跨翻译单元分析与优化简介
文章目录
CTU(Cross Translation Unit) 即跨翻译单元的能力,对于分析和优化而言非常重要。链接时本身就是在处理多个目标文件,而在编译层面支持则可以带来更多的信息帮助分析和优化。本文将简单介绍一下。
1、CTU
1.1、背景
翻译单元通常就是一个实现文件(implementation file) 和其直接或间接引用的一堆头文件组成。由于项目的复杂性,我们通常会把实现按类划分到不同的源文件当中,而如果能够支持跨翻译单元的能力,就可以从整体(如调用链路)进行分析和优化。
编译器通常是对单个文件进行编译生成目标文件,然后由链接器对这些目标文件整合为程序。而且静态分析器通常也是以单个翻译单元为边界的。
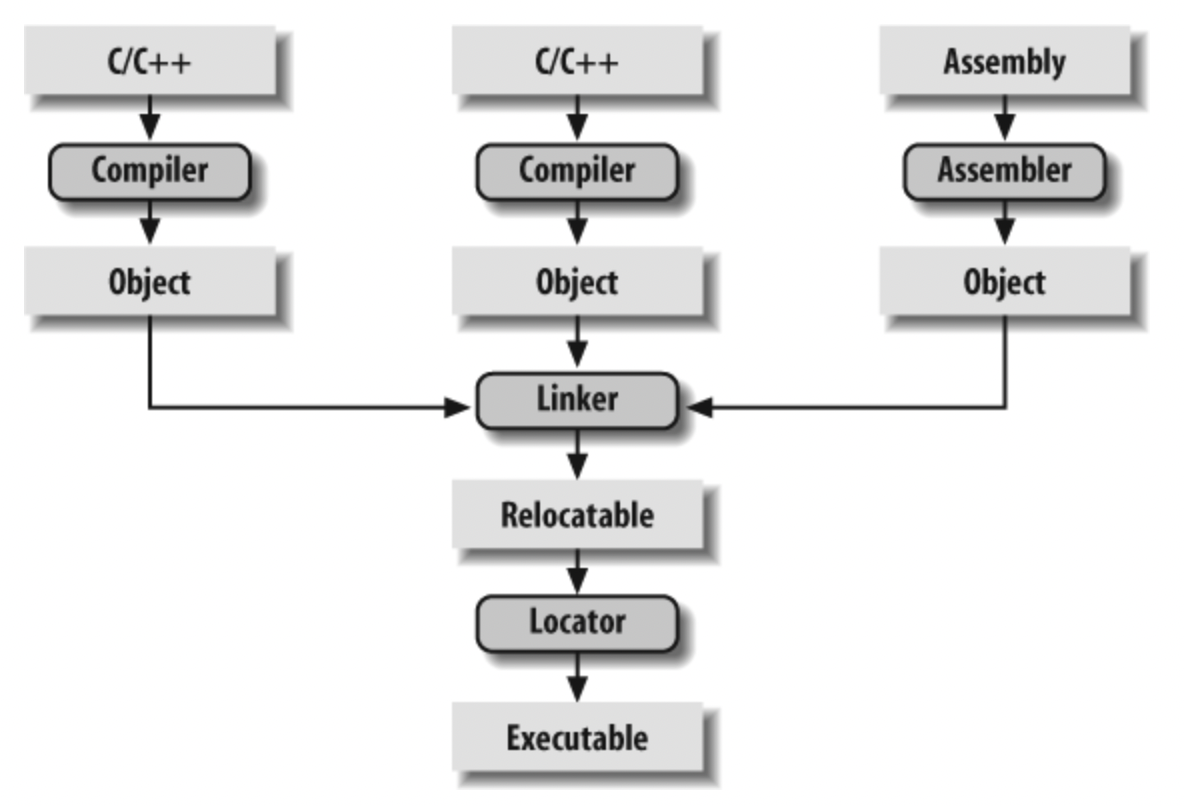
1.2、跨单元能力的重要性
1.2.1、分析
通过跨单元分析可以发现调用链路上的 bug,比如除 0 问题:
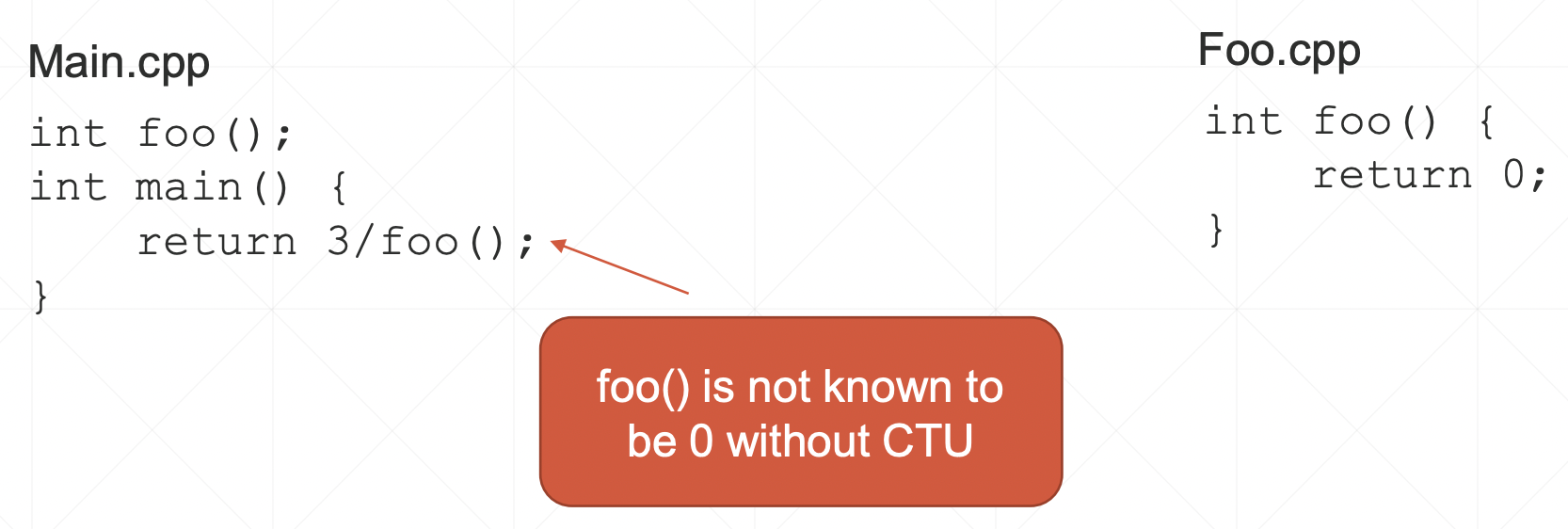
如果能够跨单元分析,至少可以报出警告 warning: Division by zero。
1.2.2、优化
而跨单元优化也是如此,如果只有引用函数的声明,没法进行内联判断,而结合跨单元,就使得很多优化手段可以从整体入手处理。
|
|
|
|
因为没有跨单元,所以最后 -O3 优化下生成的机器码没有优化成常量。
|
|
如果进行了跨单元优化,则 -O3 优化下的机器码会如下:
|
|
2、跨单元分析
2.1、Clang CTU
