 retq 再拿这个地址跳转回去继续执行。但因此也会破坏了栈结构,而下图的 outline 情况,条件判断指令 cmpl 将 $0 和栈中 -8 位置比较,就会出现问题。
1.1、-Oz
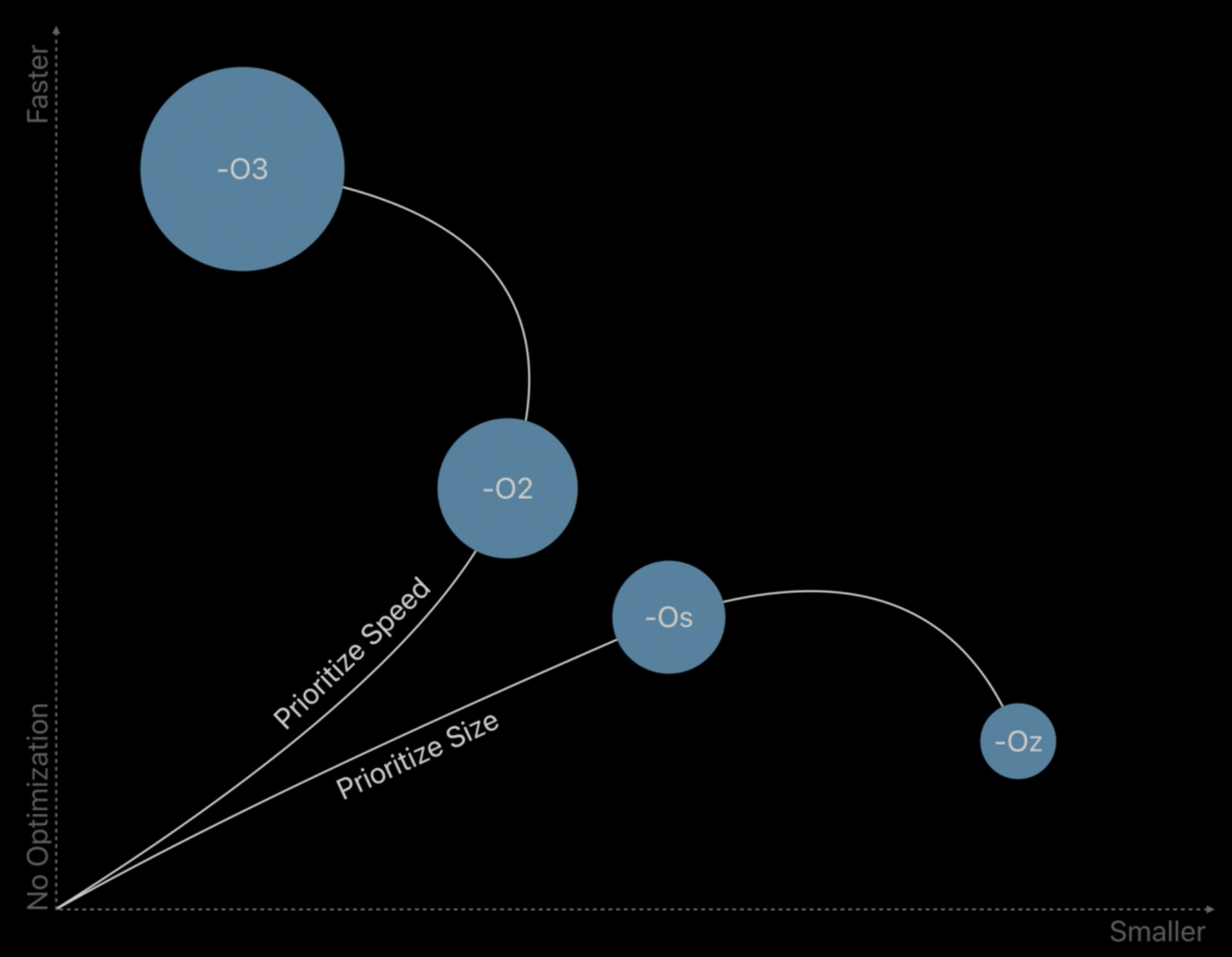
LLVM 新增的优化参数 -Oz 做的就是对 Machine 级别的 IR (更接近于机器码的一种 IR) 进行 outline 的操作,以达到减小代码体积的效果。
当然,有利有弊,虽然减小了代码体积,但会增加运行时间消耗(调用函数的消耗)。苹果 WWDC 里也有介绍这个参数,下面是给出的一张各个优化参数的大致对比图。 (纵坐标是运行效率,-O3 最快;横坐标是代码体积,-Oz 最小)
在 LLVM 中,除了设置 -Oz,也可以通过给 clang 传递 -mllvm -enable-machine-outliner 参数来开启。具体算法在这个文件里 llvm/lib/CodeGen/MachineOutliner.cpp。
1.2、repeated machine outlining
默认情况下,开启 machine outline,只会对代码进行一次的 outline 优化,而通过 -mllvm -machine-outliner-reruns=N 可以设置进行 N 轮的 outline 优化判断,一般而言 5 轮就差不多了。
