MLGO: 用强化学习为 LLVM 提供优化策略
文章目录
MLGO(Machine Learning Guided Compiler Optimization) 是使用机器学习技术,把 LLVM 中使用启发式(heuristics) 的优化转换成模型预测,对比 LLVM -Oz 优化有近 1.5~6% 的大小优化,性能有近 0.3~1.5% 提升。
这篇文章篇幅会较长,先列个提纲:
1、启发式(heuristics)
2、优化
3、inlining-for-size
4、inlining-for-size 实践
4.1、development 模式
4.1.1、生成
4.1.2、运用
4.2、release 模式
4.2.1、生成
4.2.2、运用
5、register-allocation-for-performance
1、启发式(heuristics)
目前大部分的优化 pass 都使用了启发式的优化,包括使用了运行时信息 profile 的 pass。启发式通常是基于一些基准测试和回归测试得到的人工组织的规则(策略、policy)。存在人工维护的成本,尤其是在维持一些语言特性和相互间的兼容性。
对于 inline 而言,编译器会模拟计算被调用函数(callee) 内联后的大小(cost),然后会用来和某个阈值(threshold、基于被调用函数的调用频率、内联关键字等设定) 做对比,根据这些信息决定是否 inline 的策略。
2、优化
目前 MLGO 框架支持了两种优化:
MLGO 为了不影响编译器本身的正确性和性能,所以从启发式优化策略下手,改变优化的执行过程,而非优化的具体实现。同时,让训练可以离线(offline) 进行,训练好的模型直接链接到编译器当中。
MLGO 主要使用了强化学习(reinforcement learning、RL) 里的 Policy Gradient 或 Evolution Strategies 来进行模型训练。使用强化学习主要是因为:
- 是否使用启发式对于优化效果而言是未知的。比如不清楚 inline 某个调用函数是否是最优的策略。
- 强化学习可以有效地探索不同的策略,并在过程中不断优化。
缺乏 label(数据预处理、数据标注) 使得监督学习(supervised learning) 难以实现,而强化学习可以从尝试和错误中进行自我迭代。
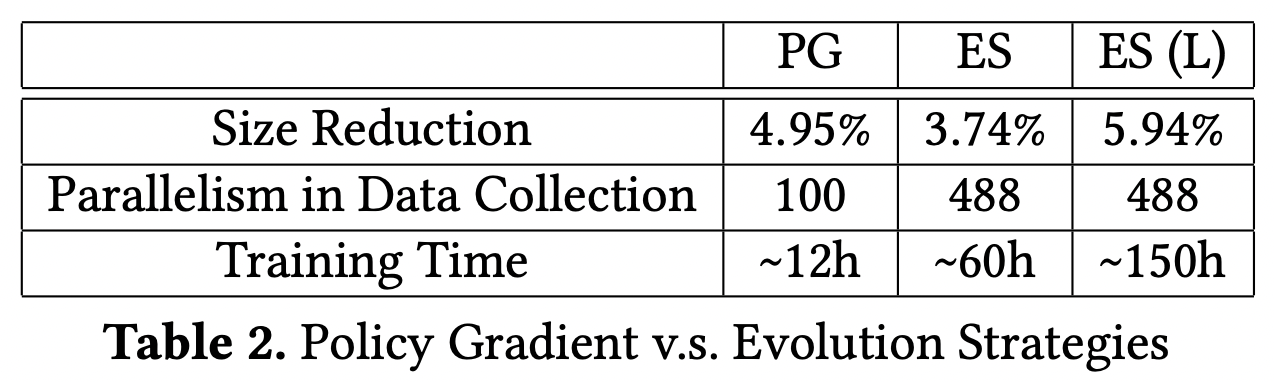
3、inlining-for-size
作为 MLGO 落地的第一个点,就是大小,因为大小是比较容易测量的,且干扰因素不多。