这里主要指静态分析,这类跨单元分析工具通常需要 compilation database 记录每个翻译单元的编译参数,一些构建系统如 CMake 都支持生成这个文件。这样就可以决定使用哪些编译参数运行静态分析器来分析,通常静态分析只需要编译器前端的能力就足够了。
|
|
在 LLVM 中,使用 clang::cross_tu::CrossTranslationUnitContext 来实现跨单元的静态分析的能力,这个类可以加载合并外部的 AST 资源。在官方文档也有跨单元分析的具体操作方式,文档中还包含了 CodeChecker 的使用例子,这是一个基于 Clang 的扩展工具。
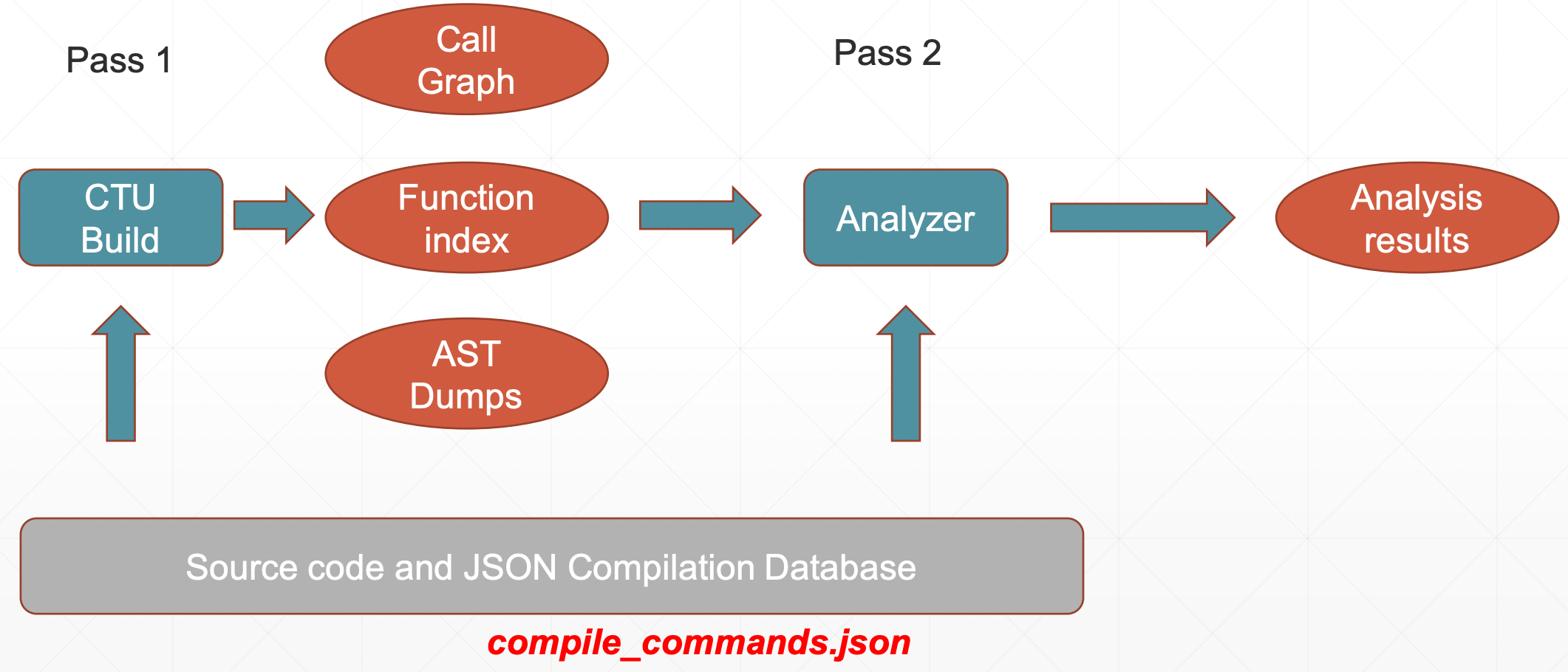
在 LLVM 的 CTU 分析当中,是作为普通的单个编译单元分析的扩展。包含两个阶段:
- 进行普通的单个编译单元的分析,如果发现引用了外部函数,不会立即内联合并其节点,而是先标记后续需要被继续分析。
- 进行 CTU 分析,对单个编译单元的分析图(一般基于 AST) 扩展(extend、引入) 所引用的外部函数的节点来进行分析。
在这个过程当中,会限制 CTU 分析的节点数量,但编译时间还是大致会慢两倍,扩展 AST 也可能会导致出现一些遗漏的分析问题出现。
2.2、统一数据格式
还有一类是采用统一的数据格式存储静态分析得到的信息,把信息都整合存储到数据库当中,可以用来查询或者分析。也正是因为使用了统一的数据格式,所以跨语言分析也不成问题。
