IRPGO 扩展: 兼顾性能和体积的 PGO 方式
文章目录
接上篇文章,传统 PGO 主要优化目标是性能,但经常会牺牲掉包体积大小,这里引入一种兼顾大小和性能的方式。本文内容来源另一篇论文 《Efficient Profile-Guided Size Optimization for Native Mobile Applications》。
1、MIP
MIP(Machine IR Profile),在 machine IR(MIR,注意 MIR 与最终机器码是不一样的) 层进行的轻量级插桩,抽取了静态元数据(static metadata,实际上像函数名字、函数指针和 profile 数据指针这些内容,在运行时是并不需要的,但去掉需要解决一致性问题),减少了 2/3 的体积消耗,而且它采集的 profile 数据与移动设备的空间优化更相关。 当然,它也有着更少的运行时开销(在 MIR 进行操作,更关注指令数的影响)。
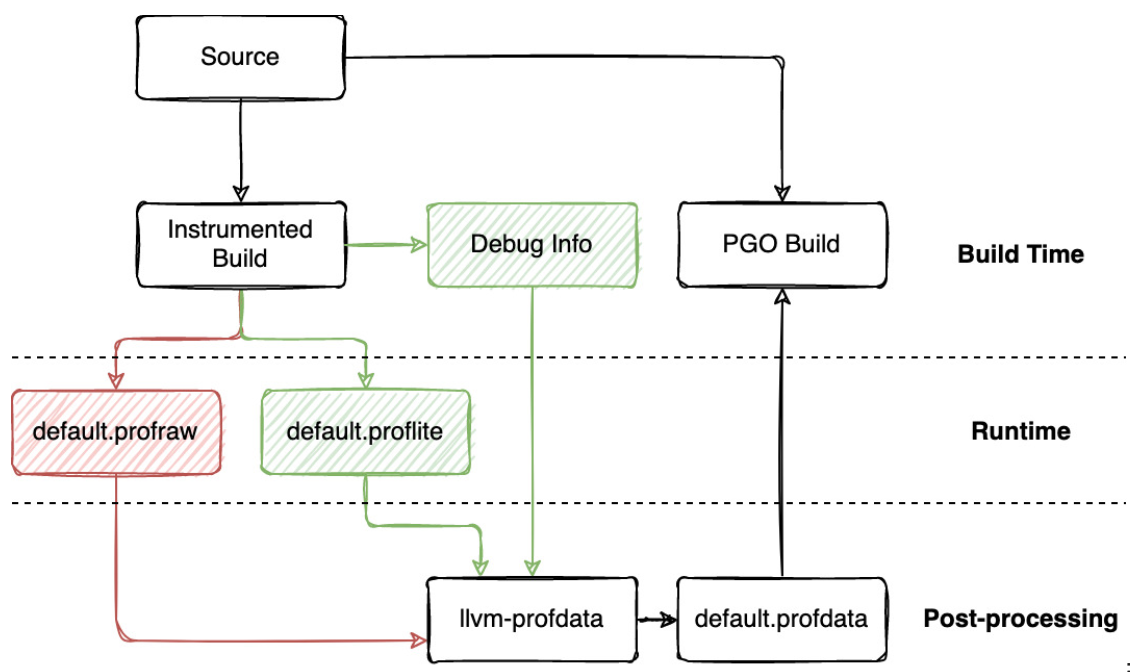

