Dynamo: 二进制指令动态优化执行框架
文章目录
看到一个有趣的程序动态优化的框架 Dynamo,可以很好地优化程序性能,本文简单介绍一下。
1、动态优化
动态优化(dynamic optimization) 指在运行时对程序二进制做优化。动态优化不同于动态翻译或 JIT(Just In Time),动态优化的输入是二进制指令码,没有翻译/编译源码的过程。动态优化和编译器静态优化可以互为补充,动态优化可以视为基于程序最近几分钟运行行为的优化。
静态优化基于采样数据(sampling-PGO) 需要定时器中断信号(timer interrupt signal) 实现,而且很难发现全部的高频路径。而基于插桩获取数据(instrumentation-PGO) 操作流程麻烦,插桩后影响性能,且获取的数据可能在后续编译出现匹配失效的情况。
而本文要介绍的 Dynamo,实现了线上的 profiling,直接在线上采集数据和消费,且不需要进行提前插桩,使用翻译器来完成对程序行为的探测。
2、Dynamo
Dynamo 便是其中一种,在软件层面实现,不依赖于编程语言、编译器、操作系统或硬件的支持。二进制指令会由 Dynamo 翻译执行,相当于实现了一个虚拟机。Dynamo 由解释器收集 profile/trace 信息,并直接在线上(on-the-fly、online) 消费,选择高频的执行路径优化,优化会交给低性能损耗的优化器操作,并且生成到 code cache 当中。随后执行到这些路径时,会执行 code cache 中的版本,从而带来性能上的提升。
完全运行在翻译器之上,而不是采取像 JIT 一样频繁从不同的 context(上下文) 切换,对于内存和底层处理器的寄存器的消耗更小,减少分支跳转时的复杂度。
2.1、设计
Dynamo 设计目标主要有:
- 性能(performance)。至少要跟优化后的源码直接运行的性能一致。一般翻译器会采用 caching 频繁执行的指令,只要时间足够,会变得性能更好。
- 透明(transparency)。不改变程序运行的原有行为,包括二进制加载地址、image 的内容等。不改变二进制产物,不会提前插桩,所有 profile 的生成和消费都在同一次的运行当中。
- 紧凑(compactness)。不占用过多的内存消耗等。
- 可探测(instrumentability)。可以开关程序探测功能,即 profiling。
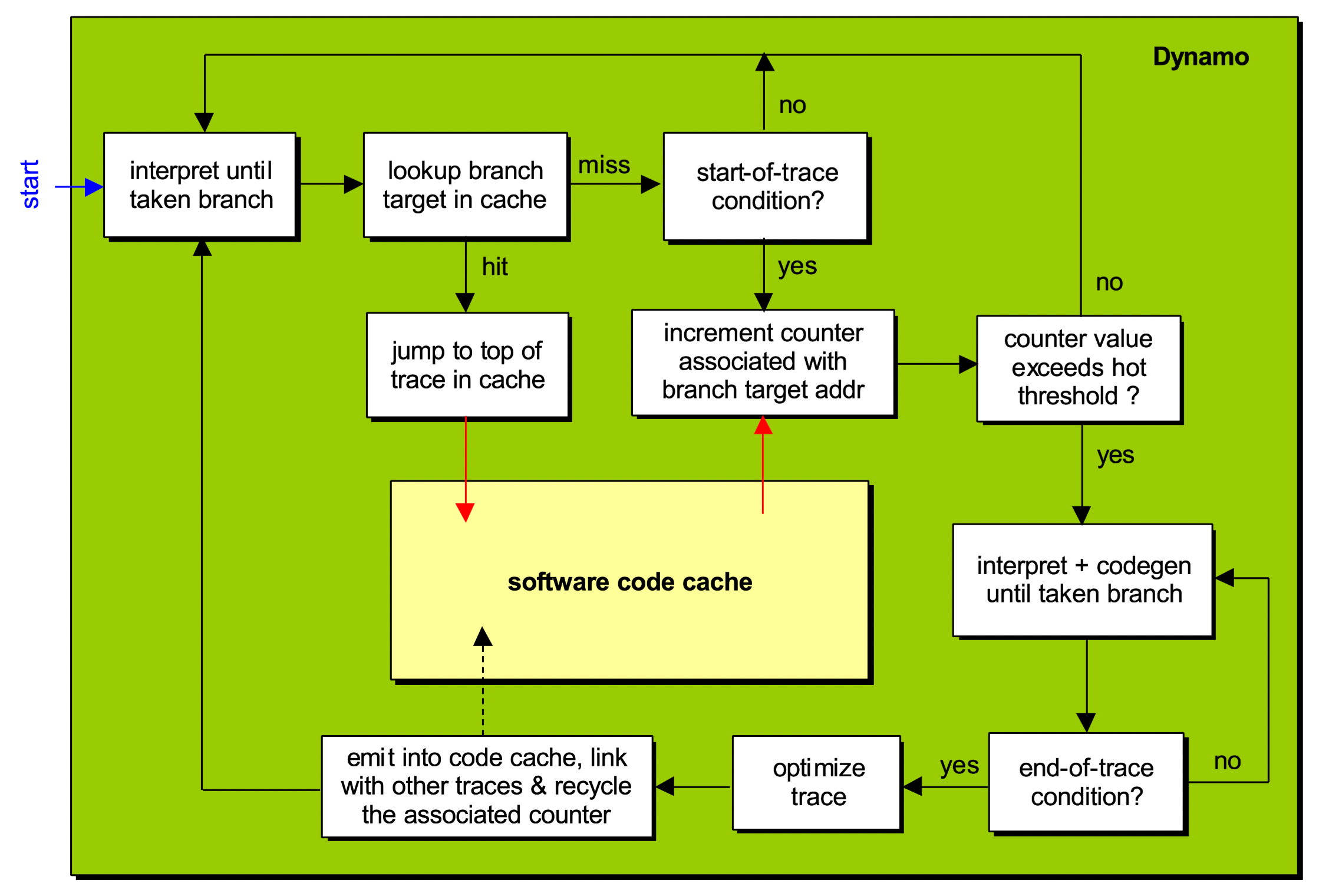
