编译器 inline 内联优化简介
文章目录
inline 内联优化算是比较常见的编译器优化,这里简单介绍一下。
1、function call
为了进行函数调用,程序需要将调用参数放到栈或寄存器中,同时还需要保存一些寄存器到栈上,以免 callee 会覆盖到。函数执行的切换,对于代码局部性、寄存器使用、运行性能都会有不少的影响。
2、inline
inline 是通过把函数的实现体内置到调用点处,避免了函数调用的性能开销,虽然同时可能因为重复指令而带来代码体积的增大。
|
|
(inline 后体积增大并不是必然,比如有研究 Inlining for Code Size Reduction,通过 inline 消除那些只会被调用一次的函数(需要有全局视角,通常结合 LTO 使用),反而减少了栈相关指令而减少体积。)
编译器并不能保证一定会进行 inline 优化,以下是其中的一些策略:
- 在不同的编译单元中,通常不会 inline,因为可能找不到其实现和定义。除非开启了 LTO(link time optimization、链接时优化,之前文章介绍过)、模块化编译等功能。
- C++ 类方法定义在类声明中,会被 inline,除非太大。
- 静态(static) 函数大概率会被 inline。
- 标记为 virtual 的 C++ 方法,不能被 inline。
- 通过函数指针来调用的函数,不能被 inline。
- 通过 lambda 表达式作为函数,可能会被 inline。
- 太长的函数体,通常不会被 inline。有 inline-threshold 的相关参数可以控制阈值。
- 使用 inline 关键字通常还是会被编译器所忽视,还有
__attribute__((always_inline))和__attribute__((flatten)),这些如果不能 inline 会报编译警告。
实际情况会比较复杂,这里有篇有趣的文章列举了一些是否 inline 的案例 Does it inline? 可以看看。
3、inline 附赠的其他优化
inline 除了自己带来了性能上的优化,实际上,在 inline 之后的代码,也让其他优化看到了机会。所以在测试 inline 效果时,不能仅仅只考虑是 inline 进行的优化,还有其他优化也被影响到了。
下面将会简单地列出几个案例。
3.1、loop merging
比如在 inline 之前,有代码示例如下:
|
|
在进行 inline 优化的时候,find_min 和 find_max 函数都可能会被编译器进行 inline。因为 find_min 和 find_max 代码逻辑高度相似(以相同的范围来进行遍历,同时也没有数据依赖),所以当它们一起出现在一个地方时,就可以进行 loop merging(循环合并) 的优化。效果大致如下:
|
|
这有效地减轻了 CPU 的任务,而且还提高了数据缓存的命中使用率。
注:需要编译器能够同时看到这两个函数的实现体,因为某些函数为外部引用,编译器看不到其实现,只能临时占位(待链接器补充),也就无从优化。本文不考虑这些情况。(关于跨模块优化可以看下我之前写的 LTO 优化的文章)
3.2、常量传播
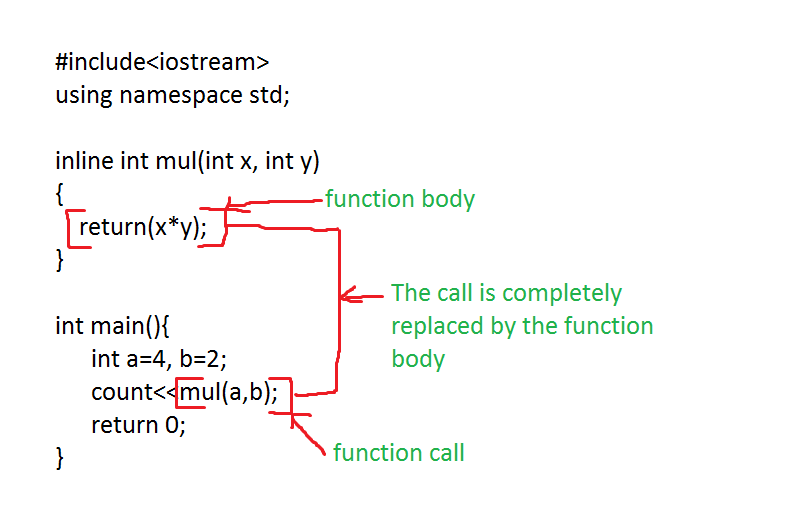
在上图中,mul 函数直接被 inline 成 a * b,由于 a 和 b 的值,并没有在过程中被修改,实际上就可以被直接优化成 4 * 2,最后直接替换为 8。减少计算乘法的指令,优化了性能。
参考
- Link Time Optimizations: New Way to Do Compiler Optimizations
- Make your programs run faster: avoid function calls
- Impact of the current LLVM inlining strategy on complex embedded application memory utilization and performance
- Does it inline?
- LLVM Function Inlining Pass
- Inlining for Code Size Reduction
文章作者 calssion
上次更新 2023-07-03