在 IR 层面上的 PGO,会协助函数 inline 的优化。而 MIR 层面的 PGO,会协助函数布局(function ordering) 和 machine outlining 的优化。(本文下面会介绍 outline 的概念)
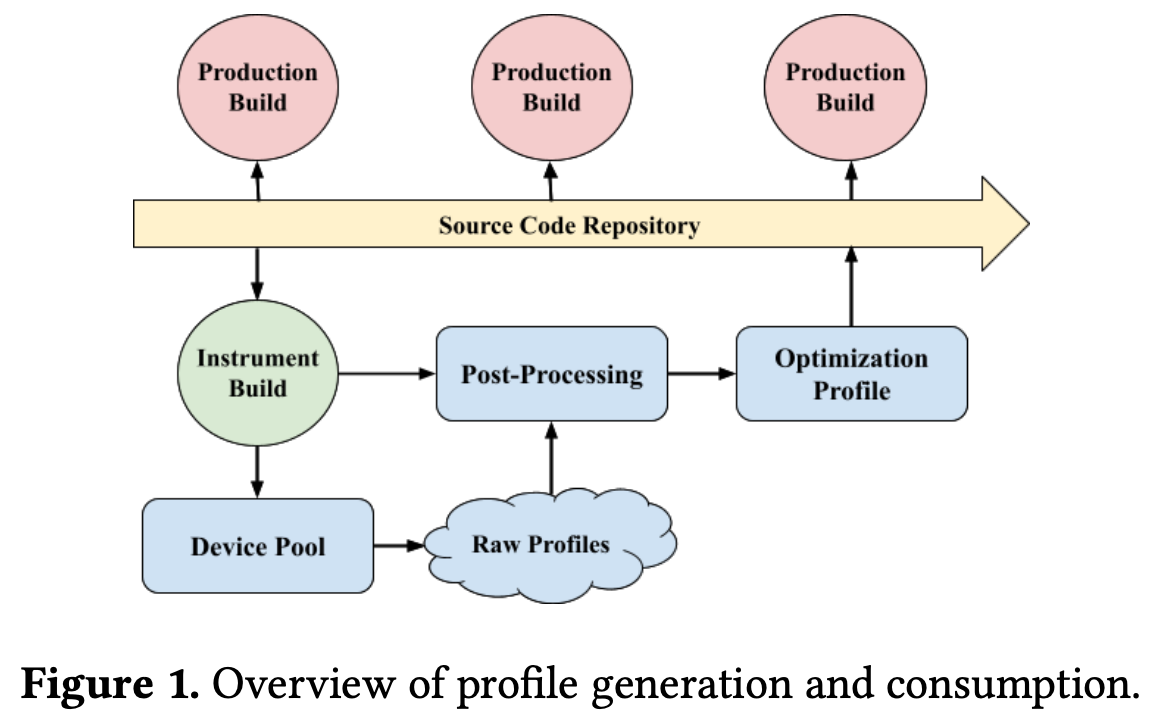
MIP 有几种模式可以选择开启(可多选):
- Function entry timestamps。记录函数第一次执行的时间戳,这里的时间戳是全局的,按执行顺序不断 +1 记录。
- Function entry call counts。记录函数的执行次数。
- boolean coverage data for each basic block。记录代码块是否被执行过。
- return address sampling。在每个被调用函数(callee) 的调用点(call-site),采样的方式记录返回地址值(LR 寄存器的值)。
|
|
1.2、代码块
为什么代码块不记录执行次数,而只是简单地记录是否执行过?