有通过 UAST(Unified Abstract Syntax Tree),针对不同的语言的共同点抽象为相同的数据结构;也有用于 language server(语言服务,提供如跳转定义等操作) 使用的 LSP(Language Server Protocol) 协议,以及后续扩展延伸出来的 LSIF(Language Server Index Format);还有谷歌推出的 Kythe 源码分析引擎一整套 schema;等等。
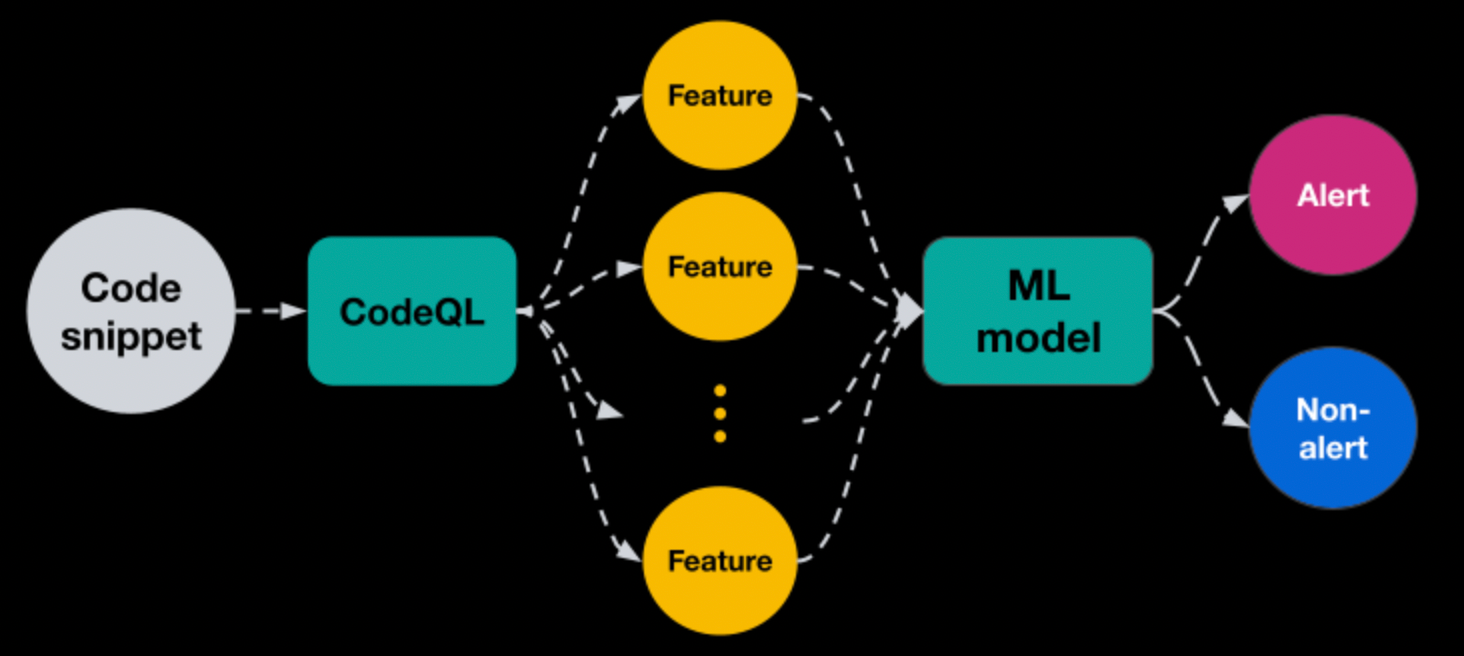
把源码分析收集到的节点按统一的数据格式存储好之后,就可以像查询数据库一样,写漏洞查询规则,像用 CodeQL 等工具那样。而且还可以结合机器学习的分类器进行判断。

3、跨单元优化
3.1、LTO(Link-Time Optimization)
LTO 在之前文章 “代码优化利器 LTO 介绍” 讲过,是在编译时生成 bitcode(中间格式 IR 的一种) 格式的文件,在链接时再进行统一处理,这样就可以有一个全局的视角去做优化。

理论上直接使用 LTO 就可以了,但现实会存在一些问题:
- 对编译耗时负担重。
- LTO 在一些构建系统或操作系统不可用。
- 对于整个程序进行 LTO 通常不可行,如使用第三方库时。

3.2、静态库局部链接
静态库不像动态库,静态库通常只是把所有生成的目标文件合到一块,提供外部使用,没有链接过程。但我们可以通过链接器参数 -r 进行提前的局部链接优化,这个参数会对编译出来的所有目标文件提前进行链接为一个,然后这一个目标文件会被链接到最终的程序当中。即静态库里面只会有一个 .o 的目标文件。
