C++ 虚函数优化探索简介
文章目录
看了 C++ 的虚函数的一些文章,对于其性能消耗的优化思路整理了一下。
1、开销
对于虚函数,编译器可以通过关键字 virtual 识别,并为它们创建虚表,虚表保存着指向函数地址的信息。当一个具有虚函数的对象(object) 被创建时,编译器也会为它创建指向虚表的虚指针。
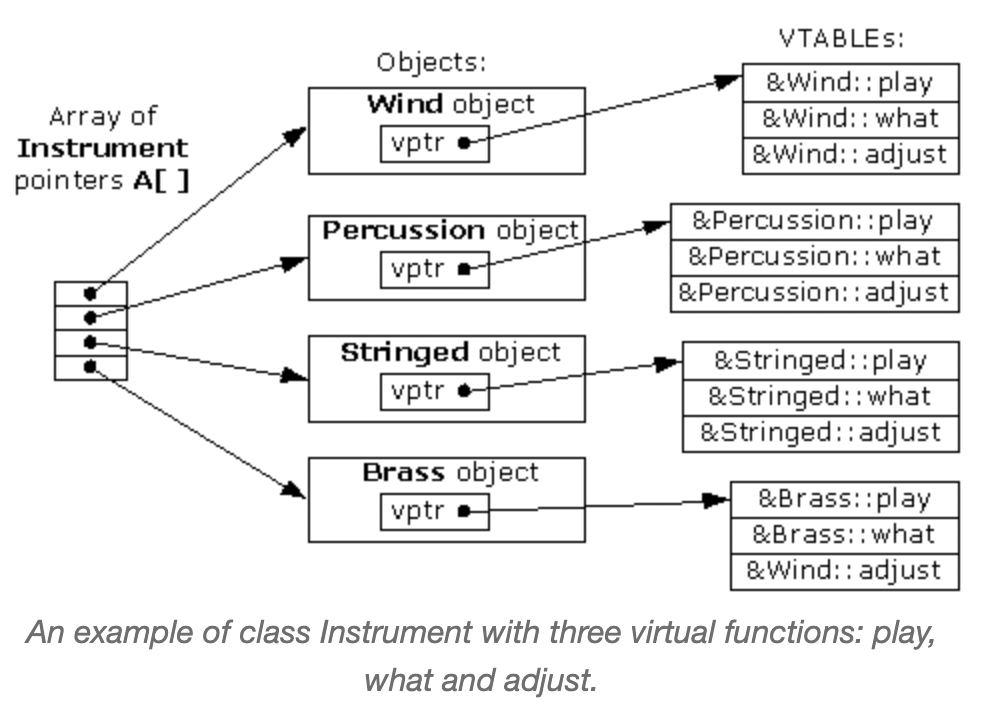
所以要访问到对应的虚函数,每次执行需要先解引用虚指针,偏移到虚表对应函数位置,然后调用。虚函数的开销主要体现在:
- 由于这个操作需要在运行时完成,所以虚函数没法像普通函数一样被 inline,同时也就失去了一些优化机会(inline 后可以进行更多的优化,如常量传播)。
- 现代 CPU 在进行分支跳转前会进行分支预测,对于虚函数而言,硬件在很晚的时机才会知晓要跳转的位置,这可能会导致存在分支预测失败的额外开销。
- 多次调用不同实现的相同符号的虚函数,对 cache 不友好。

根据性能测试结果,文章作者给出了以下建议:
- 合理安排对象的内存位置。带来更好的局部性。
