HotColdSplitting: 代码分离之性能优化
文章目录
接上篇文章,outline 不仅仅是用作减少代码体积的优化技术,还可以用来优化性能,可以有 2% 左右的提升,本文简单介绍一下。
1、hot/cold splitting
hot/cold splitting(冷热块分离) 旨在提升代码内存的局部性,这个优化技术是识别出冷块(cold block,或 the sink,即使用频率低的代码块),然后将它们移出到单独的函数当中。这样我们保持更多的热块在一起,提升内存的使用效率,对程序启动性能也有帮助。
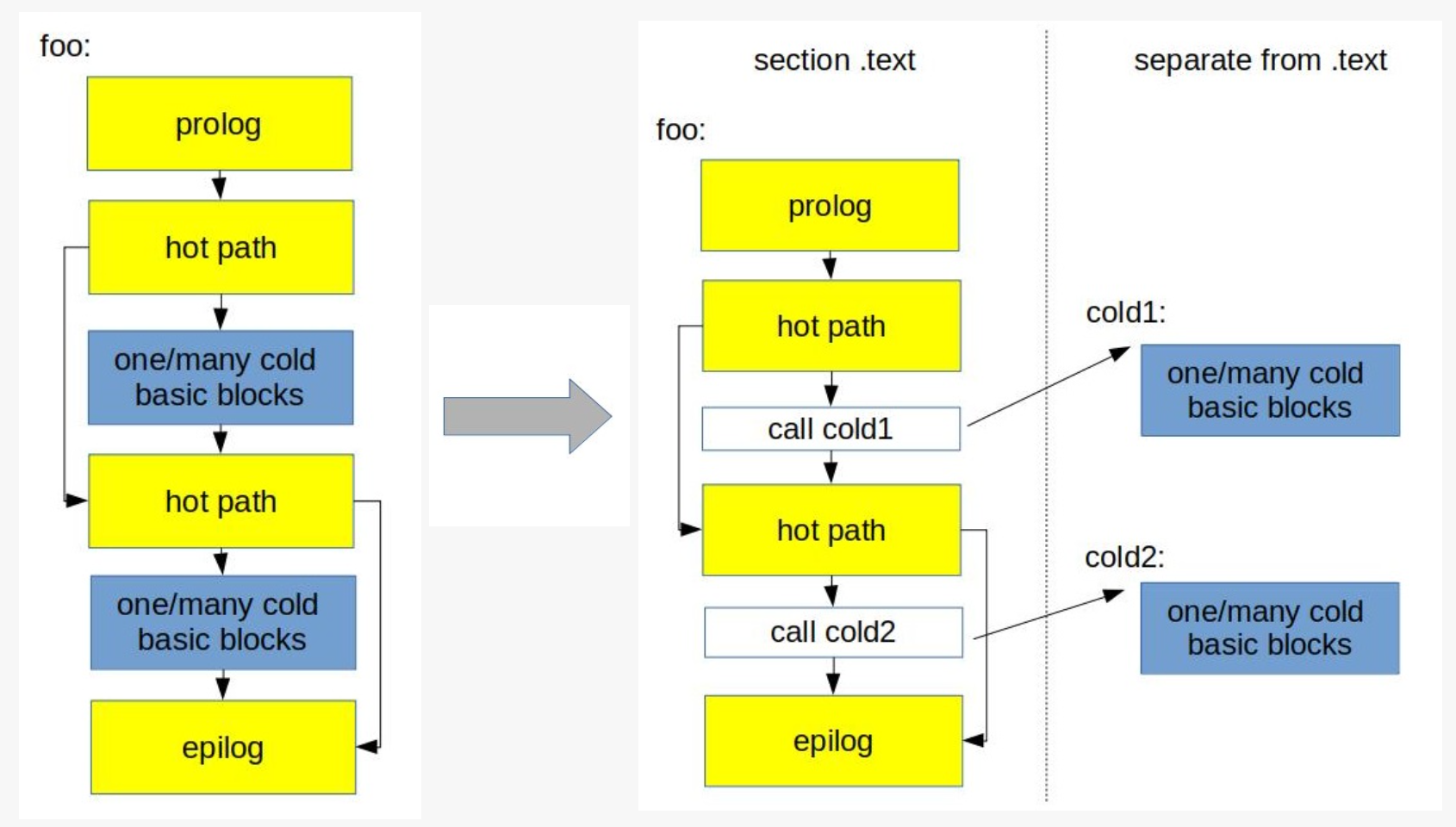
在 LLVM 中通过 -llvm -hot-cold-split=true 来开启 HotColdSplitting Pass,一般而言是默认开启的优化,主要实现逻辑在 lib/Transforms/IPO/HotColdSplitting.cpp 文件中。
这个优化是在 IR 层面上实现的,利用运行时 profile 信息和静态分析的手段,来进行优化。还可以通过 -llvm -enable-cold-section=true 来把冷块都移到一个单独的 section 里存放,可设置段名,默认名字是 __llvm_cold 。
