本文内容主要来源于书《LLVM Techniques, Tips, and Best Practices》最后一章,instrumentation 技术日常开发中应该都会接触到,主要作为程序探测(发现问题或优化程序)的手段。
1、Instrumentation
instrumentation 技术是把 probes(探针、stub、桩) 插入到编译代码当中,用来收集运行时信息(比如一个函数被调用次数)。
- 可以用来对同样的编译代码做优化,而且可以用来执行更激进的优化(more aggressive optimization),这项技术称之为 PGO(Profile-Guided Optimization)。
- 还有是用来捕获运行时的异常情况,比如缓冲区溢出(buffer overflow)、内存竞争(race condition)、内存重复释放(double-free memory) 等,这项技术称之为 sanitizer(写过一篇介绍,也可以翻翻)。
为了在 LLVM 当中实现 instrumentation,不仅需要 LLVM Pass,还需要 LLVM 子项目 Clang、LLVM IR Transformation 和 Compiler-RT 的共同协助。
2、sanitizer
sanitizer 主要用来检查,为了保证程序的正确性以及提高安全性。不同于出问题直接 crash,用 sanitizer 可以把相关问题兜住,输出详细的有意义的分析。
有各种 sanitizer 用来分析各类型的问题:
- Address Sanitizer,检查缓冲区溢出问题。
- Thread Sanitizer,检测数据竞用问题。
- Leak Sanitizer,检测敏感数据泄露问题。
- Memory Sanitizer,检测未初始化数据读问题。
但 sanitizer 也有一些弊端,最明显的就是对性能的影响,编译时间慢了 5~15 倍,插入的指令还会阻碍编译器的优化。
既然这类 instrumentation 技术一般是采用插入 probes 来实现的,那其实等同于在 Pass 中插入指令,在 sanitizer 当中一般是插入一个函数进行操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// 如何创建函数
void LoopCounterSanitizer::initializeSanitizerFuncs(Loop &LP) {
Module &M = *LP.getHeader()->getModule();
auto &Ctx = M.getContext();
Type *VoidTy = Type::getVoidTy(Ctx),
*ArgTy = Type::getInt32Ty(Ctx);
LPCSetStartFn = M.getOrInsertFunction("__lpcsan_set_loop_start", VoidTy, ArgTy);
LPCAtEndFn = M.getOrInsertFunction("__lpcsan_at_loop_end", VoidTy, ArgTy, ArgTy);
}
// 如何创建调用
// Inside LoopCounterSanitizer::run ……
BasicBlock *Header = LP.getHeader();
Instruction *LastInst = Header->getTerminator();
IRBuilder<> Builder(LastInst);