- 尝试把一些小的函数脱虚(变成普通函数调用一样)。小函数的调用开销比执行更高。
- 把数组里的对象先按类型排好序。这样对 cache 会更友好。
2、优化
2.1、strict-vtable-pointers
-fstrict-vtable-pointers 是一个编译器参数,用来向编译器保证在对象的生命周期内,虚指针是固定不变的。这样编译器就不需要多次对虚指针解引用了,对于执行频率高的虚函数和分支预测可能都有一定的优化。
先看一个例子,在正常的虚函数调用下,每次虚函数调用之前,都会需要指令先解引用虚指针:
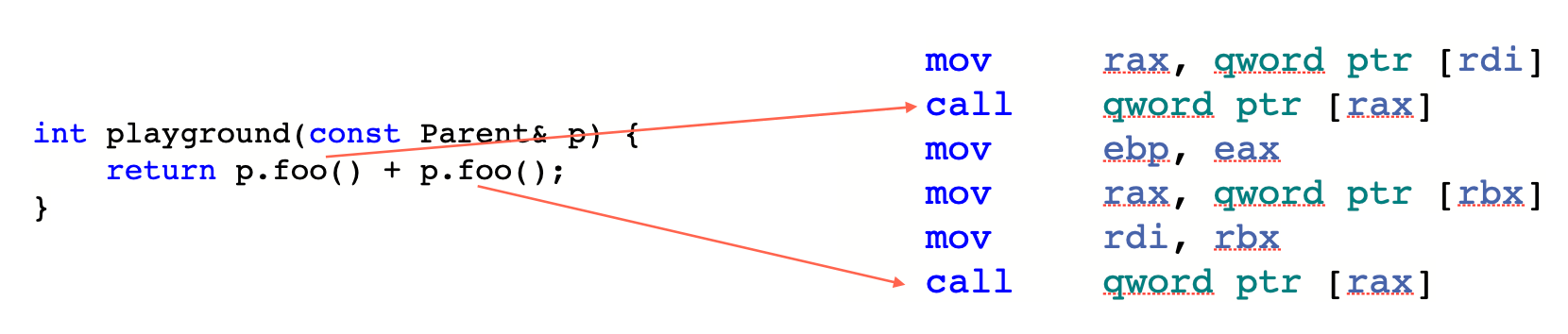
加上 -fstrict-vtable-pointers 后就不需要重复解引用虚指针了,因为我们向编译器保证了虚指针不会中途被改变。

2.2、multivector
multivector 是不同类型数组的集合,声明类型为 template <typename... Types> std::tuple<std::vector<Types>...