这里的翻译器(interpreter) 是机器码指令翻译,在软件层面实现,用来监察程序行为,而不需要对二进制提前插桩。也由于翻译的存在,Dynamo 可以增加相关满足路径跟踪(trace) 的指令地址的计数器。
如果计数器大于预设的热度阈值(hot threshold),那么翻译器会更新其状态并进入代码生成阶段。这时候原始指令会放到缓冲区(buffer) 中,当 trace 状态结束,缓冲区中的指令内容会被优化器进行优化,之后会放到一个可执行的单元中,称为 fragment,递交给链接器,链接器把 fragment 的代码生成到 code cache 当中。
每当翻译器遇到一个分支跳转(taken branch) 的指令时,它会查找 code cache 看是否存在 tag 与目标 PC 值一样的 fragment,如果命中,则执行 fragment 中的代码。
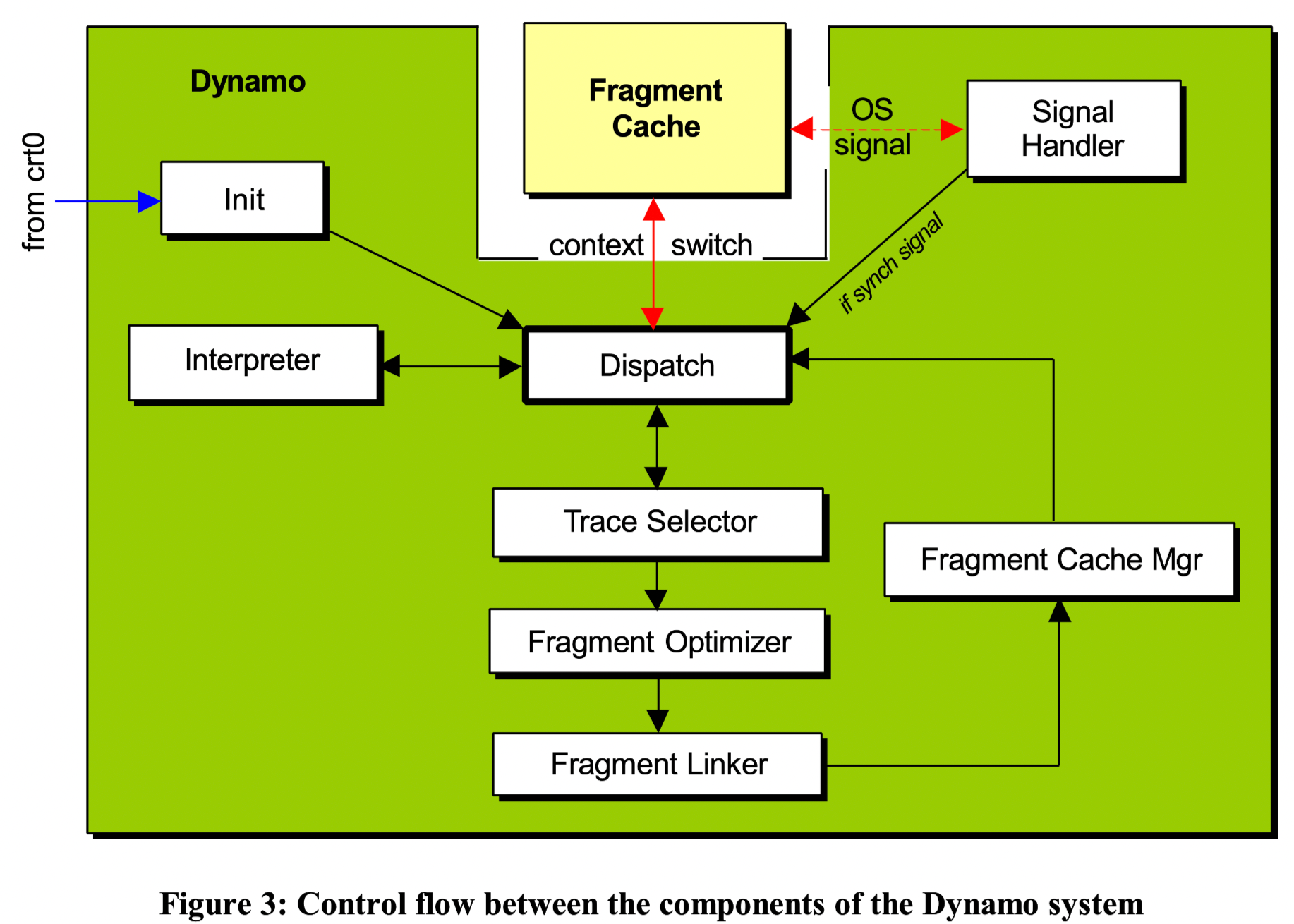
优化器基于翻译器拿到的运行时信息,可以进行冗余消除(redundancy elimination)、强度削减(strength reduction,比如替换高消耗的 b = a * 4 为 b = a << 2)、inlining、寄存器分配、分支跳转指令重排、常量传播、常量折叠等优化。静态分析优化器更倾向于全局的优化,进行一些优化时会有限制(如 inline 时会考虑体积大小、需要从全局考虑寄存器分配等)。而有了运行时信息,我们可以动态地进行很多局部优化,这也正是为什么动态优化和静态优化可以互为补充。
2.2、性能
Dynamo 保持了良好的性能,主要是基于三个特征:
- 轻量级的 trace 策略(hot trace selection scheme)。基本概念是一个进程地址执行频繁,那么由于局部性,其连着的地址也很有可能是 hot 的,所以 Dynamo 不用复杂的 profiling 方案,只在特定的地址记录计数器(比如向后跳转的目标地址,一般是循环中的循环点,targets of backward taken branches)。
- 使用了动态 trace 的数据作为运行时优化。为降低消耗,每个 trace 只会被使用一次,Dynamo 的优化器也不会进行指令调度的操作,因为静态优化应该已经进行过了。