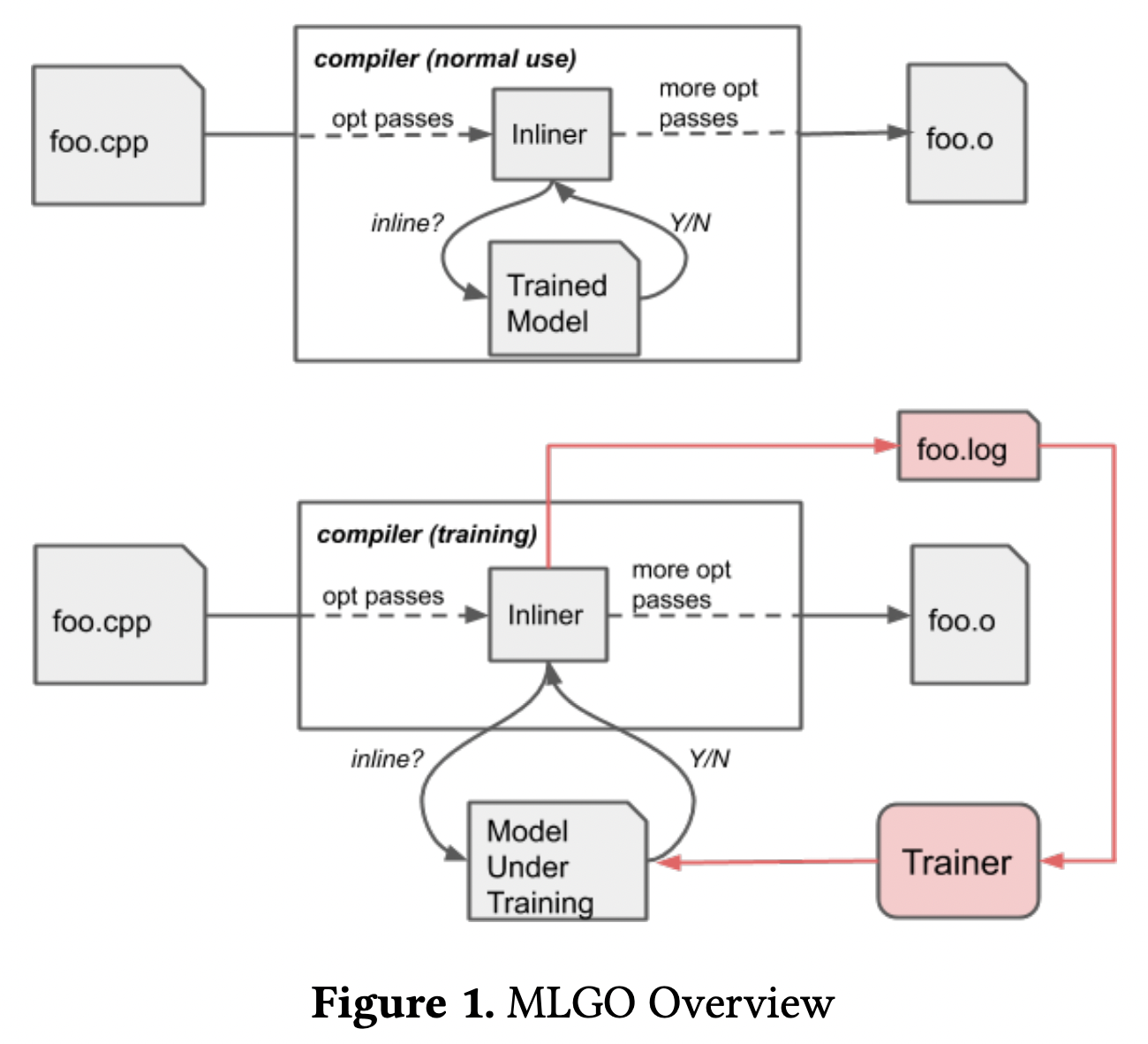
MLGO 的使用和训练是不一样的。使用时会把训练好的模型嵌入到编译器当中,来做 inline 的预测判断;训练时因为策略会一直更新,所以模型是分开的,期间 inliner 会生成相关的特征和决策记录,然后给算法用来生成新的模型(参数调优)。
MLGO 把 inlining-for-size 问题转换成 MDP(Markov Decision Process、指具有马尔可夫性质的随机过程,随机过程的研究对象是随时间演变的随机现象,当且仅当某时刻的状态只取决于上一时刻的状态时,一个随机过程被称为具有马尔可夫性质)。状态为当前的 call graph 和正在遍历的调用点(call site)。这里的状态转换是确定的,当决定是否 inline,编译器就决定了下一个状态(更新 call graph 和决定遍历的下一个调用点)。设置的奖励(reward)是如果不 inline 则为 0;如果 inline 则为调用函数(caller)的大小变化加上被调用函数(callee)的大小。
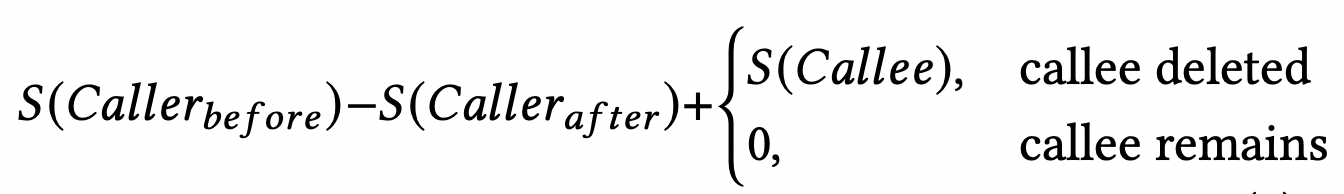
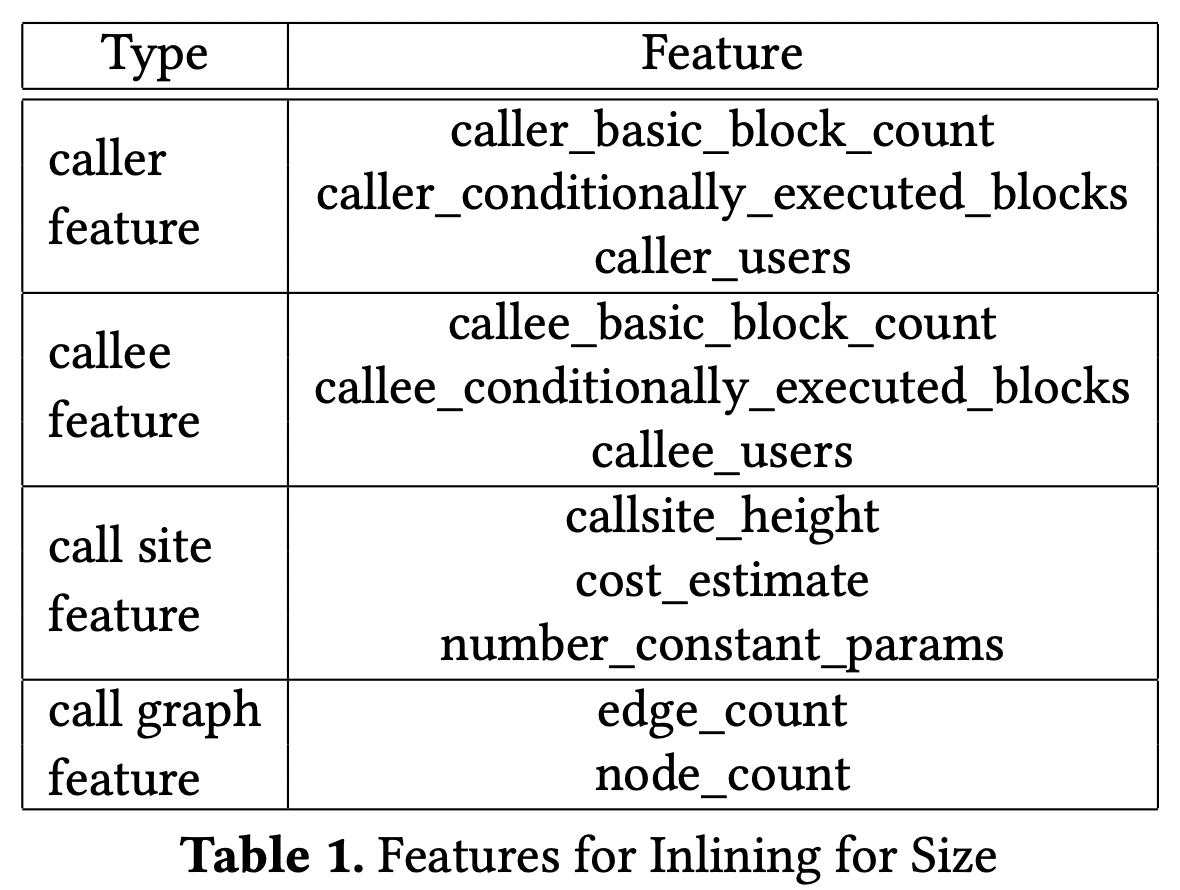
算法部分就不展开了(我也不太懂!)。其中有两个问题,一个是这样定义状态很难在每一次决策对整个 call graph 进行编码和处理,解决方式是用 11 个数值特征来近似代表状态,弊端是有效信息会变少了,如下:
另一个问题是在执行 inlining pass 时很难知道函数的机器码大小,因为后续的 pass 才开始生成机器码,解决方式是不用统计单个函数的变化,而是统计整体的 module 的,基准可以用启发式优化的结果。弊端是可能需要收集更多的数据、模型效果可能会变差。
4、inlining-for-size 实践
对于直接使用模型而言,采用的是 release 模式;而对于想要训练模型而言,采用的是 development 模式。opt 的编译参数是 -enable-ml-inliner=<argv>,默认是 default,即采用启发式优化。
|
|
但并不是指定了编译参数就能使用,因为关键逻辑里有宏在控制,而这些宏是需要在 cmake 生成 llvm 编译配置时去指定的,否则不会执行任何的操作。
|
|