这项优化可以在原本的优化基础上,带来 2%-3% 的体积减小收益。
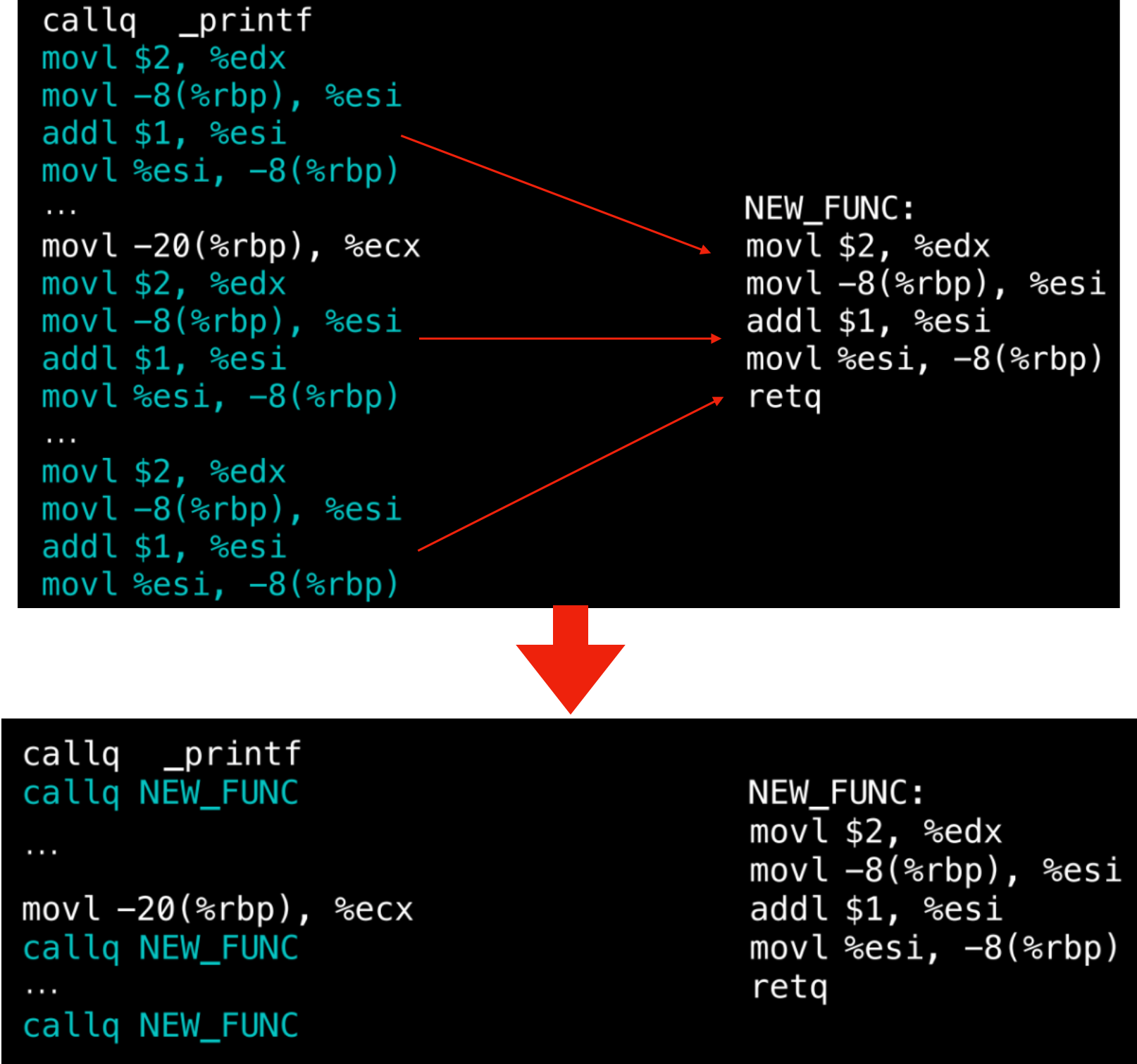
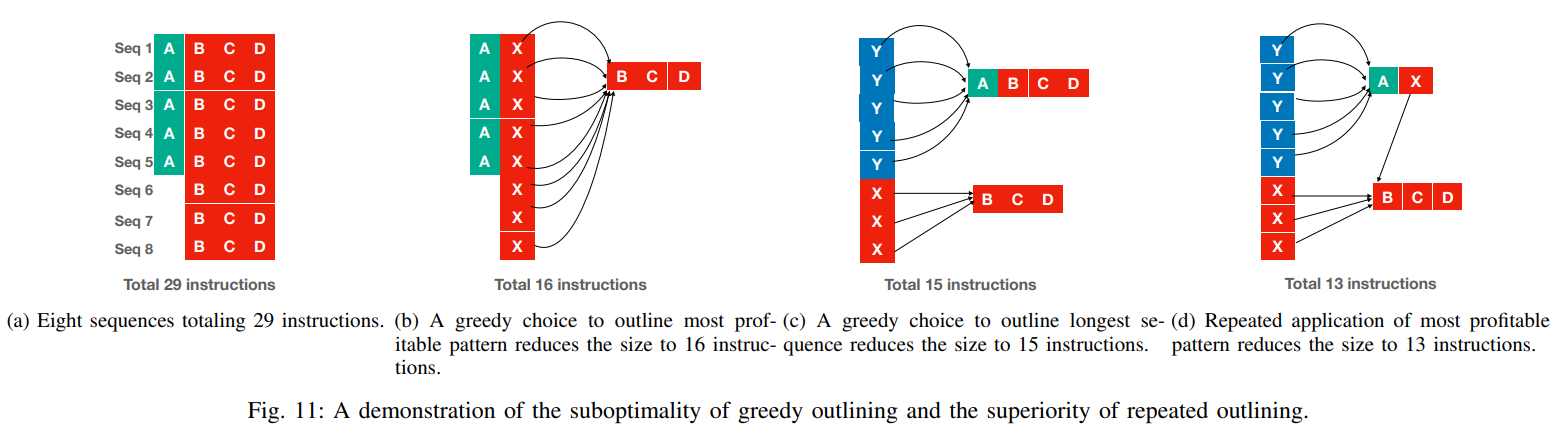
这个重复 outline 是什么意思?比如下图案例:

第一次 outline 的判断优化,把三个函数中的蓝框指令都识别 outline 出来了;到了第二次,发现调用 outline 函数的指令和其他指令也组成了新的重复串,就可以进行新一轮的 outline 优化了。
2、IR outline
Machine IR outline 是接近于机器码级别的指令优化,会有更多平台相关的 lowing 指令。那我们也可以从更高一级的 IR 来做 outline 优化,在这里可能也会存在一些重复的 IR 指令。可以有 1%-4.6% 左右的体积优化。
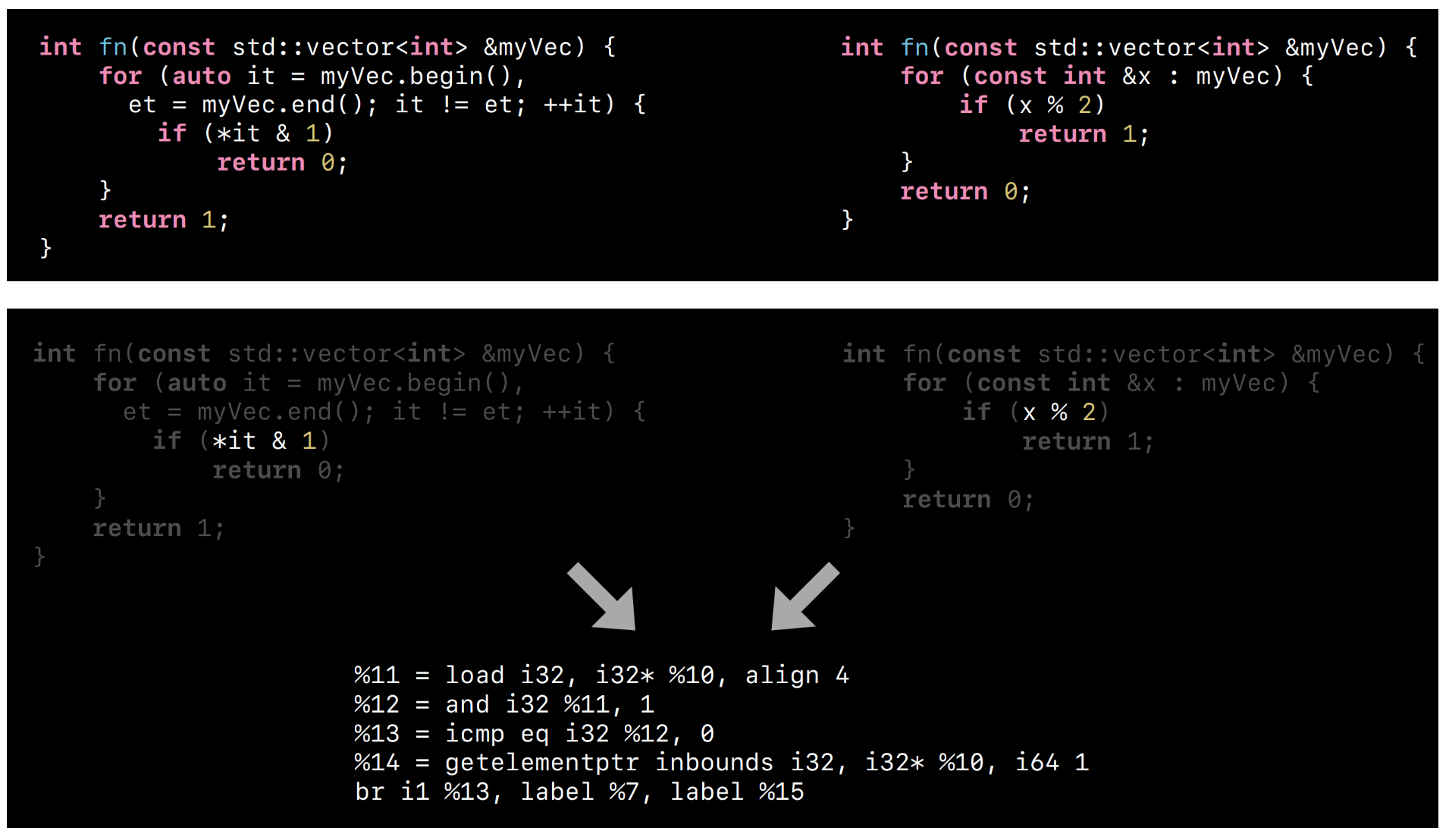
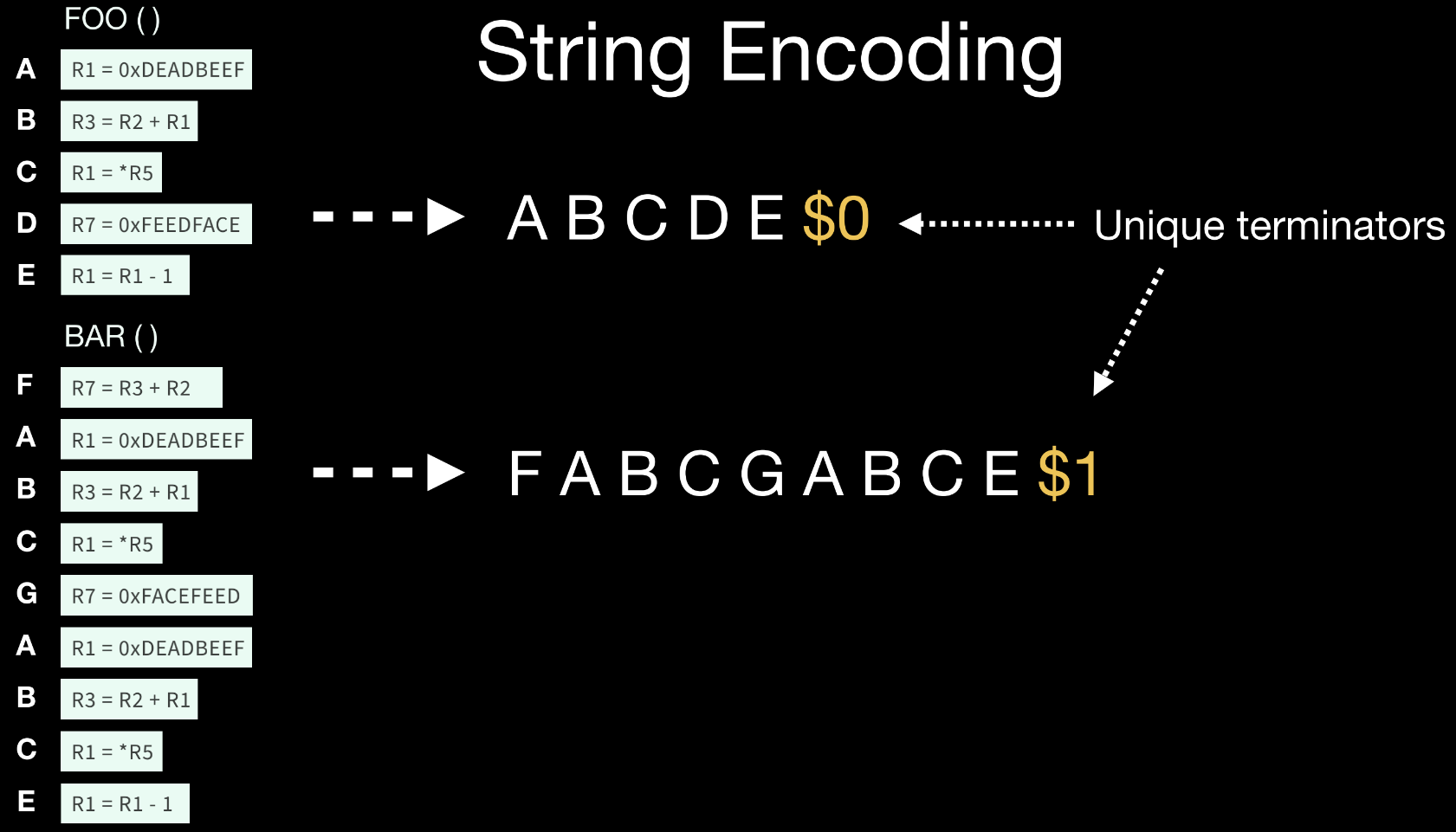
找出重复子串的方式还是使用后缀树来实现,但 IR 指令和 Machine IR 不太一样,因为 IR 指令抽象程度会高一些,与最终机器指令还会有一定的偏差。

在 IR 中,寄存器的数量是认为无限的,所以需要建立指令间的语义上的等价判断。