- 良好的 code cache 设计(software code cache design)。不同于 cache 越大越好,Dynamo 的代码 cache 使用 300KB 的小体积占用,而且会基于工作流提前进行 cache 刷新,而不是在发生 cache miss 时。
Dynamo 会监控执行 code cache 和 Dynamo 自身代码的时间比率,如果比率低于某个阈值,或者遇到指令翻译无法处理的情况,Dynamo 会退出翻译执行(bail out),让输入的程序二进制指令直接在处理器上执行。但一旦退出,就无法在本次运行当中恢复了,为防止数据异常,所以会有个最小的至少的运行时间再进行判断。
2.2.1、trace selection 策略
trace selection 策略即如何选择要追踪的点,前面说过,Dynamo 采用的是只在特定的地址记录计数器(比如向后跳转的目标地址,一般是循环中的循环点,targets of backward taken branches)。这种策略称为 SPECL(Speculative trace selection)。
由于这种轻量级的 trace selection 策略,就需要考虑污染问题和代码重复问题了。
污染问题是冷代码被放置到了 fragment 当中,因为存在 trace 开头的几条指令执行频率高,结尾的很少执行。比如执行到中间退出去了。这种对于代码局部性造成了负面的影响。而如果选择代码块作为一个 trace 就不会有这种问题。
代码重复问题是一个 trace 包含了另一个 trace 在里面,减少 trace 的代码长度可以有效降低重复度。代码重复问题损坏了 fragment 当中的局部性,减少了可优化的机会。
实际上还有很多策略,但文章里通过几种策略的对比,发现 SPECL 策略的综合性能表现更好。
2.3、特殊处理
对于系统调用(system call),Dynamo 自己注册信号处理,拦截所有的信号处理,由内核(kernel) 传递控制给 Dynamo,然后程序的 handler 代码会在 Dynamo 控制下执行。
某些情况会特别复杂,可能需要违反设计原则的透明和性能要求,或者干脆退出翻译直接执行。比如调用 fork 或 exec 时。
对于自修改代码(self-modifying code),是写在自己的 text 段里的,会在运行时修改内容。这样就会导致 Dynamo 的 code cache 失效,还好在大多数现代微处理器中,修改 text 段内容会同步 I-cache(instruction cache),强迫其重新从内存中读取更新,这时候 Dynamo 检测这样的 flush 操作指令,立即刷新整个 code cache,重新生成新的 fragment。