相比于一般的程序,移动设备上的 APP,每个函数的代码块数量并不多,更多的是函数调用的指令。(下图把 APP 与 Clang 自身做对比)
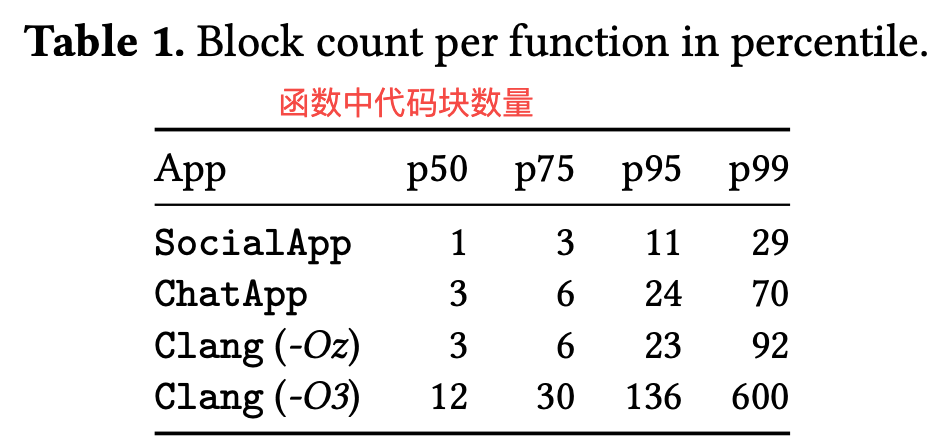
所以在移动端,记录代码块的执行次数是非必要的,用来辅助是否需要 outline 优化即可,用来减少包体积。
2、Outliner
outline(外联) 即把一些相同的连续指令串(指令序列),抽出来整合成一个函数,来减少指令数,从而优化包体积。
这里介绍了三种额外的 outliner 方式。
2.1、global outliner
正常情况下,LLVM 的 machine outliner 一次只会在一个模块中运行。
在开启 Full LTO 时,(LTO 概念可以看这篇文章),所有模块被合并成一个模块进行处理,可以有全局视角去进行优化。
但当使用 Thin LTO 时,不同模块的优化就不容易进行了。这里我们会进行两次 MIR 代码生成(machine-level code generation,注意 MIR 与最终机器码是不一样的)。
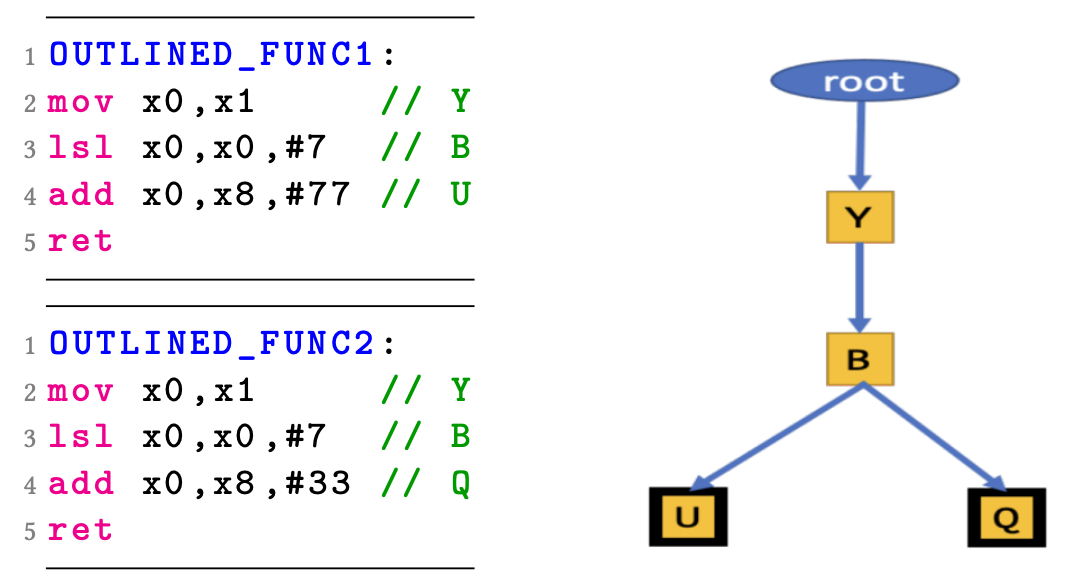
- 第一次收集关于可能进行 outline 机会的数据,每个模块的信息会最终整合到一个全局概要文件当中。这里会计算指令串中指令的 hash 值,用全局前缀树来进行存储。