当然也会有在 Machine IR 级别上的 hot/cold splitting 优化,通过 -mllvm -split-machine-functions=true 开启 MachineFunctionSplitter Pass,不过这个 pass 需要基于运行时 profile 信息来处理,或者也可以直接应用于异常处理(exception handler) 的代码。
2、依靠运行时信息的静态优化
这部分简单展开一下,然后再讲到 hot/cold splitting。
引入一套框架来在运行时进行动态优化或许过于臃肿,但只要拿到运行时信息记录 profile,那么在静态优化的时候也是可以基于这个信息做优化的。但是对于 profile 的准确度和匹配程度要求会比较高,且不能动态调整,操作流程会比较繁琐一点。
这种技术称之为 FDO(feedback-driven optimization) 或 PGO(profile-guided optimization)。在 “LLVM Instrumentation 程序探测” 文章中介绍过,实现 PGO 的方式有两种,一种是提前编译插桩,然后运行程序生成 profile 信息;另一种是在程序运行的时候用额外的工具(如 perf 等) 收集 profile 信息。然后都是基于 profile 信息再进行编译静态优化,生成最终的二进制产物。
2.1、instrumentation-based PGO
这里拿基于插桩获取 profile 信息的 PGO 方式展开介绍。
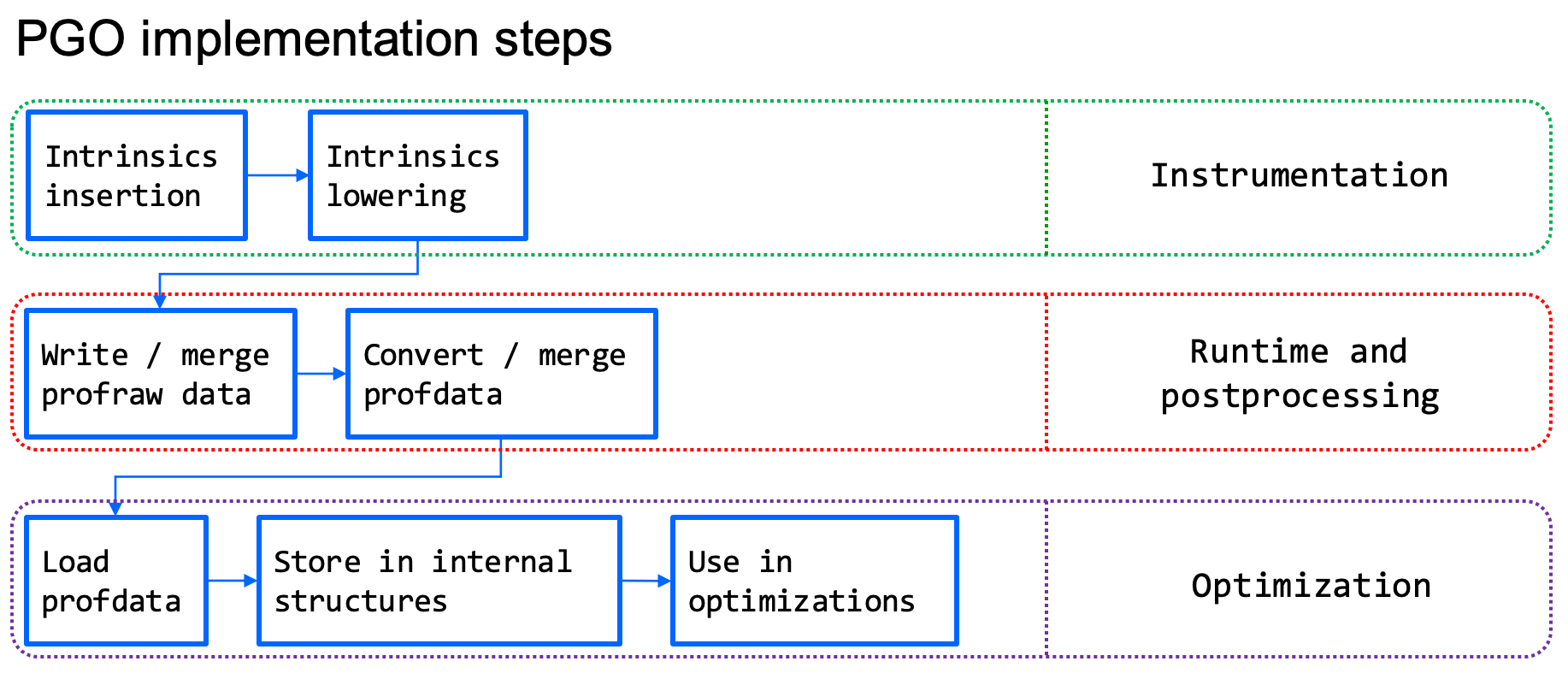
插桩是基于 MST(minimum spanning tree、最小生成树) 计算,在函数当中选取最小量的必要的代码块,插入 profiling 计数器的代码。在二进制产物当中,会多出用来存放计数器以及相关数据的 section 段。
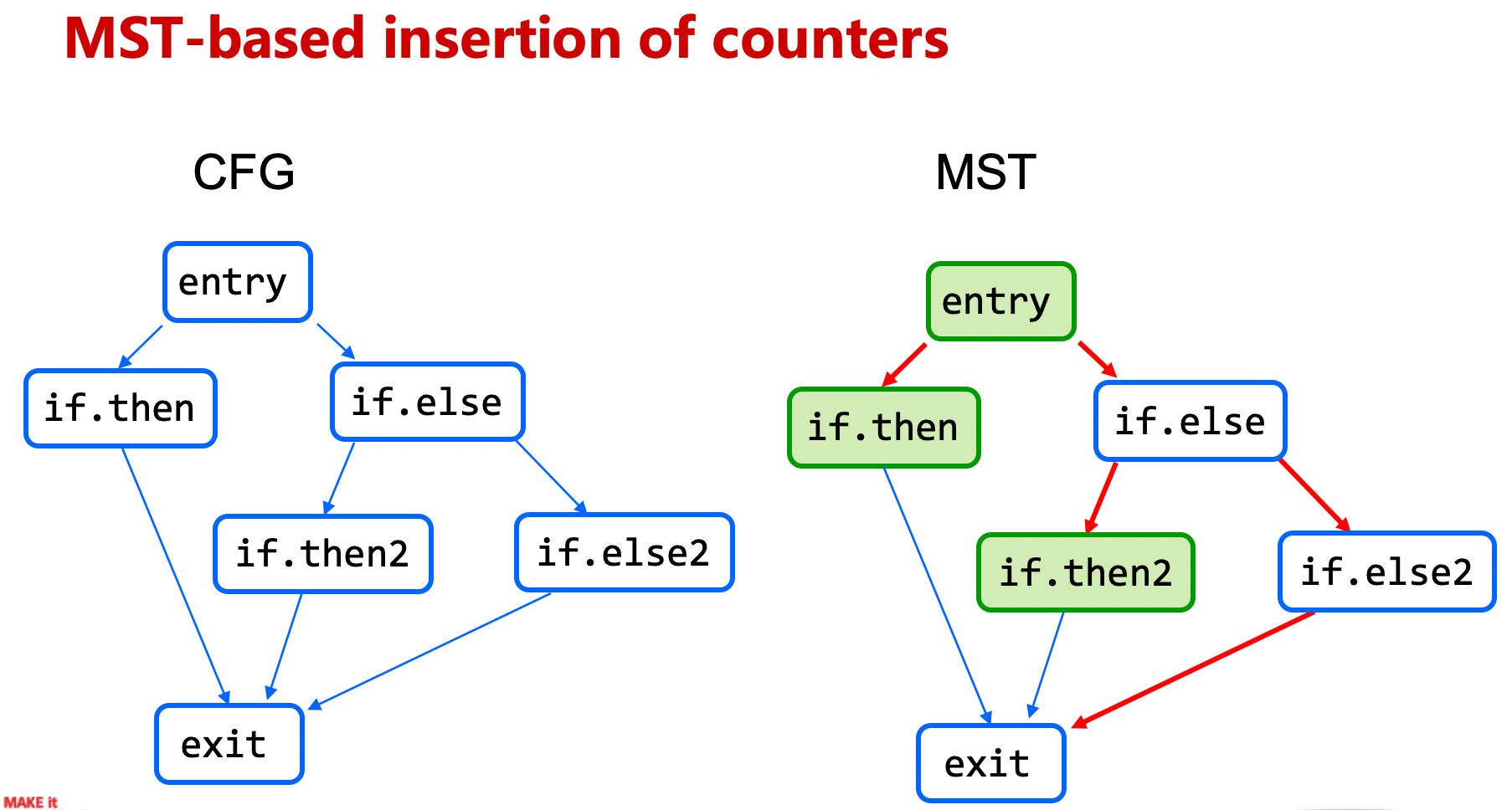
多出的指令如下:
|
|
插桩后的二进制,默认会使用静态初始化(static initializer) 来进行 profiling 的准备和注册,也可以自行手动调用。在进程启动的时候,调用 __llvm_profile_init 开始初始化操作,profile 文件的生成路径可以使用 LLVM_PROFILE_FILE 环境变量控制,由 __llvm_profile_initialize_file 解析。在进程结束时调用 __llvm_profile_write_file 写入到 profile 文件到磁盘当中。
拿到 profile 文件之后,使用 llvm-profdata 工具进行进一步的处理。
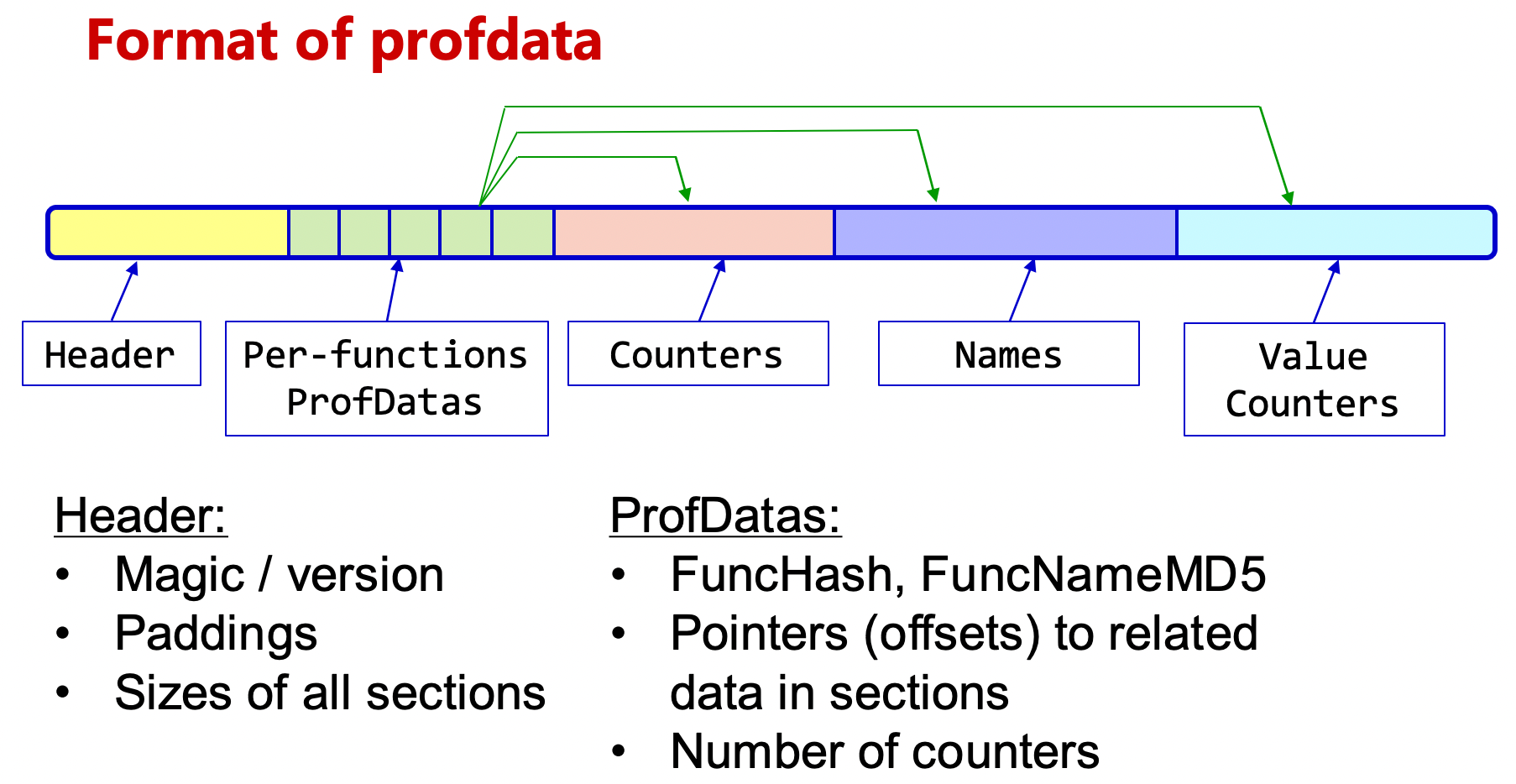
举一些优化的例子,可以用来提升性能:
- block layout/block ordering。代码块的布局重排,对分支跳转相关的代码进行良好调整,可以有效提升局部性、减少内存操作。
- spill placement/register allocation。关于有限的寄存器如何有效地存储过多的存活的变量。
- inlining heuristics。函数内联的可能性。
- hot/cold partitioning。冷热块分离,指执行频率的高低。
- optimizing virtual calls。脱虚,在 “C++ 虚函数优化探索简介” 中有介绍过。
简单展开其中的几个讲讲。
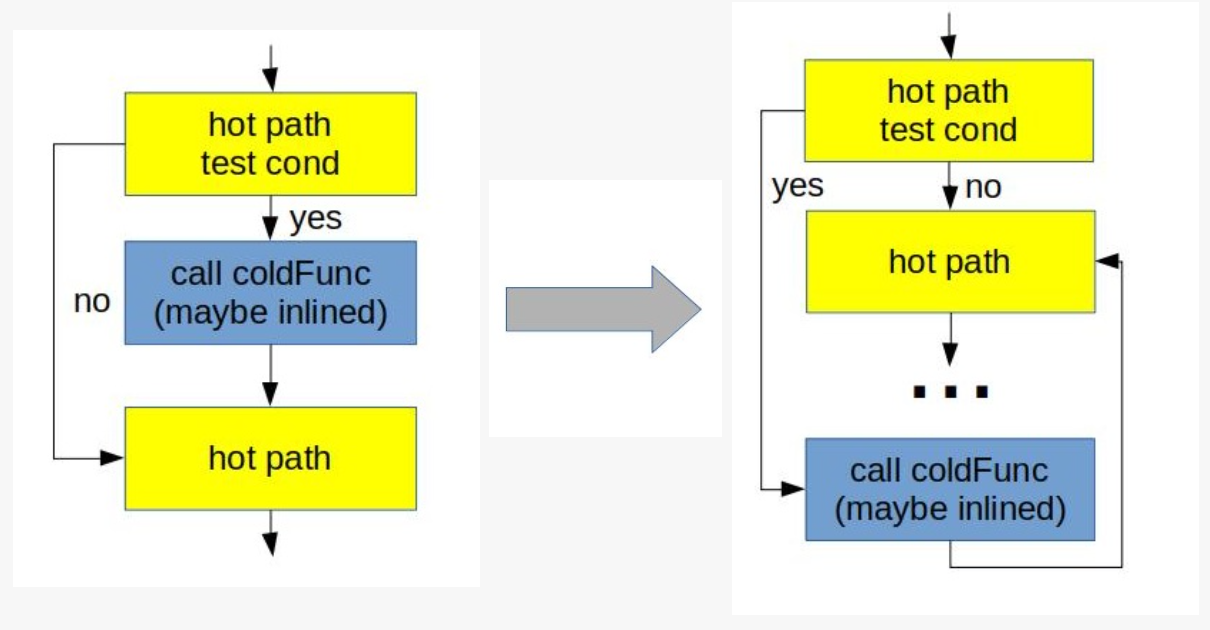
2.1.1、block layout
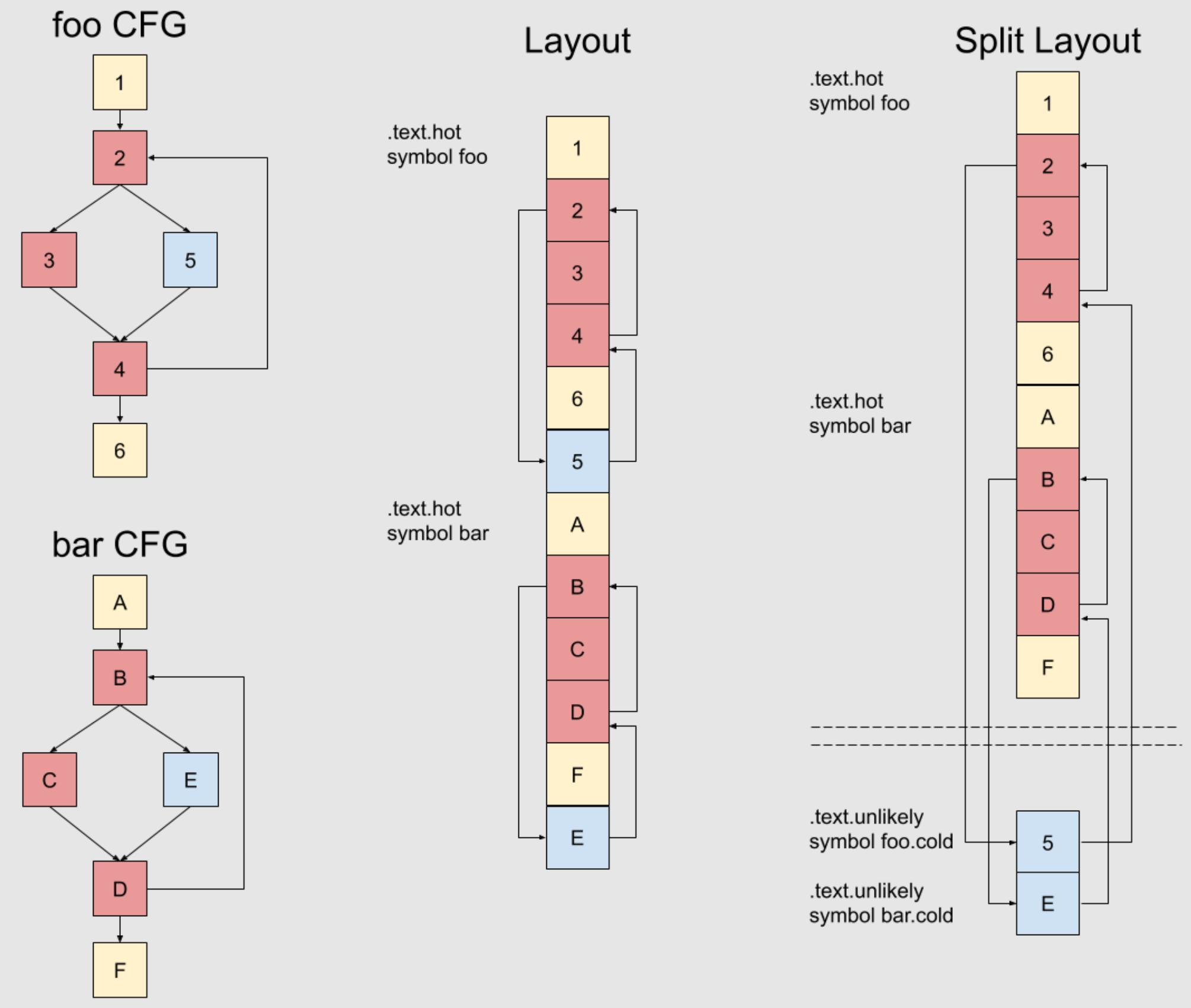
一般情况下,最简单的代码块的排列顺序的方式,是按照开发者源码的顺序来设置。但这通常不是性能最好的方式。
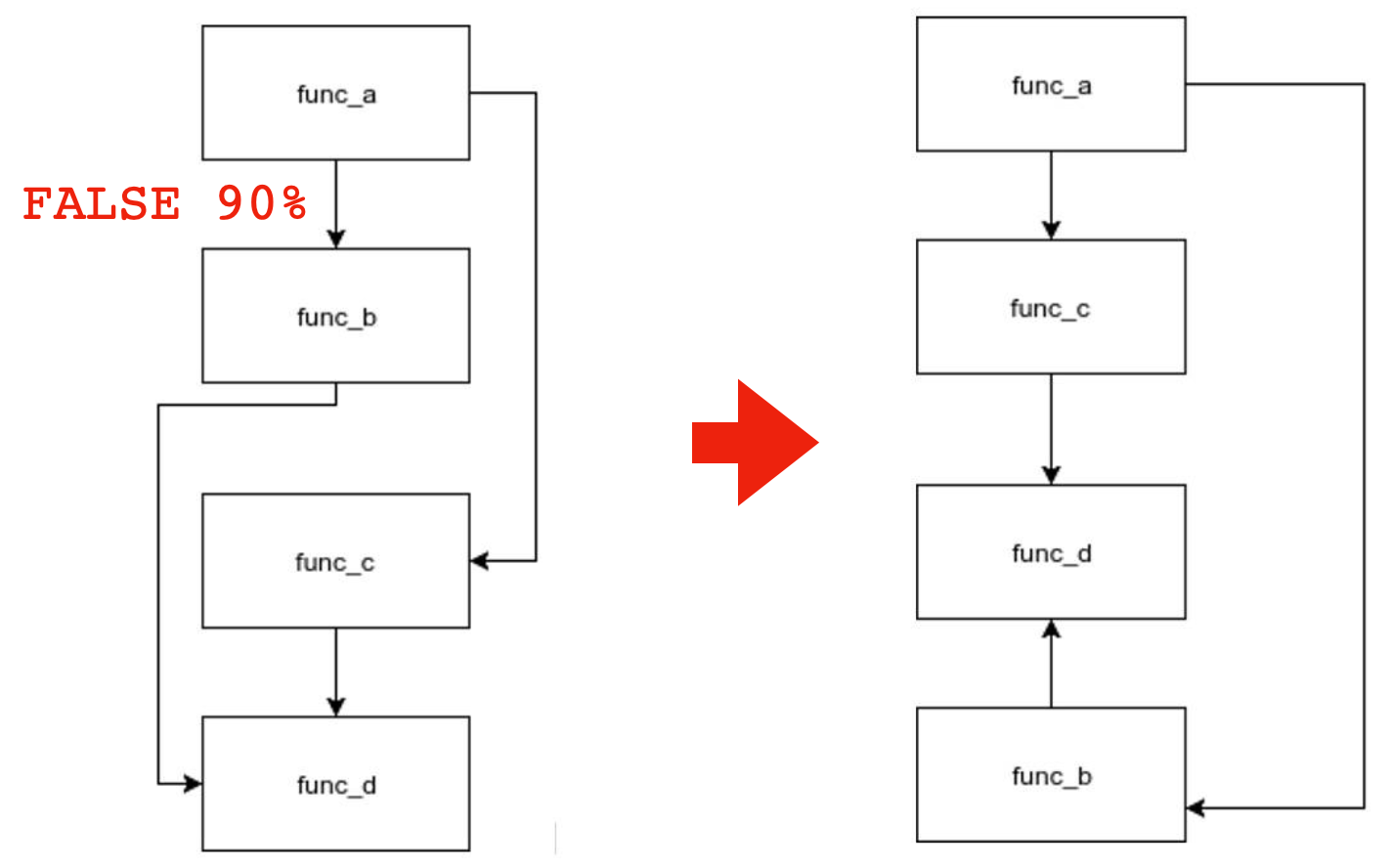
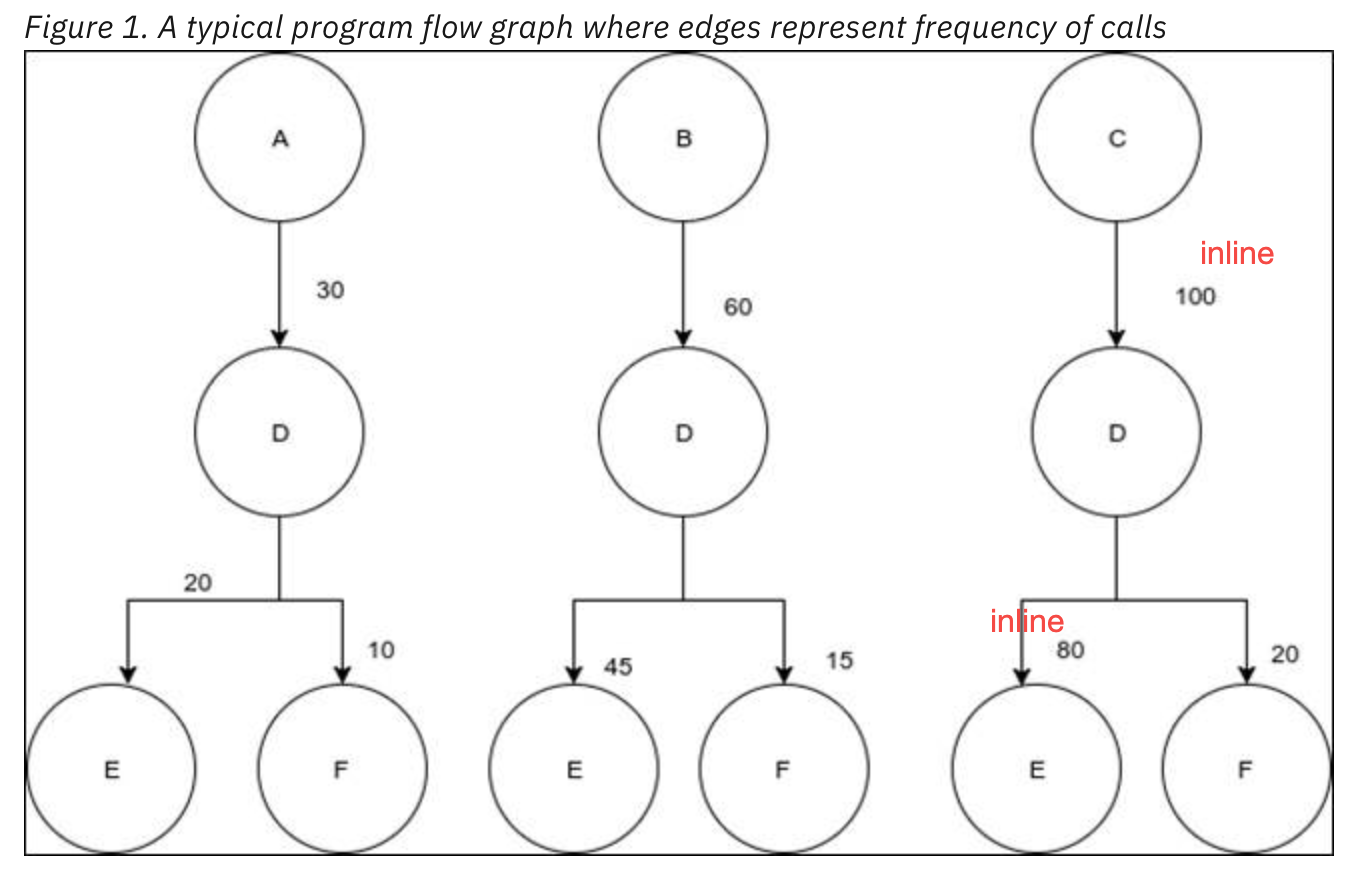
比如下图,函数 a 有两个分支,分别是函数 b 和函数 c,基于 profile 信息,如果我们发现有 90% 的情况下,都不会调用到函数 b,那么我们为了提升函数的局部性,可以把函数 c 挪到函数 a 的后面,对于现代 CPU 的分支预测也有一定的好处。
