最近看到两篇不错的文章,是关于编译器做的循环优化,分别是编译器怎么做和开发者怎么协助编译器来做,还挺有趣的,本文的主要内容也来源于这两篇文章。
1、理想的循环体
一个理想的循环体是:
- 只做必要之事。 把一些不必要的、冗余的操作放到循环之外。
- 性能高。 采用更加快速、有效的指令来完成任务。
- 使用 SIMD。 单条指令操作多个数据。
- 良好的 CPU 流水线指令。 避免让 CPU 的某单元空转,应充分利用不同单元(divisor、load unit等)来操作。
- 良好的内存访问局部性。 尽量保证内存访问在同一条 cache line,充分利用局部性。
2、inlining 内联优化
为什么要介绍 inline 内联优化?实际上很多优化操作的前提,是 inline 之后才会出现机会。
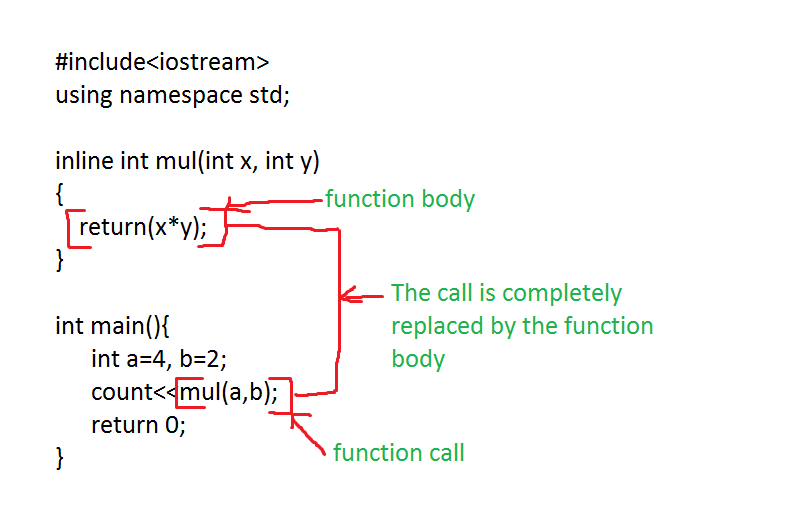
在上图中,mul 函数直接被 inline 成 a * b,由于 a 和 b 的值,并没有在过程中被修改,实际上就可以被直接优化成 4 * 2,最后直接替换为 8。减少计算乘法的指令,优化了性能。
注:需要编译器能够同时看到这两个函数的实现体,因为某些函数为外部引用,编译器看不到其实现,只能临时占位(待链接器补充),也就无从优化。这里先不考虑这些情况。(关于跨模块优化可以看下之前的 LTO 优化的文章)
3、充分利用寄存器
CPU 的寄存器数量是有限的,寄存器访问速度比内存访问速度要快很多。
编译器有寄存器的分配算法(register allocator) 来控制寄存器持有一些变量,其他一些变量就要通过访问内存的方式来读取了。
我们想要尽可能地充分利用寄存器,但也会有一些阻碍这样优化的操作:
- 循环体内使用过多的变量,导致编译器需要把一些变量操作变成内存访问,该问题称之为寄存器溢出(register spilling)。
- 指针别名,使用指针来对变量进行修改,那么相关指令是需要操作到内存,才能真正修改变量在内存中的值。
3.1、使用过多变量问题
在 Intel 平台有特别多的编译器标识(pragma、attribute等),来指导编译器应该如何操作,但是会有局限性,主要是使用 Intel C++ Compiler Classic, 不通用。
其中的一个标识 distribute_point,可以建议编译器把一个大型的循环体,分割为小的。
如果一个循环体里需要操作过多的变量,那么寄存器也无法记载储存这么多变量值,只能通过内存去进行访问了,这也会阻止向量化(vectorization,SIMD,一条指令同时操作多个数据) 的优化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#define NUM 1024
void loop_distribution_pragma2(
double a[NUM], double b[NUM], double c[NUM],
double x[NUM], double y[NUM], double z[NUM] ) {
int i;
// After distribution or splitting the loop.