2.4、执行控制
由于指令需要在 Dynamo 控制下翻译执行,所以 Dynamo 首先需要获得程序的执行控制(gain control),但 Dynamo 还需要遵守透明的设计要求。
有以下的一些方法:
-
修改内核加载器(kernel loader)。
- 把 Dynamo 编译成动态库,然后由内核加载器加载到应用程序的 image 当中,然后加载器会调用 Dynamo 的入口(entry point),可以比程序的主入口(main entry point) 更早。
- 优点:对用户透明。
- 缺点:需要修改操作系统来支持。
-
使用 ptrace 连接(attach) 到应用程序中。
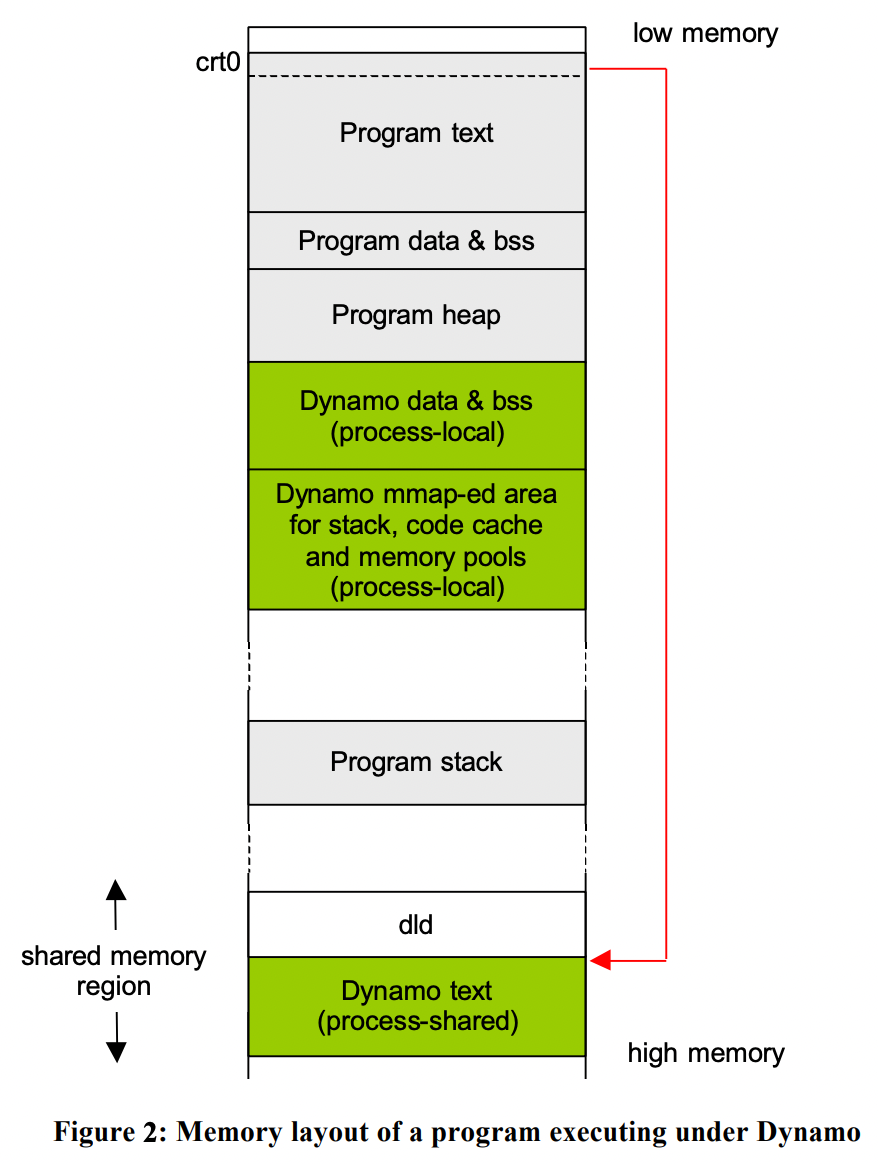
- ptrace 可以让一个进程控制另一个,通常是调试器使用。那么 Dynamo 可以作为一个独立的进程通过 ptrace 去连接到应用程序,运行直到 crt0(程序二进制 image 的顶层 start up 执行代码,crt0 是连接到 C 程序上的一组执行启动例程,它进行在调用这个程序的主函数之前所需要的任何初始化工作) 调用程序主入口。应用程序的执行会被挂起,然后 Dynamo 获取程序指令并自己执行。
- 优点:对用户透明(除了创建了新的进程)。
- 缺点:依赖于 ptrace,很多操作系统并不支持。
-
新建一个扩展了程序代码段(text segment) 的可执行文件。
- 应用程序的可执行文件可以被复制到任意的位置,然后代码段可以扩展 Dynamo 的代码。然后 crt0 调用的 start 符号会指向 Dynamo 的入口。执行新的可执行文件,旧的程序代码可以加载到之前的同样的地址,Dynamo 会在应用运行前获取到执行控制。
- 优点:不需要修改内核,不依赖操作系统,单纯的用户内存空间的解决方案。
- 缺点:复制文件操作的消耗,对原可执行文件进行了修改。
-
使用自定义版本的 crt0。
- crt0 用来执行初始化代码,通常由
crt0.s汇编文件创建,链接到可执行文件当中。内核加载器加载完 image 后,会把执行控制转移给 crt0,crt0 会优先映射动态链接器 dld。dld 会加载程序引用的动态库,那么我们自定义的 crt0 版本可以映射编成动态库的 Dynamo,优先执行 Dynamo 的入口。 - 优点:不需要修改内核,不依赖操作系统。