Type *ArgTy = LPCSetStartFn.getFunctionType()>getParamType(0);
if (StartVal->getType() != ArgTy) {
// cast to argument type first
StartVal = Builder.CreateIntCast(StartVal, ArgTy, true);
}
Builder.CreateCall(LPCSetStartFn, {StartVal});
|
创建了函数及其插入了调用点,但函数还只有声明,并没有实现体(body),这时候就需要引入 Compiler-RT 的概念。
Compiler-RT 代表 Compiler RunTime(编译器的运行时),它拥有很多的库,用来补充实现相关特性和功能的代码。需要注意的是,它不是用来构造编译器及其相关工具的,它是需要链接到编译的程序当中一起运行的。
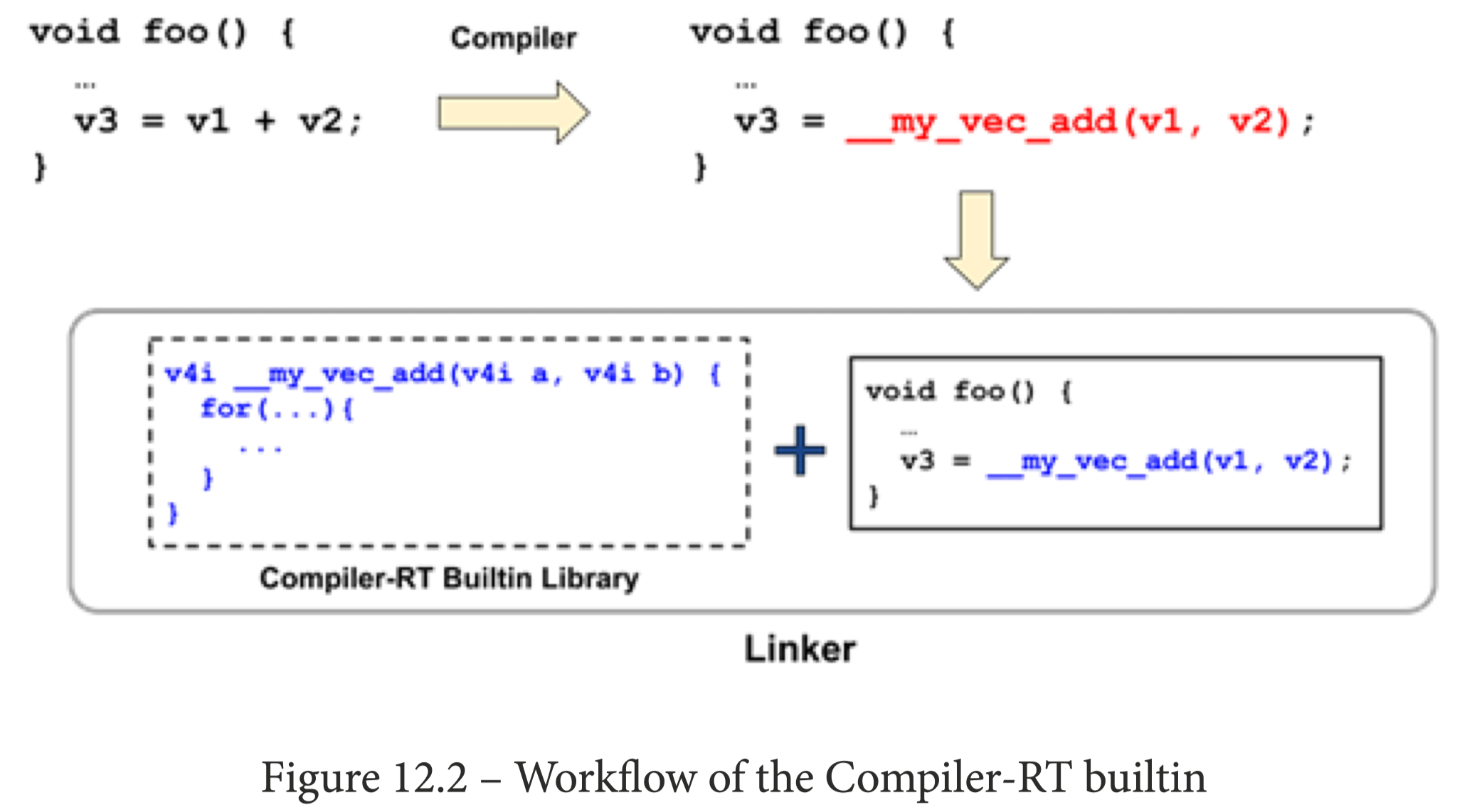
那么我们只需要在 Compiler-RT 完成函数的实现即可。
1
2
3
4
5
6
7
8
|
#include "sanitizer_common/sanitizer_common.h"
#include "sanitizer_common/sanitizer_internal_defs.h"
using namespace __sanitizer;
extern "C" SANITIZER_INTERFACE_ATTRIBUTE // 确保函数被库暴露为接口
void __lpcsan_set_loop_start(s32 start){ // 这里用 s32 和原始类型保持一致,代表 sign-32bit
// TODO
}
|
3、PGO(Profile-Guided Optimization)
PGO 使用运行时收集到的数据,来进行更激进的优化。PGO 名字里的 profile 就代表收集来的运行时数据。
有了 profile,那么 PGO 可以做什么优化呢?比如下面的案例。
1
2
3
4
5
6
|
void foo(int N) {
if (N > 100)
bar();
else
zoo();
}
|
通常优化器优化这段代码时,会对调用函数(callee)进行内联(inline)操作,但有个问题是,如果所调用函数的函数体非常大,那么内联就会增大了包的体积。理想情况下,这段代码是分支代码,如果只内联调用频率最高的那个函数,会更好(基于性能和包体积的一个平衡)。有了运行时数据 profile,就可以对这段代码进行优化了(profile 信息可以帮助分支优化、函数和代码块布局重排、寄存器分配等)。需要注意的是,所采集到运行时信息需要具有一定的普遍性和准确性,不然依此进行的分析可能得到的只是负优化。
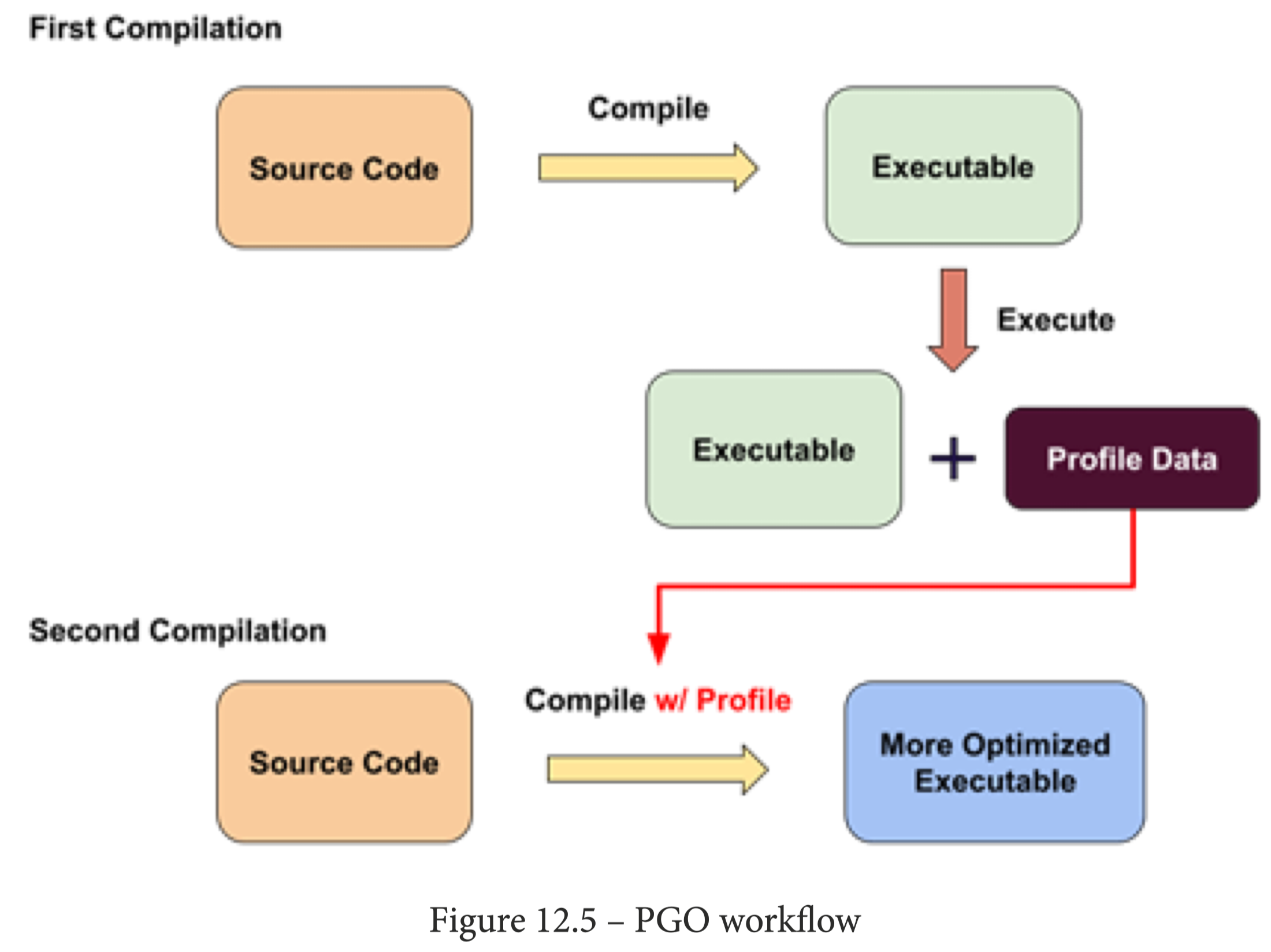
所以,进行 PGO 优化需要两个阶段,第一个阶段是正常地编译和优化代码,当执行程序后,得到运行时数据 profile 文件;第二个阶段就是结合 profile 文件来编译和优化代码,从而得到更好的优化效果。
现在 PGO 收集运行时数据主要有两种方式:插入 instrumentation 代码获取数据 和 基于采样获取数据。
-
instrumentation-based PGO 就是在第一个编译阶段插入 probes 代码,计算代码块和函数的执行频率,然后把结果写入到文件当中。这种方式数据精准度很高,对于优化很有帮助,但是同时也影响了程序的运行性能,由于需要把 probes 指令写入代码当中,也会增加二进制体积。
-