for (i=0; i< NUM; i++) {
a[i] = a[i] +i;
b[i] = b[i] +i;
c[i] = c[i] +i;
#pragma distribute_point
x[i] = x[i] +i;
y[i] = y[i] +i;
z[i] = z[i] +i;
}
}
|
加上这个标识后,上面代码可能就会被编译器分成两个循环了,看似操作更多了,但是加快了变量的访问速度,同时也保证了更好的 CPU cache,性能得到了提升。
但需要确认的是,确实会发生寄存器溢出问题(register spilling),再去使用,所以这种操作不算通用,一般编译器是能自己进行 loop optimization(循环优化),但取决于优化程度。
3.2、指针别名
指针修改变量,确实是需要操作内存,但有一些指针操作的只是局部的变量,编译器无法保证指针的指向会不会修改到内存,所以也导致无法进行优化。
所以把一些无关的操作,提前设置好,或者对不需要修改的变量,生成一个备份来进行操作,让编译器认为可以安全地把值加载到寄存器当中,从而更加有效地利用寄存器。
(关于这一块,感兴趣的可以看下之前的文章《那些编译器优化盲区 - 1》里的指针别名部分)
4、去除冗余操作
4.1、无用操作(unneeded computation)
1
2
3
4
5
6
7
8
|
void add(int* a, int* b) {
(*a)++;
if (b) (*b)++;
}
for (int i = 0; i < n; i++) {
add(&a[i], nullptr);
}
|
在 inline 之后,编译器可以发现对变量 b 的操作毫无作用,在无用代码删除(dead code elimination) 时可能会删掉。
4.2、固定值的重复操作(loop invariant computation)
1
2
3
4
5
6
|
for (int i = 0; i < n; i++) {
switch (operation) {
case ADD: a[i]+= x * x; break;
case SUB: a[i]-= x * x; break;
}
}
|
在这个循环体当中,实际上 x * x 是没必要反复计算的,因为它在过程中没有任何改变,所以是个可以提前计算好的固定结果。
这种编译器优化,称之为 loop invariant code motion,算是编译器经常会做的基础优化。
但这里面其实还有一个不变的重复操作,那就是用于判断的 operation,实际上,编译器也是可以进行优化的:为判断得到的不同分支操作,创建各自的循环体版本。这种优化称之为 loop unswitching。
1
2
3
4
5
6
7
8
9
10
|
auto x_2 = x * x;
if (operation == ADD) {
for (int i = 0; i < n; i++) {
a[i] += x_2;
}
} else if (operation == SUB) {
for (int i = 0; i < n; i++) {
a[i] -= x_2;
}
}
|
但对于 loop unswitching,编译器是很谨慎的,因为这会导致代码量暴增,所以如果确认这么做更好的话,还是开发者手动修改更稳妥。
5、使用性价比高的指令
某些指令的操作会耗比较多的 CPU 时间,那么采用可替代性的、性能更好的指令对循环体会更好。
像一些乘法或除法,是可以用移位操作来替代的。
一种比较常见的编译器优化是 induction variables(变量归纳),比如一些线性的操作 i * 3 是可以像下面这样从 1 优化成 2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 1
for (int i = 0; i < n; i++) {
a[i] = i * 3;
}
// 2
tmp = 0;
for (int i = 0, int tmp = 0; i < n; i++) {
a[i] = tmp;
tmp += 3;
}
// 3
class MyClass {
double a;
double b;
double c;
};
for (int i = 0; i < n; i++) {
a[i].b += 1.0;
}
|
而第 3 个代码,b 是在固定的偏移量 8,所以 a[i].b 的地址,编译器会转换成 a + i * sizeof(MyClass) + 8,而且更进一步,像第 2 个代码一样,每次加上偏移量 sizeof(MyClass) 就好了,而不用每次都使用乘法操作。
6、循环展开(loop unrolling)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// 1
// a[i] = b[i/2]
for (int i = 0; i < n; i++) {
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
}
// 2
// 有效地减少了 load 的次数
// 因为每两次循环 load 出来的值是一样的
for (int i = 0; i < n; ) {
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
i++;
store(a + i, b_val);
i++;