这对于在生成静态库之前,迫使链接器解析符号和链接所有目标文件为一个模块,是很有用的。而且,可以使用一些单独的链接参数在这个提前链接来进行,比如对符号进行 export。
这种技术也被称之为局部链接(partial linking),副作用(side effect) 就是会导致链接 C++ 程序时无法解析构造函数的引用,那么就需要使用参数 -Ur。还有就是由于提前进行了符号解析,会影响到强弱符号的属性。
由于提供的第三方库和主工程的编译器版本问题,对于开启 LTO 能力,经常可能会遇到 Invalid bitcode version,即 bitcode 的生成和读取所使用的编译器版本不兼容的问题。有了局部链接,就可以提前对静态库进行局部 LTO 的优化,且不会影响到主工程的链接时间。(在 LLVM 中,进行静态库局部 LTO 链接需要有 thinLTO 的 bitcode 文件存在,否则链接生成的是 bitcode,而不是机器码目标文件)
3.3、module
在之前文章 “Swift 编译器优化技术:WMO” 介绍过,一个模块就是一系列编译好的源代码文件,独立于其他翻译单元,可以让翻译单元来引入(import)使用。模块减少了头文件使用的问题,而且也减少了编译耗时。像宏(macro)、预处理命令(preprocessor directives)、非 export 的声明,在模块内对外都是不可见的,因此不会影响导入了模块的翻译单元的编译。