>,按类型来划分到不同的容器中,实际上就是借助 template 来消除虚函数动态派发的操作,同时也更好地满足局部性。(点链接查看具体数据结构实现)
|
|
还有把运行时多态改造成在编译期解析的方式,称之为 CRTP(Curiously Recurring Template Pattern)。如果模版看起来还理解吃力的话,可以用之前推荐过的工具 c++ insight 先解析一遍。
|
|
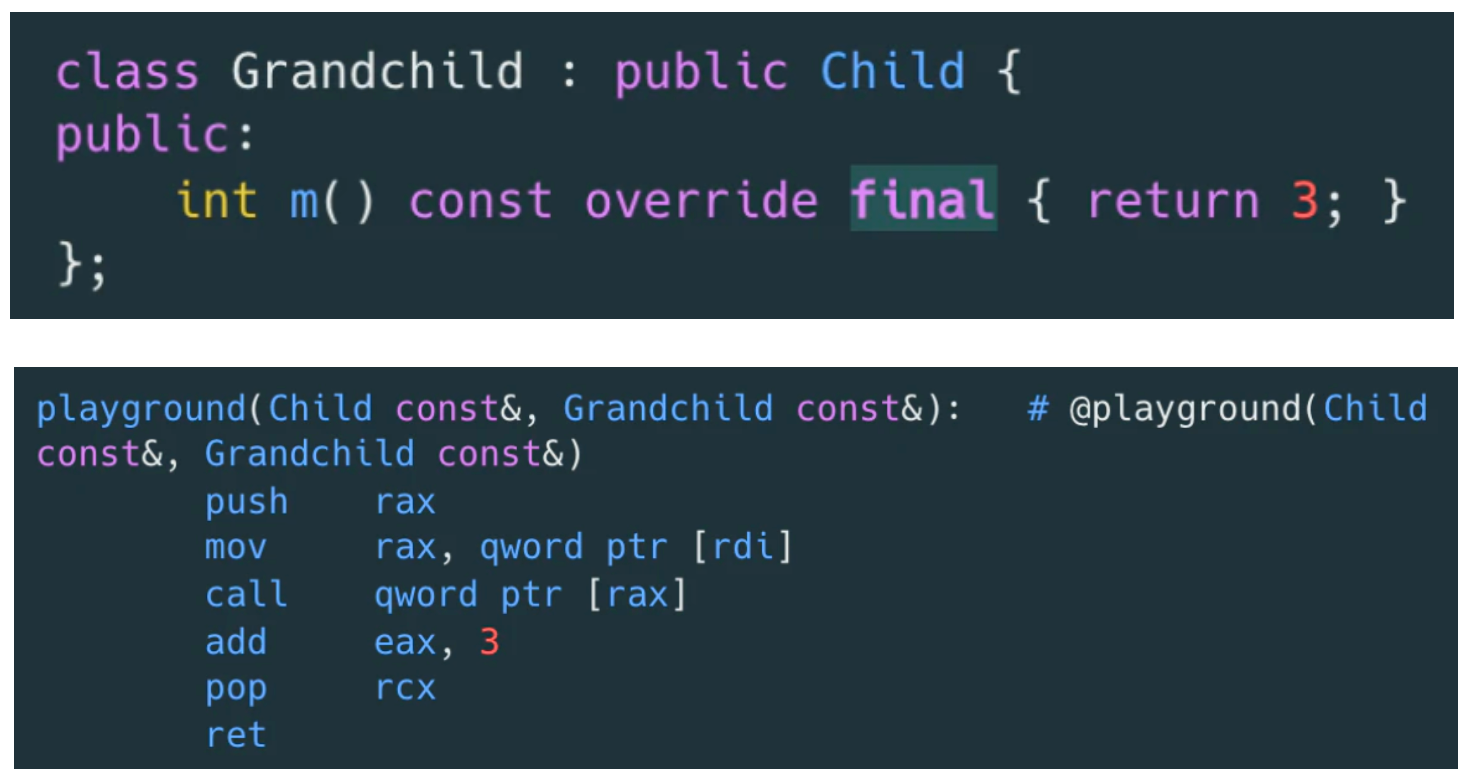
2.3、final override
来看个具体的函数调用的案例:
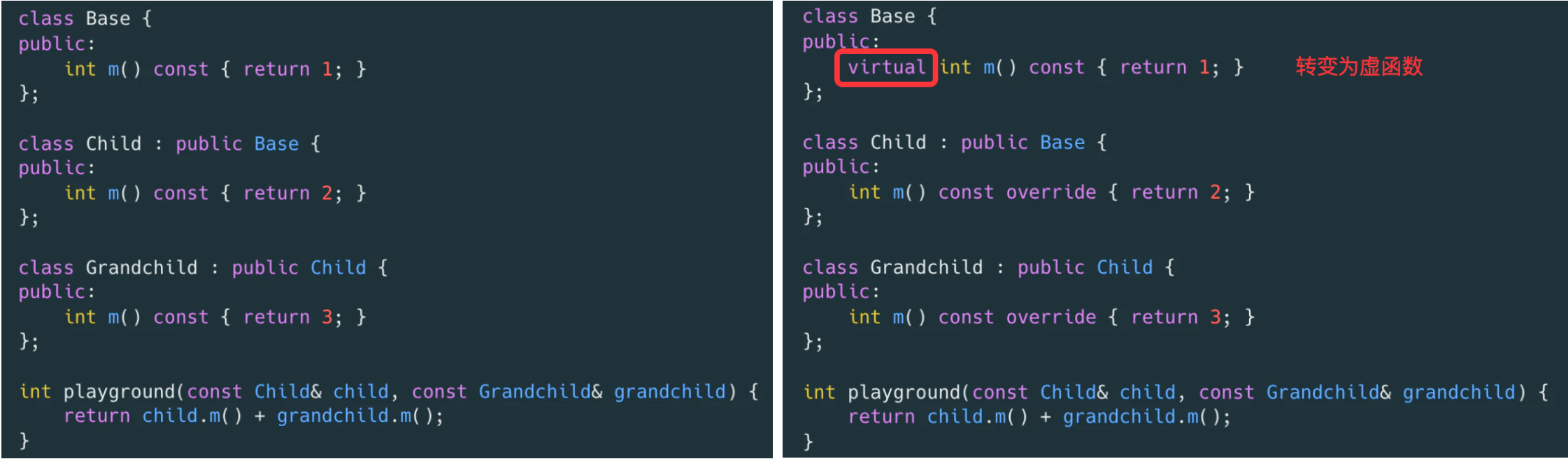
可以直接从它们的二进制指令看出区别:
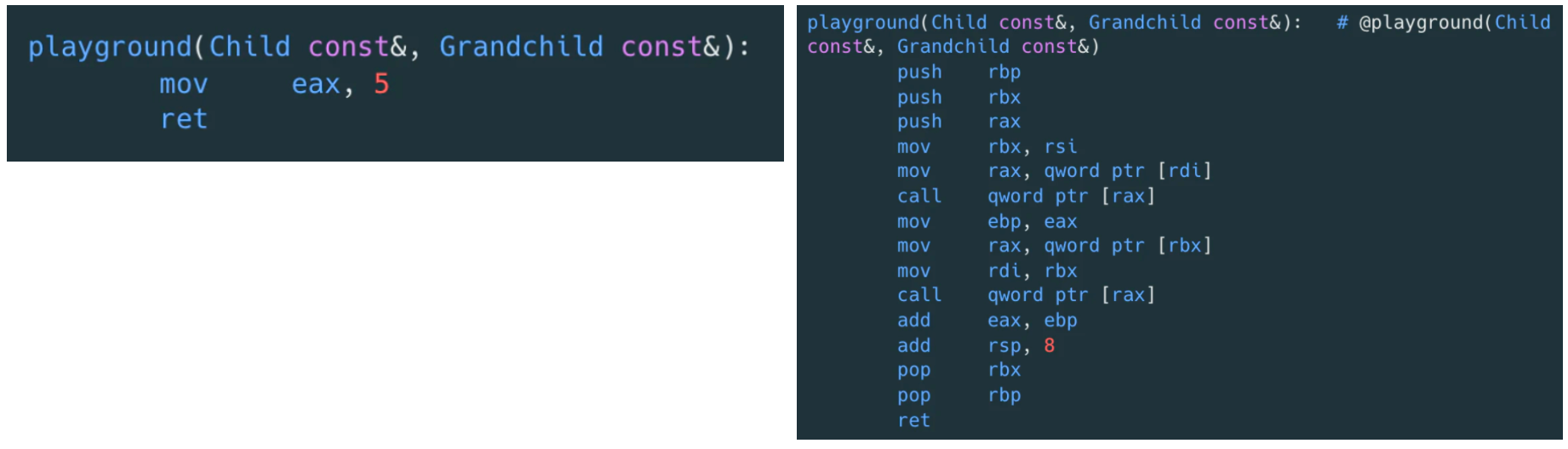
实际上对于 playground 函数的参数,在继承链上,如果我们确认 Grandchild 类型不会扩展子类,或者某个函数不会被重写了,则可以通过 final标记虚函数表示该函数不会有重写了。编译器就可以用直接函数调用来替代虚函数调用了,同时可能带来 inline 等优化。