index = i / 2;
b_val = load(b + index);
store(a + i, b_val);
i++;
store(a + i, b_val);
i++;
}
|
循环展开可以有效地降低循环体的开销,而且还可以带来一些额外的优化(去除冗余操作等),甚至可以的话,使用自动向量化计算(像 SIMD 单条指令同时操作多个数据)。
但循环展开也存在一些劣势:增加了内存的负担,特别是对指令 cache 和 CPU 的译指单元不友好,对现代 CPU 的乱序执行(out-of-order)是负面优化。
在早期,编译器还在发展阶段,开发者手工进行循环展开确实有效;但是现在这么操作是会阻碍编译器的其他优化的,最好还是采用编译器所提供的能力,比如 clang 提供了 pragma clang loop unroll factor(n) 来指明循环展开的因子(次数)是多少。
7、循环流水线(loop pipelining)
指令之间的依赖关系(instructions dependencies) 会限制 CPU 的运行速度,比如有两条指令 A 和 B,而 B 指令的操作数是从 A 指令的结果拿的,那么 B 就依赖于 A 了。最简单的案例就如 c[i] = a[i] + b[i]。
1
2
3
4
5
6
|
for (int i = 0; i < n; i++) {
val_a = load(a + i);
val_b = load(b + i);
val_c = add(val_a, val_b);
store(val_c, c + i);
}
|
有一种编译器优化 loop pipelining 可以打破这种依赖的链路,实际上就是把每次循环里的操作分离,比如计算上一次的结果、加载下一次的数据,这样就不会出现需要等待结果的情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
val_a = load(a + 0);
val_b = load(b + 0);
val_c = add(val_a, val_b);
val_a = load(a + 1);
val_b = load(b + 1);
for (int i = 0; i < n - 2; i++) {
store(val_c, c + i);
val_c = add(val_a, val_b);
val_a = load(a + i + 2);
val_b = load(b + i + 2);
}
store(val_c, n - 2);
val_c = add(val_a, val_b);
store(val_c, n - 1);
|
但在现代乱序执行(out-of-order)的 CPU 并没有很好的收益,因为它们可以先执行其他指令,而不需要等待。
8、向量化(vectorization)
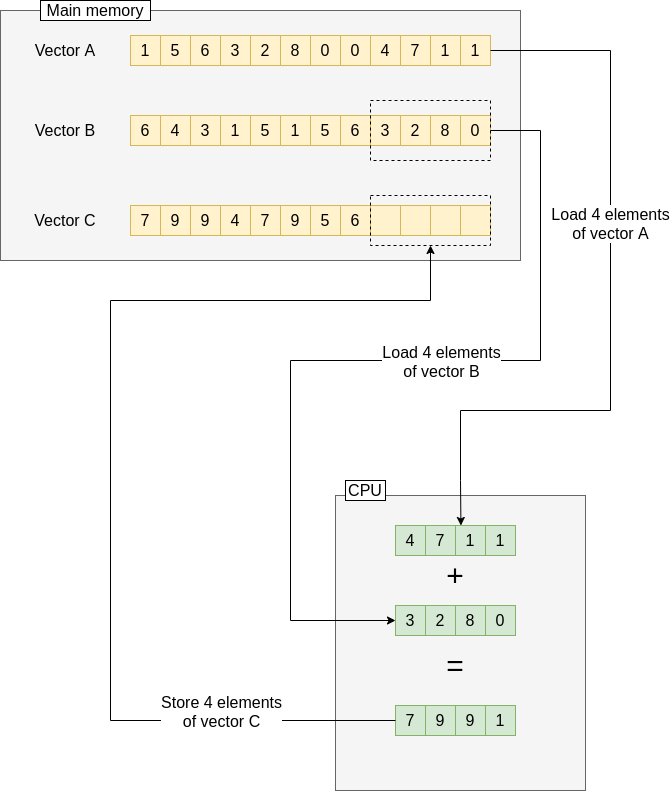
向量化其实是利用了 CPU 里的 vector registers,这个寄存器可以同时持有同种类型的多个变量。CPU 也提供了相关的指令,来在这个寄存器中一次性操作所有的数据。相当于利用并行,来提高了性能。一般是用 SIMD(single instruction multiple data) 的语句和指令。
1
2
3
4
5
6
|
for (int i = 0; i < n; i+=4) {
double<4> b_val = load<4>(B + i);
double<4> c_val = load<4>(C + i);
double<4> a_val = add<4>(b_val, c_val);
store<4>(a_val, A + i);
}
|
但向量化是有一定的前提条件的:
- 类型简单。 内置类型 int、double 等,或小型的类、结构体。
- 循环是线性地遍历数组。 增量为 1 最好,否则会带来内存瓶颈(memory wall)。
- 循环是可计算的。 比如 +1,而不是判断字符串之类的,因为不知道何时才会结束。
- 循环之间没有依赖关系。 比如
A[i] = B[i] + C[i] 没有依赖,而 A[i] = B[i] + A[i - 1] 会依赖上次结果。
- 没有指针别名。 比如
double * C = A - 1,因为不知道 C 的指向,所以不能排除存在依赖关系的可能。
所以 SIMD 同样也会存在劣势,上面的前提条件可以说是劣势,还有就是对分支状态的管理。
SIMD 对分支状态是无感知的,一般是用位标识(bit masking,位掩码),比如下面案例,就会导致无效计算的存在。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
for (int i = 0; i < N; i++) {
if (A[i] >= 1) {
A[i] = A[i] - B[i];
}
}
// 上面代码被转换如下
vec4 ones = { 1, 1, 1, 1 }
for (int i = 0; i < N; i+= 4) {
vec4 A_tmp = load4(A + i);
vec4 B_tmp = load4(B + i);
// Calculates the result for each element in the vector,
// even those that won't be needing it.