2.1.2、register allocation
虽然 RISC(精简指令集) 架构的寄存器数量会比 CISC(复杂指令集) 架构的多,但是否能对寄存器合理使用,还是对性能会有不少影响。
有了 profile 信息,编译器可以比较容易地发现使用得频繁的活跃变量,然后优先分配寄存器,减少从 cache/内存当中读取数据,提升数据读写的性能。
2.1.3、inlining heuristics
基于 profile 信息,把被高频调用的函数 inline 到调用者中,减少函数调用的开销。正常情况下,编译器决定是否要 inline 是基于代码块的大小;而当有了 profile 信息,做这个决定就变得不那么困难。主要判断逻辑在 llvm/lib/Transforms/Utils/InlineFunction.cpp 中。
2.1.4、hot/cold partitioning
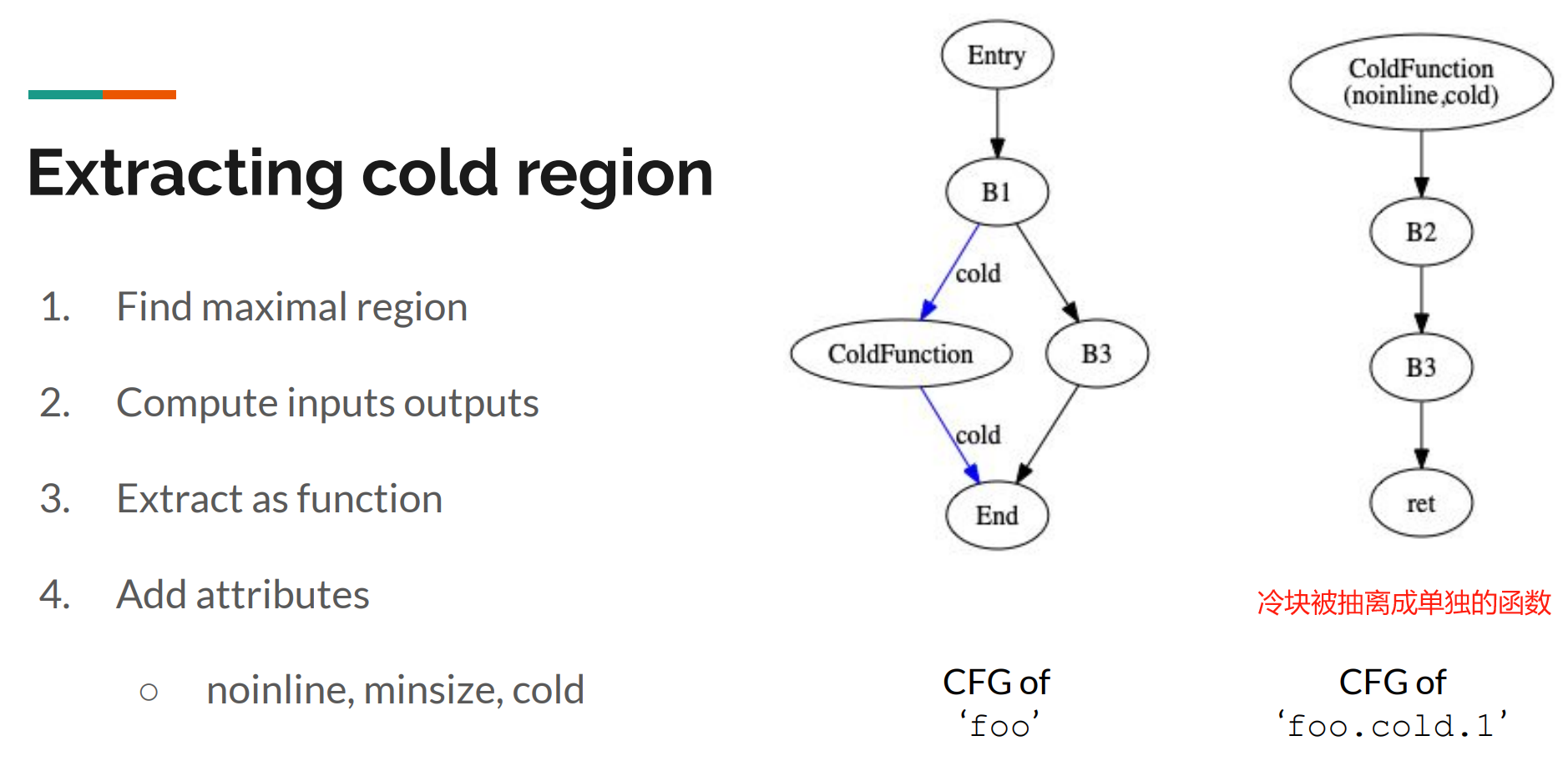
冷热代码块基于 profile 当中的执行频次来进行判断,通过 ProfileSummaryInfo 可以拿到相关的信息,可以判断 BlockFrequencyInfo 或 BranchProbabilityInfo。如果分离冷块的收益(分离出来的指令总大小) 大于损耗(调用被分离的冷块和读取数据的额外操作占用),那么就可以进行提取分离。