可以看到是 LLVM_HAVE_TF_API 控制 development 模式,而 LLVM_HAVE_TF_AOT 控制 release 模式。因为模型训练或者把训练好的模型嵌入到编译器中,都是需要重新生成 LLVM 工具链的,所以实际上这两个宏是指明 cmake 需要添加的参数或依赖。如何看实际运行有没有生效,看这里面有 debug 输出,可以用 -mllvm -debug-only="inline" 来看对应开启的模式。
MLGO 使用的依赖是 TensorFlow 来进行模型的训练和推断。
4.1、development 模式
4.1.1、生成
development 模式通过命令行参数获取加载模型,但还需要一些运行时的依赖,因为模型评估可能会改变编译器的运行时行为,可能通过多线程或 JIT 的方式。
|
|
这种模式需要有 TENSORFLOW_C_LIB_PATH 指明 tensorflow 的 c 库(下载链接)依赖路径,从而使得 LLVM_HAVE_TF_API 宏可以被定义。另外由于使用了 c++17 的 optional,所以也需要指明编译使用的 c++ 版本。
|
|
如果遇到 tensorflow 的引入问题如 TypeError: register_loss_scale_wrapper() takes 2 positional arguments but 3 were given,重新安装无法解决的话,可以暴力一点直接在源文件替换掉这个函数的实现,因为可能是 pip 的包没及时更新同步官方的代码导致出现不一致。
4.1.2、运用
首先需要生成一个基础模型提供后续的训练持续使用迭代:
|
|
在使用时还需要 -training-log 指定训练的 log 输出的位置和 -ml-inliner-model-under-training 指定模型存放的位置,-tfutils-text-log 参数是输出可读的格式,因为是优化,所以也需要随便指定一个优化级别。
|
|
这里还可以用参数 -ml-inliner-ir2native-model=<./llvm/unittests/Analysis/Inputs/ir2native_x86_64_model> 添加一个额外的模型 IR2Native,用来从函数的 IR 来估算其机器码大小。这个模型是基于监督学习训练得来的,在 llvm/lib/Analysis/InlineSizeEstimatorAnalysis.cpp 可以看到具体实现。由于其结果 noise(噪声、离群点、异常值) 较多,只用在训练阶段。
4.2、release 模式
4.2.1、生成