vec4 res = sub4(A_tmp, B_tmp);
// Calculates the predicate, i.e. those elements of the
// vector that will load the new value
vec4<bool> greater_than_one = operator>=(A_tmp, ones);
// Conditional load: loads the new value only for those
// elements where greater_than_one is true.
A_tmp = load_if_condition(A_tmp, greater_than_one);
store4(A_tmp, A + i)
}
|
9、不常见的优化
9.1、loop interchange
loop interchange 是为了提高内存访问的局部性(提升 cache 命中率)。
1
2
3
4
5
|
for (int i = 1; i < LEN; i++) {
for (int j = 0; j < LEN; j++) {
b[j][i] = a[j][i] - a[j - 1][i];
}
}
|
比如上面代码是先进行对每一行的操作,loop interchange 优化可以把这样的操作转换成:先对每一列进行操作。
这个优化在 LLVM 是可以手动开启的:-mllvm -enable-loopinterchange。
9.2、loop distribution
loop distribute 是把一个复杂的循环分割成多个,跟 3.1、使用过多变量 的介绍是一样的,这样操作就有机会支持向量化、避免寄存器溢出问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
for (int i = 0; i < n; i++) {
a[i] = a[i - 1] * b[i];
c[i] = a[i] + e[i];
}
// loop distribute
for (int i = 0; i < n; i++) {
a[i] = a[i - 1] * b[i];
}
for (int i = 0; i < n; i++) {
c[i] = a[i] + e[i];
}
|
在 LLVM 同样可以手动开启:-mllvm -enable-loop-distribute。
同时也有编译器标识可以设置:pragma clang loop distribute(enable)。
9.3、loop fusion
有循环分割,那就会有分支融合 loop fusion。loop fusion 用于合并两个独立的循环体。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// Find minimum loop
auto min = a[0];
for (int i = 1; i < n; i++) {
if (a[i] < min) min = a[i];
}
// Find maximum loop
auto max = a[0];
for (int i = 1; i < n; i++) {
if (a[i] > max) max = a[i];
}
// loop fusion
for (int i = 1; i < n; i++) {
if (a[i] < min) min = a[i];
if (a[i] > max) max = a[i];
}
|
10、开发者应该如何协助编译器?
看完上面的编译器优化,那么也就知道有很多情况下,会导致编译器无法有效地进行优化,其中两大杀手可以说是函数调用和指针别名了。作为开发者,有什么方式来协助(hint)编译器来进行有效的优化?