sampling-based PGO 是使用一个额外的工具(比如 perf 或 valgrind 等)来收集运行时数据,可以得到一些系统或硬件特性相关的细节(比如 perf 可以拿到分支预测结果(branch prediction)和缓存不命中(cache line misses)信息)。这种方式有着较低的性能开销,也不需要重新编译代码来收集 profile,但是它的准确度较低,在第二个阶段也比较难以把 profile 数据映射回原来的代码。
下面介绍 instrumentation-based PGO,关于 sampling-based PGO 可以阅读字节服务端对 Speculative Devirtualization 的优化案例。
3.1、instrumentation-based PGO
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 以 instrumentation 方式进行第一阶段编译
$ clang -O1 -fprofile-generate=pgo_prof.dir pgo.cpp -o pgo
# 运行程序结束后,生成文件会以 default_<hash>_<n>.profraw 命名存储
$ ls pgo_prof.dir
default_10799426541722168222_0.profraw
# 转成第二阶段编译所需要的 profile 格式
$ llvm-profdata merge pgo_prof.dir/ -o pgo_prof.profdata
# 查看相关信息
$ llvm-profdata show –-all-functions –-counts pgo_prof.profdata
# 应用
$ clang -O1 -fprofile-use=pgo_prof.profdata pgo.cpp -emit-llvm -S -o pgo.after.ll
|
这样生成的 LLVM IR 会携带上 profile 的数据信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 这里的 !prof 即是 profile 元数据(IR 中元数据都以感叹号开头)
define void @foo(i32 %x) !prof !71 {
entry:
%call = call i32 @get_random()
%cmp = icmp sgt i32 %call, 5
br i1 %cmp, label %if.then, label %if.end, !prof !72
if.then:
%mul = mul nsw i32 %x, 3
}
// 71 代表函数被执行了 110 次
!71 = !{!"function_entry_count", i64 110}
// 72 代表分支执行 57 次,不执行(false branch) 次数为 54 次
!72 = !{!"branch_weights", i32 57, i32 54}
|
3.2、instrumentation level
插桩有不同的粒度,LLVM 支持以下几种粒度:
- IR,在进行 pass 优化时插桩,提供了比较好的数据准确度,但面临着编译器改动的风险(生成的 IR 可能随着 LLVM 版本迭代会有改变,所以插桩的位置也会有所变化)。
clang -fprofile-generate,Instrumentation level: IR。
1
2
3
4
5
6
7
8
9
10
|
// 以全局变量 @__profc_foo.0 存储计数器
define void @foo(i32 %0) {