release 模式把模型编码成 TensorFlow 的序列化格式,然后会被 saved_model_cli 工具(这个工具在 python 的 bin 目录下,TensorFlow’s XLA native compiler) 编译进 LLVM 的机器码中,具体逻辑在 llvm/cmake/modules/TensorFlowCompile.cmake 当中。即会把训练好的模型,编译成一个静态库和一个头文件供使用。
这里使用的是 tfcompile,是一个可将 TensorFlow 计算图提前 (AOT) 编译为可执行代码的独立工具。由 tfcompile 生成的可执行代码不会使用 TensorFlow 运行时,而仅仅依赖于计算实际使用的内核。编译器基于 XLA (加速线性代数,它会将 TensorFlow 图编译成一系列专门为给定模型生成的计算内核)框架构建。tensorflow/compiler 下提供了用于将 TensorFlow 桥接到 XLA 框架的代码。
谷歌已经有训练好的模型供使用,没有足够的资源和精力的话,直接利用成果就好了。SavedModel 格式包含一个完整的 TensorFlow 程序——不仅包含权重值,还包含计算;是一个包含序列化签名和运行这些签名所需的状态的目录,其中包括变量值和词汇表。
|
|
这种模式需要有 TENSORFLOW_AOT_PATH 指明 tensorflow 的 pip 安装路径,从而使得 LLVM_HAVE_TF_AOT 宏可以被定义。如果没有使用 LLVM_INLINER_MODEL_PATH 指定使用模型的路径,那么会自动生成一个模型以作使用。
|
|
在 TENSORFLOW_AOT_PATH 中还会用到 xla_aot_runtime_src 路径下的 CMakeLists.txt 来生成 lib/libtf_xla_runtime.a。这个 CMakeLists.txt 实际上 tensorflow 官方已经不维护了,因为官方构建 tensorflow 都采用 bazel 工具。如果遇到问题,可以考虑自己源码构建 tensorflow,然后修改 CMakeLists.txt 链接缺失的库即可。另外,LLVM 也已经支持从 bazel 构建了。
4.2.2、运用
使用就比较方便了。可以直接通过参数控制开启。
|
|
同样可以通过 -mllvm -debug-only="inline" 看输出的 debug 信息。
|
|
5、register-allocation-for-performance