10.1、function calls
1
2
3
4
5
6
|
for (int i = 0; i < n; i++) {
...
if (debug) {
printf("The data is NaN\n");
}
}
|
对于函数调用,编译器会担扰其更改了内存状态,导致循环体出现变化。在上面的代码中,如果变量 debug 是全局变量、堆分配的内存、类变量的话,都是有可能改变这个变量的状态的。如果编译器知道这个状态是不会被改变,那么就可能进行 loop unswitching 优化(本文 4.2 有介绍)。
破局之道就在于,让编译器认为函数调用并不会更改这个状态,最好的方式就是给这个变量做一个备份。
1
2
3
4
5
6
7
8
|
bool debug_local = debug;
for (int i = 0; i < n; i++) {
...
if (debug_local) {
printf("The data is NaN\n");
}
}
|
还有很多情况下,是需要 inline 了函数调用之后,才能看到优化机会的(本文 2 有介绍)。
10.2、pointer aliasing
指针别名导致没法用寄存器去持有数据,而只能够通过内存去操作,同时也阻碍了向量化的优化(本文 8 有介绍向量化的前提条件,之前的文章《那些编译器优化盲区 - 1》指针别名部分也有介绍),因为潜在依赖的可能性,编译器必须兼容所有的情况。
1
2
3
4
5
6
7
8
9
|
for (int i = 0; i < n; i++) {
b[i] = 0;
for (int j = 0; j < n; j++) {
b[i] += a[i][j];
}
}
// 设想
double** a = new double*[n];
double* b = new double[n];
|
这里 a 和 b 是有可能指向同一个对象的,这样就会导致有依赖关系。
作为开发者,如果是明确没有这种依赖关系的话,可以使用编译器提供的关键字 __restrict__ ,指明这个 变量/指针 是独立的。
1
2
3
4
5
6
7
8
|
for (int i = 0; i < n; i++) {
double sum = 0;
double* __restrict__ a_row = a[i];
for (int j = 0; j < n; j++) {
sum += a_row[j];
}
b[i] = sum;
}
|
10.3、attribute
如果处于不同的编译单元(translation unit),会导致函数没能进行 inline 优化。但 gcc 和 clang 还是提供了 attribute,让开发者可以提醒编译器进行相应的优化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// fun.h (暴露给使用方的头文件)
// 方案 1
int square(int num);
// 方案 2
int __attribute__((pure)) square1(int num);
// fun.cpp (不重要,外部只能看到头文件,这里只做展示)
#include "fun.h"
int square(int num) {
return num * num;
}
// use.cpp (模拟使用方)
#include "fun.h"
int use_fun(int num) {
int n = 0;
for(int i = 0; i < 5; ++i) {
n += square(num);
}
return n;
}
|
attribute pure 代表函数的返回值(结果),只会依赖于函数的入参和内存的状态。从而向编译器保证它不会写内存,也不会调用其他函数。
这样,外层对于 pure 函数就可以进行优化,比如省略对于以相同入参调用相同函数的次数,或者当结果没被用到时去掉函数调用。
来看看上述案例的汇编代码是怎样的?亲测有效!不需要看明白汇编代码,看个大概就知道编译器所做的优化了,正是省略对于以相同入参调用相同函数的次数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
// g++ fun.h -c use.cpp -O3
// 方案1:int square(int num);
stp x20, x19, [sp, #-0x20]!
stp x29, x30, [sp, #0x10]
add x29, sp, #0x10
mov x19, x0
bl __Z6squarei ; square(int)
mov x20, x0
mov x0, x19
bl __Z6squarei ; square(int)
add w20, w0, w20
mov x0, x19
bl __Z6squarei ; square(int)
add w20, w0, w20
mov x0, x19
bl __Z6squarei ; square(int)
add w20, w0, w20
mov x0, x19
bl __Z6squarei ; square(int)
add w0, w0, w20
ldp x29, x30, [sp, #0x10]
ldp x20, x19, [sp], #0x20
ret
// 方案2:int __attribute__((pure)) square1(int num);
stp x29, x30, [sp, #-0x10]!
mov x29, sp
bl __Z6squarei ; square(int)
add w0, w0, w0, lsl #2
ldp x29, x30, [sp], #0x10
ret
|
还有另外一个 attribute const,代表函数的返回值(结果),只会依赖于函数的入参。所以 const 也是 pure 的,不过 const 更进一步,编译器对于未能 inline 的 attribute const 函数(前提是函数可见、非外部引用),可以直接在编译时计算好结果,然后代替函数调用。
参考
memory wall
Crash course introduction to parallelism: SIMD Parallelism
distribute_point
Intel C++ Compiler Classic
Loop Optimizations: how does the compiler do it?
Loop Optimizations: taking matters into your hands
Optimization without Inlining
Make your programs run faster: avoid function calls