通过编译参数 -mllvm -ir-outliner=true 可以开启,具体算法实现在 lib/Transforms/IPO/IROutliner.cpp 文件中。
3、区别
IR outline 和 Machine IR outline 还是存在不少区别的,这里简单列其中一些对比(来源此文):
- Congruence Detection(一致性检测)。因为 MIR 已经直接是处理了寄存器分配的问题,所以只需要简单地判断两条指令是否相同即可。而 IR 需要的是语义层面上的相等,更关心操作符而不是操作数,这就需要我们做更多的验证。
|
|
- Occurrence Verification(事件校验)。MIR 不需要做额外的验证,因为不需要处理输入(输入,即指令的操作数)。而 IR 需要做复杂的验证,来确保候选指令有相同的输入。如果两个候选有不同的输入,我们需要用控制流来确保正确性。
- Cost Modeling(模型化消耗)。在 MIR 层面可以直接精确地计算指令开销;而在 IR 层面需要尝试匹配到 MIR 来计算开销。
- Parameterization Optimizations(参数化优化)。MIR 使用完全的相等,不需要判断参数。而 IR 需要处理参数,因为有一些优化可能会减少参数化序列的开销。
- Constant Folding(常量折叠)。在 IR 层面可以做到常量折叠。
- Congruent Input Condensing(相同输入压缩)。IR 语义上,如果一个函数的入参在每个调用点都一样,那么可以压缩成一个输入。比如下面的两个参数一样,可以转换成一个入参。
|
|
- Outlining(外联)。在 MIR 直接把重复指令外联为一个新的函数,创建必要的栈操作,生成对这个函数的调用就可以了。而在 IR 则还需要处理输出,合并涉及到的指令/函数的 metadata(元信息),还要识别对其调用的入参是否一致来做输入压缩操作。
参考
- 2016 LLVM Developers’ Meeting: J. Paquette “Reducing Code Size Using Outlining”
- Reducing Code Size Using Outlining
- 从汇编角度看待函数调用
- 2018 LLVM Developers’ Meeting: J. Paquette “What’s New In Outlining”
- Machine code layout optimizations.
- What’s New in Clang and LLVM
- [llvm-dev] [RFC] Interprocedural MIR-level outlining pass
- llvm/lib/CodeGen/MachineOutliner.cpp
- 2019 LLVM Developers’ Meeting: J. Lin “Link Time Optimization For Swift”
- Support repeated machine outlining
- How Uber Deals with Large iOS App Size
- An Experience with Code-Size Optimization for Production iOS Mobile Applications
- 2020 LLVM Developers’ Meeting: “Finding and Outlining Similarities in LLVM IR”
- Finding (and Outlining) Similarity at the IR Level
- lib/Transforms/IPO/IROutliner.cpp
- [llvm-dev] [RFC] PT.2 Add IR level interprocedural outliner for code size.
- [llvm-dev] [RFC] Add IR level interprocedural outliner for code size.
- [llvm-dev] [RFC] Framework for Finding and Using Similarity at the IR Level
文章作者 calssion
上次更新 2023-11-29