MLGO 踏足的第二个领域是寄存器分配策略,寄存器分配解决的是给 live range(存活数据,还处于生命周期中的数据,通常是变量) 分配使用寄存器的问题。在代码执行过程中,不同的 live range 的生命周期会不一致,如何释放和分配有限的寄存器对性能的影响会较大。目标是改进回收寄存器的策略,以更好地提供给其他 live range 使用。
这个目前在 LLVM 中还没实现完整,可以从 MR 中了解其进展。
这部分并没有放出更多的资料,也是使用了强化学习来进行模型的训练。可以先从合入了 LLVM 当中的源码先看看,与 inlining-for-size 一样,也区分了 default、development、release 三种模式。release 模式通过 LLVM_RAEVICT_MODEL_PATH 把模型编译进编译器当中。
|
|
同样有宏在控制特定模式的开启,不过跟 inlining-for-size 使用的是一致的宏。
|
|
参考
- github ml-compiler-opt
- MLGO 论文
- inlining-for-size
- register-allocation-for-performance
- Policy Gradient
- Evolution Strategies
- Markov Decision Process
- MLGO: A Machine Learning Framework for Compiler Optimization
- tfcompile AOT 编译
- XLA:优化机器学习编译器
- 使用 SavedModel 格式
- xla_build CMakeLists.txt - multi platforms #38437
- cmake引用静态或动态库(四)
- github tensorflow
- 源代码构建 tensorflow
- [llvm-dev] RFC: a practical mechanism for applying Machine Learning for optimization policies in LLVM
- [llvm-dev] [RFC] MLGO Regalloc: learned eviction policy for regalloc
- [NFC][regalloc] Factor eviction decision-making into an analysis
- 2023 llvm mlgo workshop
文章作者 calssion
上次更新 2022-07-17