%4 = icmp sgt i32 %3, 10
br i1 %4, label %5, label %9
5:
%6 = load i64, i64* … @__profc_foo.0, align 8
%7 = add i64 %6, 1
store i64 %7, i64* … @__profc_foo.0, align 8
%8 = call i32 @puts(…"hello"…)
br label %13
|
-
AST(语法树,Front-end base),很少会受到编译器改动的影响,有着更加稳定的 profile 数据格式,但数据准确度较低。对比 IR 级别,同一函数插桩的数量可能更多。-fprofile-instr-generate,Instrumentation level: Front-end。
-
Context-sensitive(上下文敏感),这种方式会在函数 inline 之后再去做一次插桩,这样还可以知道是哪个调用方带来的某个执行分支的执行次数增加,这种方式有着更高的准确度。但问题也在于再做一次插桩,所以需要跑三次编译。
1
2
3
4
5
6
7
8
9
10
11
12
|
# 第一次 IR 插桩执行
$ clang -fprofile-generate=first_prof foo.c -o foo_exe
$ ./foo_exe …
$ llvm-profdata merge first_prof -o first_prof.profdata
# 第二次 context-sensitive 插桩执行
$ clang -fprofile-use=first_prof.profdata -fcs-profile-generate=second_prof foo.c -o foo_exe2
$ ./foo_exe2
$ llvm-profdata merge first_prof.profdata second_prof -o combined_prof.profdata
# 使用 profile 优化执行
$ clang -fprofile-use=combined_prof.profdata foo.c -o optimized_foo
|
对于生成的 profile 文件,是需要与其对应的插桩方式对应使用的,可以使用 llvm-profdata show -topn=1 <profile_path> 对 profile 的格式进行查看。如果格式不对应,LLVM 也会报错:
1
|
error: pgo.profdata: Not an IR level instrumentation profile
|
3.3、使用 profile 数据的 APIs
1
2
|
$ opt -pgo-test-profile-file=pgo_prof.profdata \
--passes="pgo-instr-use,my-pass…" pgo.ll …
|
pgo-instr-use 代表 PGOInstrumentaitonUse 这个 Pass,它会读取 profile 文件,然后把数据标注(annotate)到 IR 当中(元数据 !prof)。我们需要这个 Pass 来帮我们先解析好 profile 的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// `BB` has the type of `BasicBlock&`
// 代码块的最后一条指令,通常都是分支跳转
Instruction *BranchInst = BB.getTerminator();