- 第二次会通过查询指令串 hash 值集合(前缀树),来判断指令串是否有重复,再判断收益是否值得被 outline。然后会通过 link-once One Definition Rule(ODR) 来让链接器去掉冗余的 outline 形成的函数。
2.2、frame outliner
每种语言都有自己的调用约定(calling convention),大多数在函数调用的时候,会包含有 prolog(函数开始时、入栈操作、保存数据) 和 epilog(函数结束时、出栈操作、还原数据)。
这些栈帧指令是可以被 outline 的,但它们的内存操作并不一致,且 LR(link register) 寄存器保存着返回地址,LLVM machine outliner 很难完整把它们抽离。prolog 会有 LR 寄存器的问题,但 epilog 就可以比较完整地抽取了。

2.3、custom outliner
Objective-C 和 Swift 由于要支持 ARC(Automatic-Reference-Counting),会使用到很多的 helper calls(插入了一些辅助运行时引用计数的指令),它们高度重复,但分配的寄存器非常混乱,导致指令串不规则。
所以 custom outliner 会在进行 machine outline 优化之前,在语义上匹配相同指令串(即非完全二进制相同,但它们的执行语义相同),进行 outline,或者先进行规则化地调整指令。
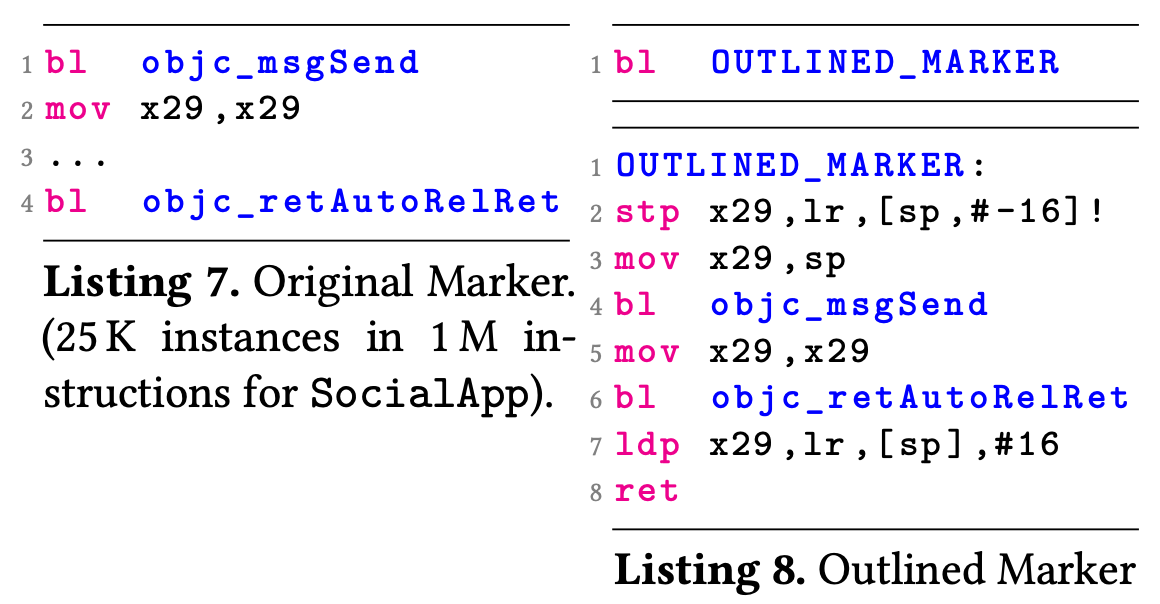
3、优化