- 缺点:需要重新进行链接操作,要不就得用自定义的 dld。
- crt0 用来执行初始化代码,通常由
文章中,是假设采用第四种方法来启动 Dynamo。
2.5、优化器
对于高频 trace 会在 fragment 中进行优化,这时的优化器相当于是一个特定路径优化器(path- specific optimization),因为它只针对 trace 范围的代码进行优化。
动态优化只关注局部范围的代码,没法更全面地考虑和优化,但比起静态优化从全局分析要简单不少,不过挑战是输入为可执行二进制代码,没有很多像变量类型这种信息。
为什么动态优化可以对已优化过的二进制继续优化?
-
局部冗余的出现。
- 静态优化基于代码膨胀问题可能不进行 inline 操作,而且会有消除代码中连接点(join point) 的副作用,对于静态优化而言是不安全的。
- 而动态优化因为是在运行时,动态链接的代码也是可用有效(available) 的了,有了 inline 和 superblock formation (superblock 由一个入口和多个出口组成的连续基本块),就可以对局部冗余进行处理。
-
寄存器分配优化。
- 对于跨越了基本块的单个数组的使用,静态优化由于需要从全局寄存器考虑分配,导致通常不会在同一个寄存器保存对该数组的使用,导致可能生成冗余的加载指令。
- 而动态优化如果在运行时发现对这个数组的高频使用,就可以进行局部优化寄存器分配策略。
-
动态库的使用。
- 动态库在静态优化时,通常只有声明,生成对引用的 PLT(Procedure Linkage Table) 信息和访问的 stub,没有足够的信息来进行静态优化。
- 而运行时对动态库的调用补全了这部分信息,对动态库代码联合主工程代码进行优化。
在把 trace 放置到 fragment 之前,会把二进制代码转换成一种基于图的 IR(Intermediate Representation),这是一种接近机器码级别的 IR。有了 IR,就可以执行一些分析和优化的 pass 了。
3、扩展
最近看到一个依赖 LLVM 的类似的项目 DRTI(Dynamic Runtime Inlining),用来支持 C/C++ 的动态优化。
不过它是把源码编译生成的 bitcode(中间格式 IR 的一种) 编码进二进制产物当中,这样运行时就可以直接对其重编拿来使用了。
参考
文章作者 calssion
上次更新 2025-12-08