final 也可以用在对象上:

2.4、Speculative Devirtualization

字节有篇文章也讲到这个的原理,有点像分支预测一样,把一个大概率调用的虚函数提前预测判断,是的话就直接调用,否则用指针间接调用(可以结合 PGO 的 profile 信息辅助判断)。
|
|
虽然增加了指令,但实际上只是一个地址比较的指令,而且直接调用可以被优化成 inline,有更多的后续优化机会,这里是优化了 indirect call 的消耗。但预测失败是可能导致负优化的,所以需要结合 PGO 的 profile 信息进行操作(Indirect Call Promotion)。
2.5、WHOLE PROGRAM OPTIMIZATION
知晓全部的继承链图信息是关键,使用 LTO 是其中一种方式,在链接期同时也具备了链接信息(internal、external 等),可以做 devirtualization 的操作。

2.6、internal-linkage
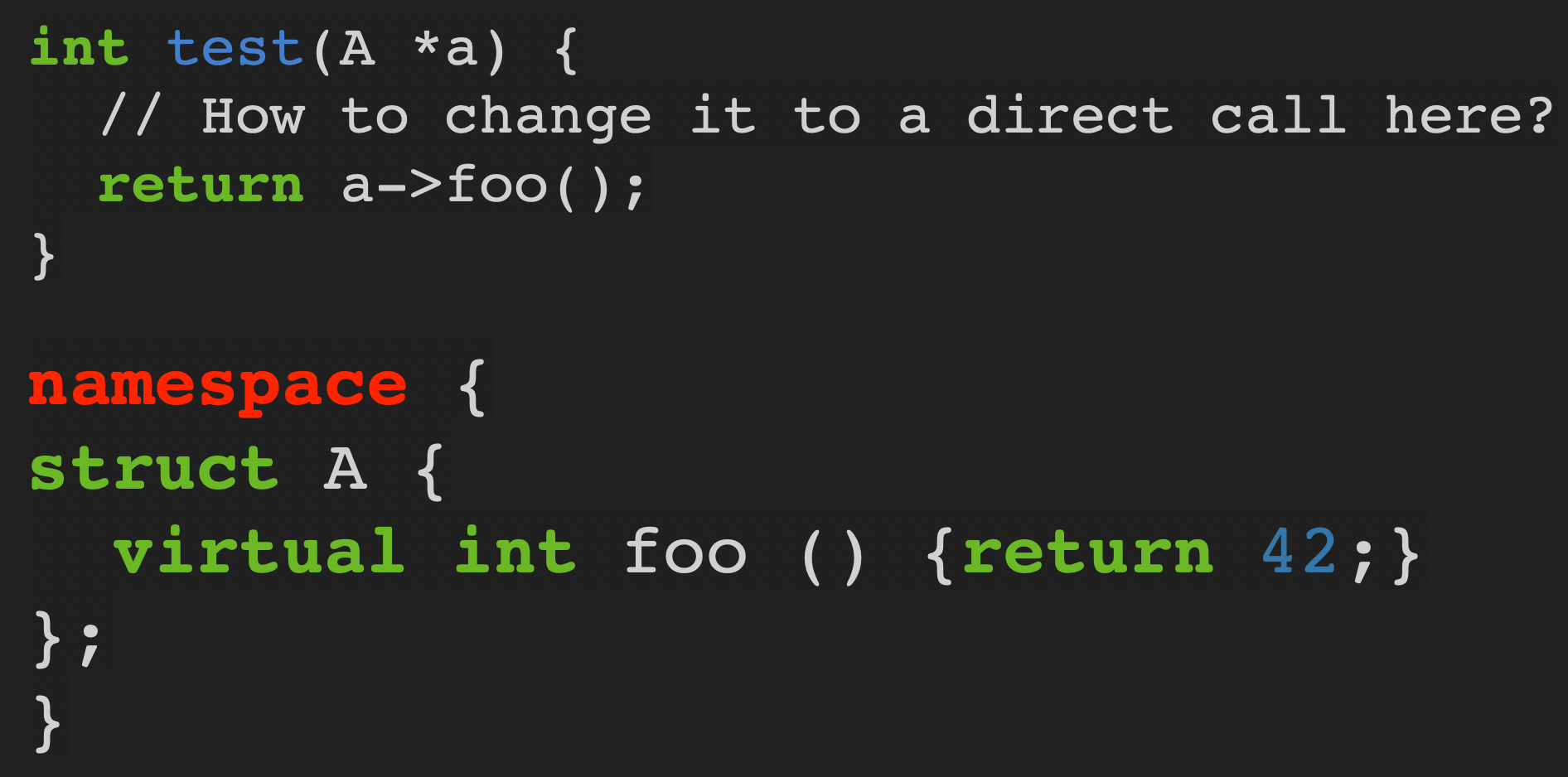
当一个类被定义在匿名命名空间,且在当前编译单元中没有子类,则可以把虚函数调用确切地改为对函数的直接调用。
参考
- The true price of virtual functions in C++
- 醒醒吧,静态多态根本没有这么香
- Add -fstrict-vtable-pointers to UserManual
- Virtual functions strike again.
- Final override
- 字节跳动 Service Mesh 数据面编译优化实践
- When can the C++ compiler devirtualize a call?
- Devirtualization in LLVM and Clang
- Profile-based Indirect Call Promotion
- DEVIRTUALIZATION IN LLVM
文章作者 calssion
上次更新 2022-09-12