模块化把模块下所有源文件组织起来一起编译,自然也就有了模块的视角去进行优化。

LLVM 通过 -fmodules 来开启模块语言特性,而当中也有提供 ModulePass 实现过程间分析和优化。
3.4、Annotated Headers
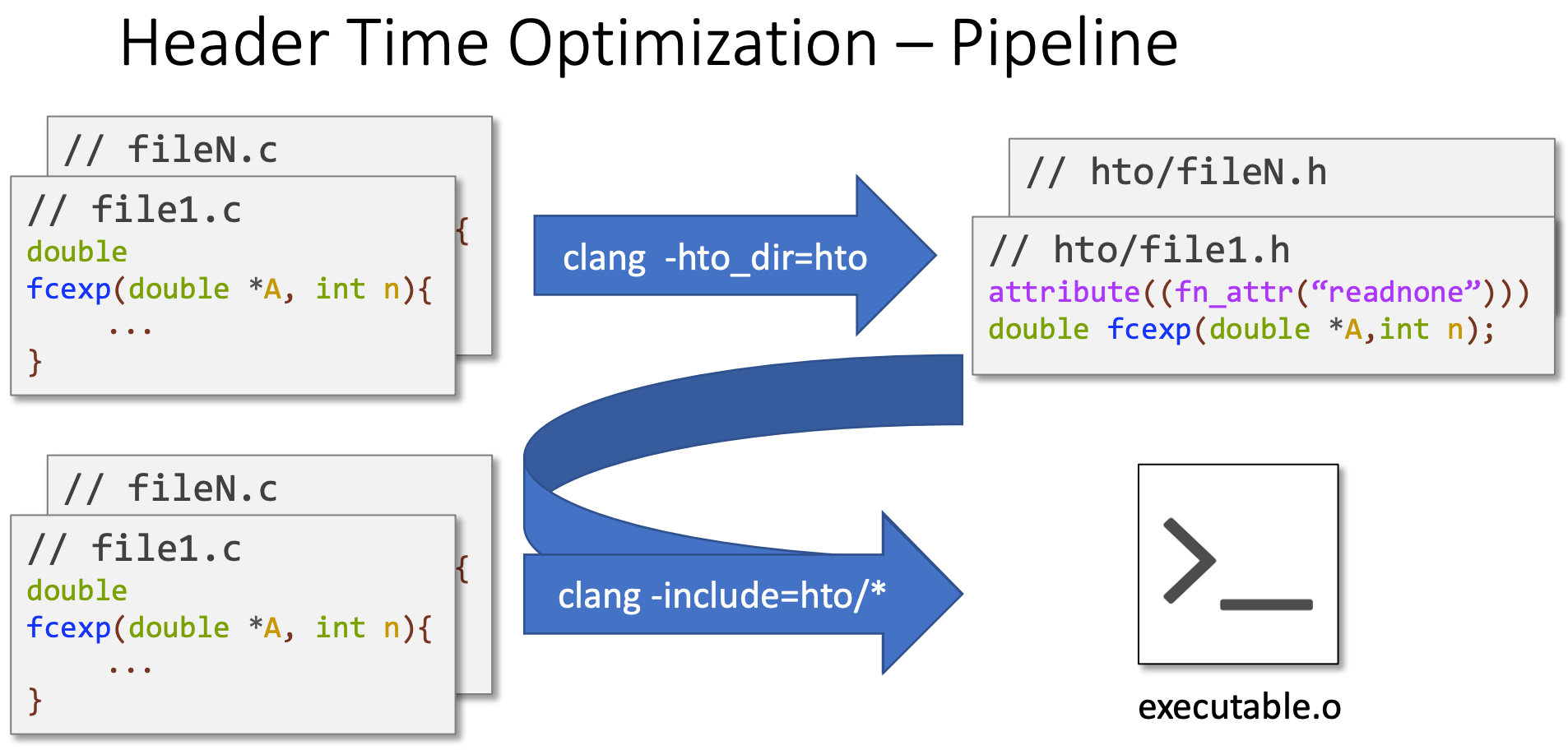
除了转换成中间格式 IR 再进行一起优化,还有一种是生成注解信息的头文件使用。很多时候,在编写源代码时,我们可以通过注解来告知编译器关键信息,以辅助优化。

那么我们也可以通过把一些优化信息用来生成带注解的函数声明头文件,后续只需要 include 进来就能得到这部分信息了,可以用来优化 LTO 的速度,这项技术称为 HTO(Header Time Optimization)。
参考
- Chapter 4. Compiling, Linking, and Locating
- 2.1. Cross Translation Unit (CTU) Analysis
- C++ language documentation
- 2019 LLVM Developers’ Meeting: W. Moses “Cross-Translation Unit Optimization via Annotated Headers”
- HTO_Presentation
- clang::cross_tu::CrossTranslationUnitContext
- CodeChecker
- compilation database
- Using the Clang Static Analyzer
- [RFC] Much faster cross translation unit (CTU) analysis implementation
- UAST - Unified Abstract Syntax Tree
- What is the Language Server Index Format?
- Kythe
- CodeQL
- SHARING SECURITY EXPERTISE THROUGH CODEQL PACKS (PART I)
- Closing the gap: cross-language LTO between Rust and C/C++
- ModulePass
- Linker Command Line Options
- Why does the -r option (relocatable) make ld not find any libraries?
- combine two GCC compiled .o object files into a third .o file
- C/C++. Advantages of libraries over combined object files
- link with static library vs individual object files
- Modules
- Standard C++ Modules
文章作者 calssion
上次更新 2022-10-07