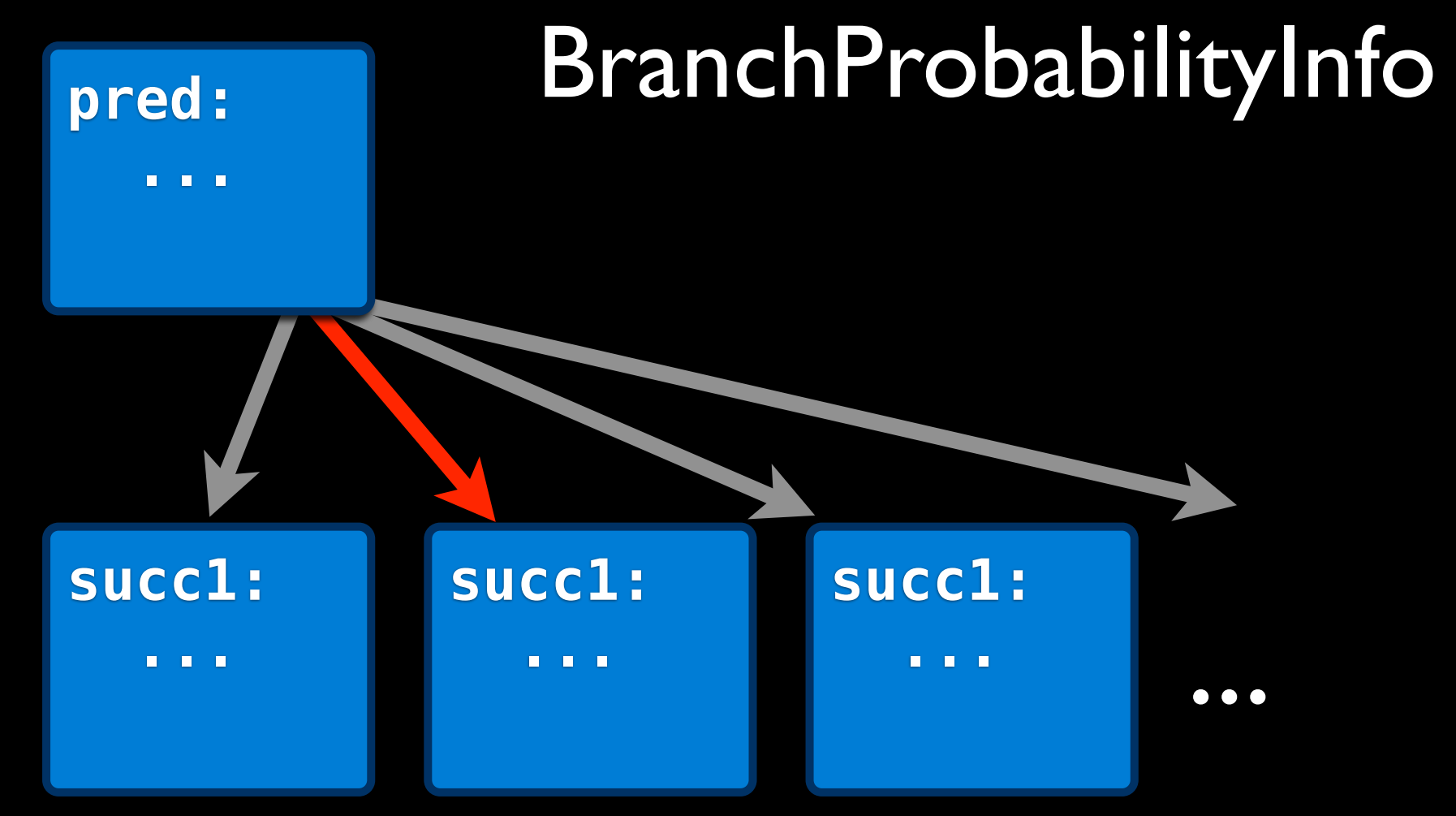
被分离的冷块会以 <原函数名>.cold.<num> 来命名。
3、静态分析
获取运行时 profile 信息并不是那么简单的事情,那么其实 hot/cold splitting 也可以利用一些静态分析来进行辅助判断。
在 LLVM 的 unlikelyExecuted 函数中会对 BasicBlock 进行静态分析判断,像 Exception handling blocks(异常处理的块)、调用了冷函数的块、以及 unreachable 的块都可能判断为冷块。
虽然但是,没有运行时 profile 信息的帮助,靠静态分析,这个优化会大打折扣。
我们还可以利用在源码中使用注解来辅助编译器判断,类似 __builtin_expect 函数,可以告知编译器更可能的执行路径。还有 __attribute__((cold)) 的注解,直接标明这是一个冷函数。
4、扩展
分离冷块成独立的函数之后,可以结合 -llvm -enable-merge-functions=true 来开启 MergeFunctions Pass,合并相同的函数,减少一些代码体积。
