HALO: 动态堆内存布局优化技术
文章目录
读到一篇动态内存分配优化的论文,HALO 与 jemalloc 相比,减少了 L1 data-cache miss 达 23%,总执行时间减少 28%,显著地提升了性能。
本文简单解读一下 该论文 《HALO: Post-Link Heap-Layout Optimisation》。
1、问题
一般而言,分配内存会交给专门的分配器(如 jemalloc、tcmalloc 等) 操作即可,C++ 程序直接调用 new/malloc 就调到分配器执行,由固定的接口执行,可能会不灵活、偏保守,但可以满足大多数情况平均的使用模式,虽然无法适应各个程序的特定行为。
几乎所有现代通用分配器都基于大小隔离的分配方案(size-segregated allocation schemes),它们围绕固定数量的大小类别来组织内存块,因此,分配主要根据其大小和进行的顺序来放置。虽然合理,但强相关的、非连续分配或内存大小不一致的数据对象,在频繁访问时,局部性表现会很差,可能不在同一个 cache line 或内存页。

如果不深入了解程序如何使用值,它们只能依靠简单的启发式方法(heuristic) 来放置数据,并且可能会无意中将高度相关的数据分散到整个堆中,从而产生不必要的 cache miss(缓存未命中)、TLB miss 和预取失败。
虽然编译器使用基本块(basic block) 重排、循环体优化、智能寄存器分配等技术来优化程序性能,但动态分配的内存布局在很大程度上仍然超出了静态工具的能力范围。
2、HALO
HALO(Heap Allocation Layout Optimiser、堆分配布局优化器) 是为了帮助缓解这些问题而开发出来的,在链接后基于 profile(运行时采集数据) 进行优化,智能地重新排列堆数据以减少 cache miss 的发生。
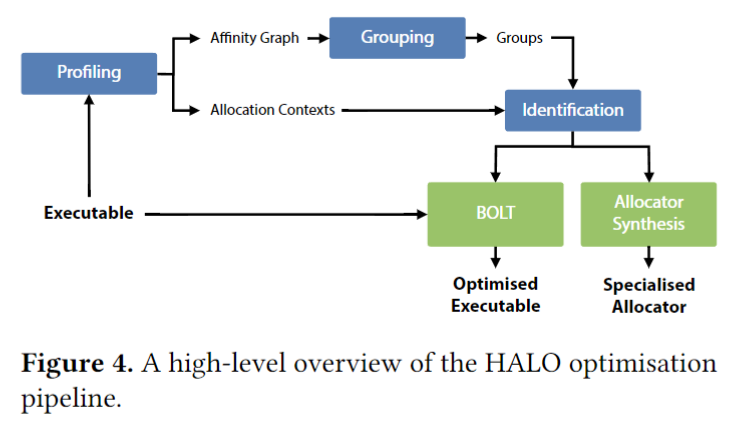
2.1、profiling
HALO 会使用检测工具(instrumentation tool) 生成程序是如何访问堆数据的模型,为了确定分配之间的关系,该工具会对所有的 POSIX 内存管理函数进行调用,以对象粒度来跟踪实时数据。
对于每次分配,该工具会通过调用堆栈跟踪进行分配的上下文,它维护了一个影子堆栈,用来跟踪每个函数的确切调用点(call sites)。
确定了哪些分配是在哪个上下文的之后,然后就要通过程序的访问模式来研究上下文之间的关系。这里会生成成对的亲和图(affinity graph),节点是简化后的上下文,而它的边是带权重的,根据某个固定窗口内,同时访问这些上下文分配的对象数量来设置。
如下图,当工具检测到对堆数据访问时,这次访问就会被加到亲和队列里,图中 ID 代表最近被访问到的数据对象。我们定义一个亲和距离 A,代表两个对象在亲和队列中的大小距离小于 A,则可以认为这两个对象亲和。每当发生访问时,就会去判断与此访问相关的所有对象的亲和关系,然后,如果亲和距离满足,则这两个对象所属上下文的边 edge(context x,context y) 权重递增。(实际还会有一些限制,不做展开)

运行完程序之后,就能得到亲和图信息了。
2.2、grouping
接下来就是如何优化性能了,我们把一些分配的上下文划分成组,以便可以从公共内存区域给每个组的成员进行分配,以提高缓存局部性。
划分组是用简单的贪心算法来进行,实际验证也比其他算法效果更加好。选择合并收益最高的(边权重最大的) 为一组,直到合并收益小于等于 0 时,则认为该组的合并完成。评估公式在合并判断时要对双方有利才为正值,下面的公式简单看看就好。

然后按组开始着色,边的厚度表示权重的大小。

2.3、identification
划分为组后,我们还需要在运行时能识别出这些组,来进行对应的内存分配。这里用到了二进制重写来识别,会根据程序中一些位置的控制流行为来判断。即会生成一个逻辑表达式,基于控制流是否执行了一些特定的调用点,用来判断特定的分配内存操作是否属于一个特定的组。
这里使用了 BOLT(链接后优化技术,之前文章有介绍过) 来进行重写二进制,在每个感兴趣的位置插入了指令,用一个 bit 来标记状态 0/1,代表控制流是否执行过这里。
2.4、allocation
识别到组后,HALO 使用了特定的内存分配器,对该组成员进行特定分配,找到对应的组后,使用 group_malloc 和 group_free 来进行操作。这样就能把同组的成员对象,分配到同一个内存区域,以提高访问的局部性。
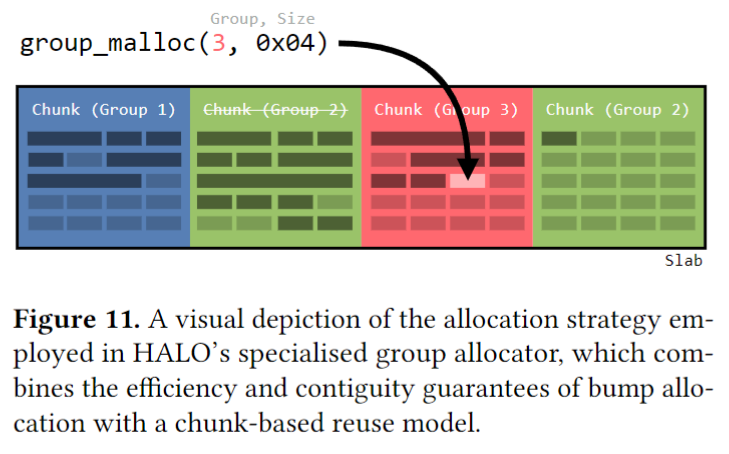
3、结论
HALO 在 BOLT 的基础上,多实现了一项对动态堆内存布局优化的技术,减少了 cache miss,提高了访问的局部性,使用的也是基于 profile 的运行时信息,二进制重写了程序,并且还使用了特定的内存分配方式。
但思辨一下,不是只有好处,程序是会变化的,每次都需要重新基于新的代码生成新的内存布局方式。跟机器学习的术语描述的一样,会有对数据的过拟合和欠拟合。而且目前通用的一些内存分配器比较有完整的生态,也会有一些基于此的优化。
目前 HALO 在网上搜到的资料不多,代码可以在这里找到 Research data supporting “HALO: Post-Link Heap-Layout Optimisation”,没看到应用在什么地方,不过这篇论文也是提供了一个不错的思路。
参考
文章作者 calssion
上次更新 2024-03-17