MDNode *BrWeightMD = BranchInst->getMetadata(LLVMContext::MD_ prof);
if (BrWeightMD->getNumOperands() > 2) {
// Taken counts for true branch
MDNode *TrueBranchMD = BrWeightMD->getOperand(1);
ConstantInt *NumTrueBrTaken = mdconst::dyn_extract<ConstantInt>(TrueBranchMD);
// Taken counts for false branch
MDNode *FalseBranchMD = BrWeightMD->getOperand(2);
}
// `F` has the type of `Function&`
Function::ProfileCount EntryCount = F.getEntryCount();
uint64_t EntryCountVal = EntryCount.getCount();
|
LLVM 还基于 profile 数据实现了几个分析(analyses),来传递高层级、结构化的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// 分支的执行概率信息,但并非基于当前的 if-else,而是从函数入口开始算
BranchProbabilityInfo &BPI = FAM.getResult<BranchProbabilityAnalysis>(F);
BasicBlock *Entry = F.getEntryBlock();
BranchProbability BP = BPI.getEdgeProbability(Entry, 0);
// 分支的执行频率
BlockFrequencyInfo &BFI = FAM.getResult<BlockFrequencyAnalysis>(F);
for (BasicBlock *BB : F) {
BlockFrequency BF = BFI.getBlockFreq(BB);
}
// 获取模块整体的 profile 信息
ProfileSummaryInfo &PSI = MAM.getResult<ProfileSummaryAnalysis>(M);
// 使用 isFunctionEntryCold/Hot 可以判断函数执行频率是否低于/高于阈值
// isHot/ColdBlock 用于对比模块内的所有代码块
// isFunctionCold/HotInCallGraph 可以从 CallGraph 视角分析,更加准确
|
profile 中存储的是如 3.1 中案例的 branch weight(分支权重,分支执行的次数),然后基于这些信息,编译器可以分析出某个执行路径(分支)的 branch probability(分支执行概率) 以及 block frequency(分支执行频率)。
实际上 branch weight 除了可以在 profile 文件中获取,还可以从函数 __builtin_expect 和 __builtin_expect_with_probability 中生成。
1
2
3
|
if (__builtin_expect_with_probability(x > 0, 1, 0.8)) {
// This block is likely to be taken with probability 80%.
}
|
参考