还有个没合入的激进想法 Randomly outline code for cold regions,即在没有 profile 信息的情况下,二八法则划分冷热块,认为 20% 热块,80% 冷块,怎么划分?随机!生成随机数然后判断。有点暴力,所以这个肯定不会被接受了。
与 HotColdSplitting Pass 类似而不太相同的一个优化:PartialInlining Pass,可以通过 -llvm -enable-partial-inlining=true 开启。它不把整个函数体内联到调用处,而是选择函数体的某部分来进行 inline 操作,这里通常是热块。
参考
- Strength Reduction Pass in LLVM
- Infrastructure to allow use of PGO in inliner
- Efficient Profiling in the LLVM Compiler Infrastructure
- PGO and LLVM Status and Current Work
- Profile-guided optimization(PGO) using GCC on IBM AIX
- Source-based Code Coverage
- lib/Transforms/IPO/HotColdSplitting.cpp
- Hot cold splitting in LLVM
- Improving Hot/Cold Splitting in LLVM
- [llvm-dev] [RFC] Machine Function Splitter - Split out cold blocks from machine functions using profile data
- Transparent Dynamic Optimization: The Design and Implementation of Dynamo
- MergeSimilarFunctions 1/n: a code size pass to merge functions with small differences
- Randomly outline code for cold regions
- [llvm-dev] [RFC] Machine Function Splitter - Split out cold blocks from machine functions using profile data
- Red Hat Enterprise Linux 7 GCC Optimizations - partial inlining indepth
- Machine code layout optimizations.
文章作者 calssion
上次更新 2023-12-04