通过把调用频繁(hot) 的函数放到一起,减少缺页中断的次数,也可以更好地利用了内存 cache 来优化性能。
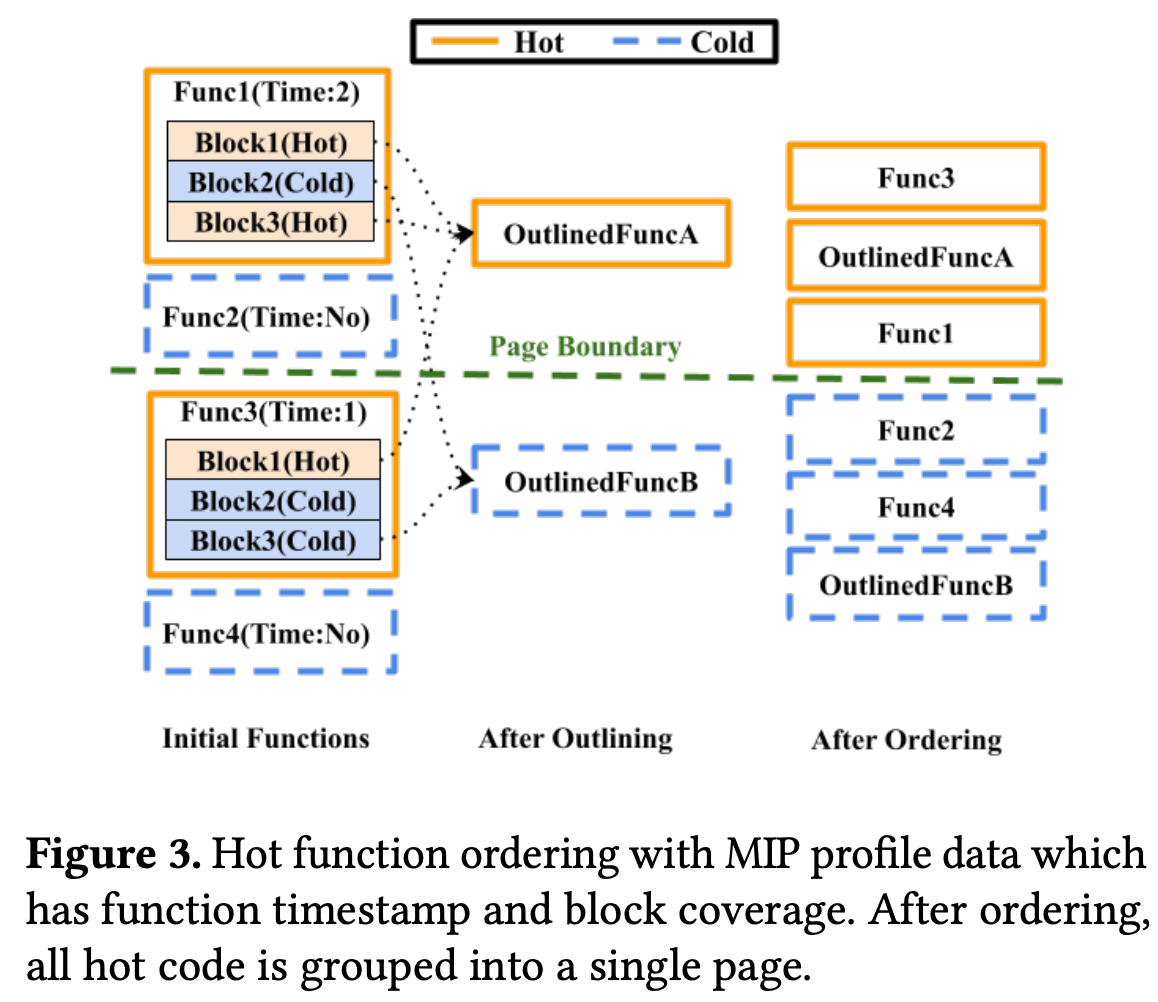
而很多优化这时候会忽略了对很少调用(cold) 的函数的处理,如上篇所说,把有更多共同指令的函数排放到一起,提升压缩率,从而也可以优化包体积。

所以优化策略为:对 hot 函数紧密排列优化性能,对 cold 函数/代码块 outline 进行压缩模型操作优化包体积。
参考
- Efficient Profile-Guided Size Optimization for Native Mobile Applications
- Call site
- RFC: Temporal Profiling Extension for IRPGO
- [InstrProf] Temporal Profiling
- Machine IR Profile
- [InstrProfiling] Lightweight Instrumentation
- [IROutliner] Adding supports for multiple exits
- [IROutliner] Adding outlining for single entry/single exit multiblock regions
- PGO and LLVM Status and Current Work
文章作者 calssion
上次更新 2023-05-07