那些编译器优化盲区 - 1
文章目录
编译器并非是绝对智能的,也会存在很多 corner case,可以称之为优化盲区,而在了解一些编译器的操作之后,是可以提前预判到编译器的行为的,那么我们就能写出效果更好的代码。偶尔能看到一些编译器无法进行优化的案例,每次就默默地收集了起来。
1、无符号破坏 empty() 优化
内容来源:In C++, is empty() faster than comparing the size with zero?
在对链表进行 empty() 判断可以有如下的写法:
|
|
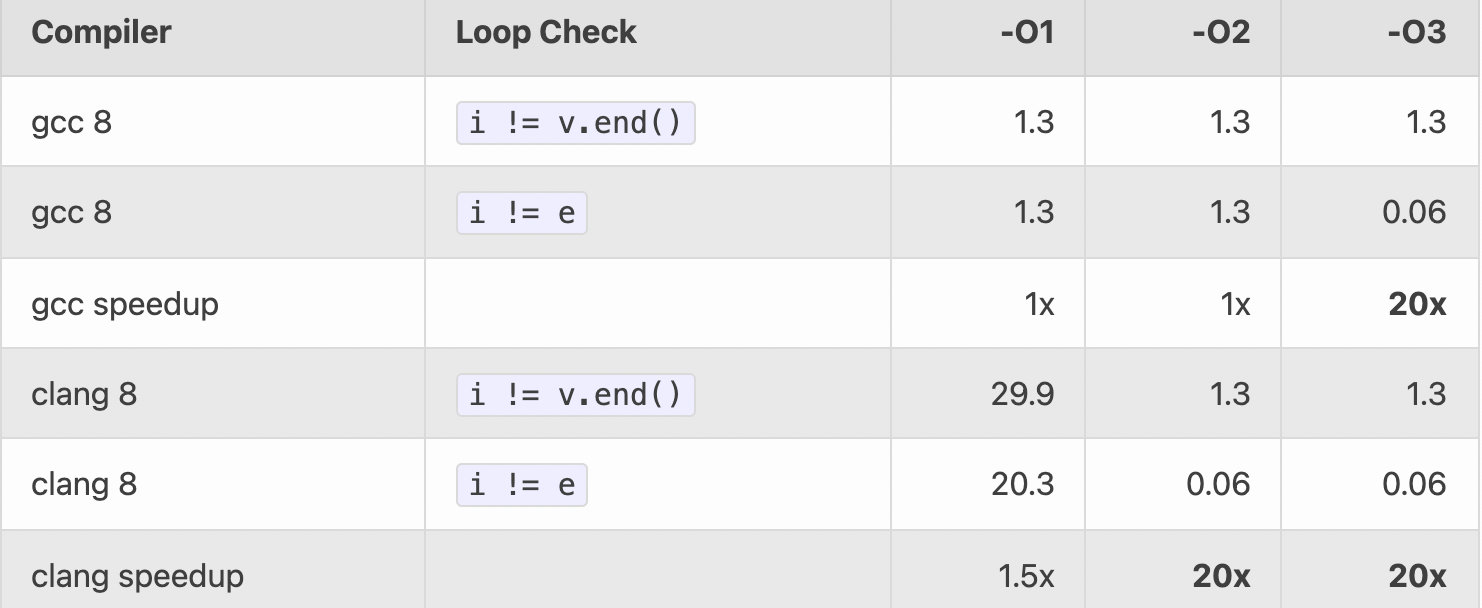
在 GCC 进行 -O3 优化时,会发现 empty() 会变成 O(1) 的复杂度,而 clang 还是老老实实地跑循环 O(n):示例
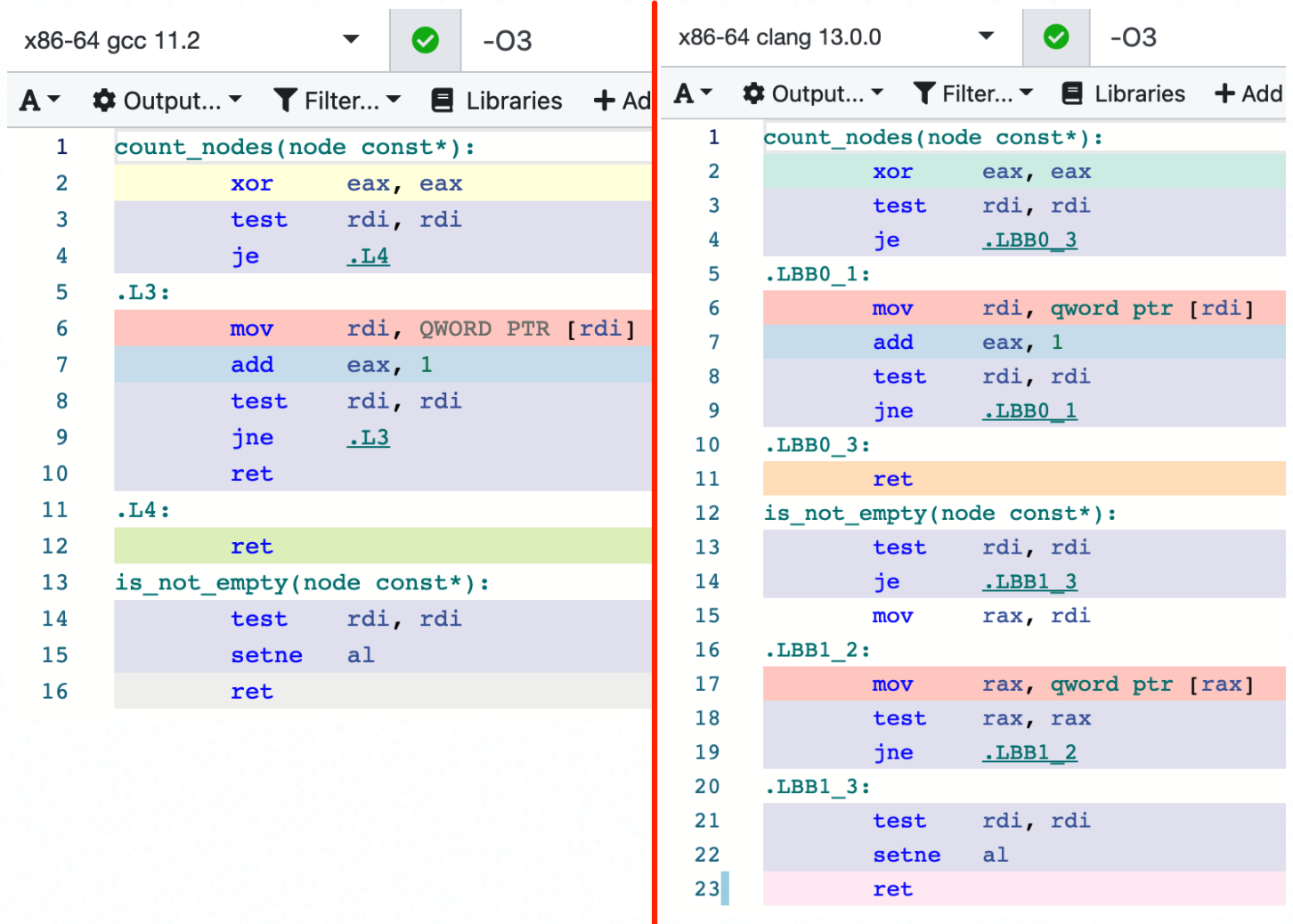
GCC 只用 test 指令判断指针不为空(NULL,0),就可以认为不是 empty 的。
而 clang 是 1、如果为空,再做一次判空,完成;2、如果不为空,跑个循环直到为空,再次判断第一个元素是否为空,完成。(你可能觉得 clang 多此一举,但编译器会考虑很多 corner case,所以还不够智能)
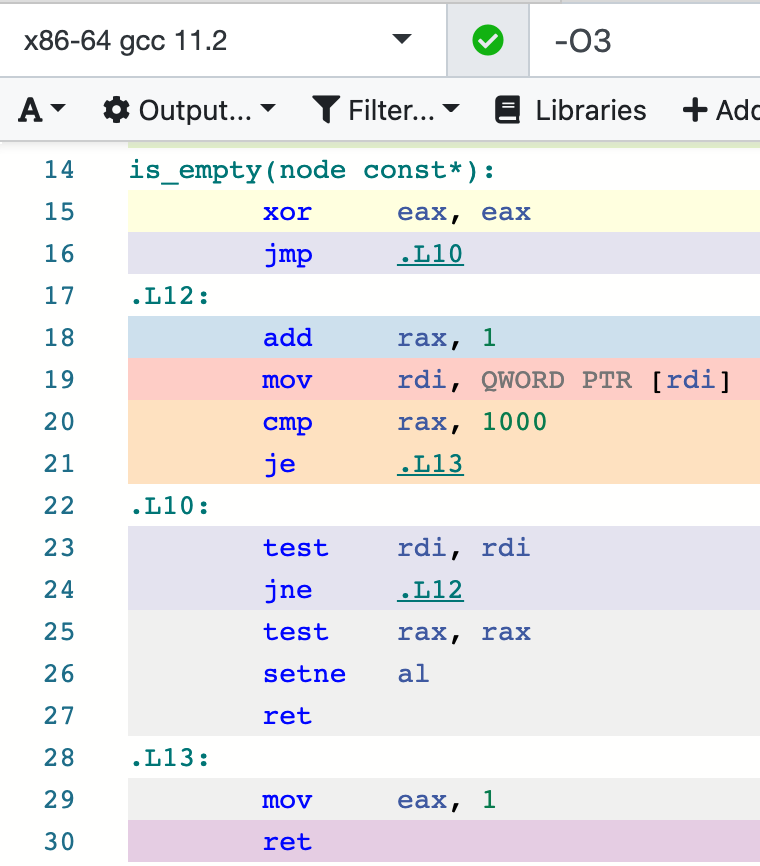
但如果把 count 函数改成无符号类型的话,GCC 也会变得无能为力:示例
|
|
该文作者给出的解释是,在有符号的情况下,编译器可以很好地判断不会发生 overflow。而在无符号的情况下,编译器还要处理 overflow 的情况,很难确认 count 函数会不会返回 0,所以作者在上述代码还给它加了个 1000 的数量限制,但遗憾的是,编译器还是无法对此进行优化。
在一份 GCC 的资料里,我找到了相关的解释,这相当于是 GCC 对于优化的一个设定(GCC 假设有符号不会溢出):
-Wstrict-overflow=n
This option is only active when -fstrict-overflow is active. It warns about cases where the compiler optimizes based on the assumption that signed overflow does not occur. Note that it does not warn about all cases where the code might overflow: it only warns about cases where the compiler implements some optimization. Thus this warning depends on the optimization level.
2、字符串连接导致的 resize 计算
内容来源:operator+ vs string append
|
|
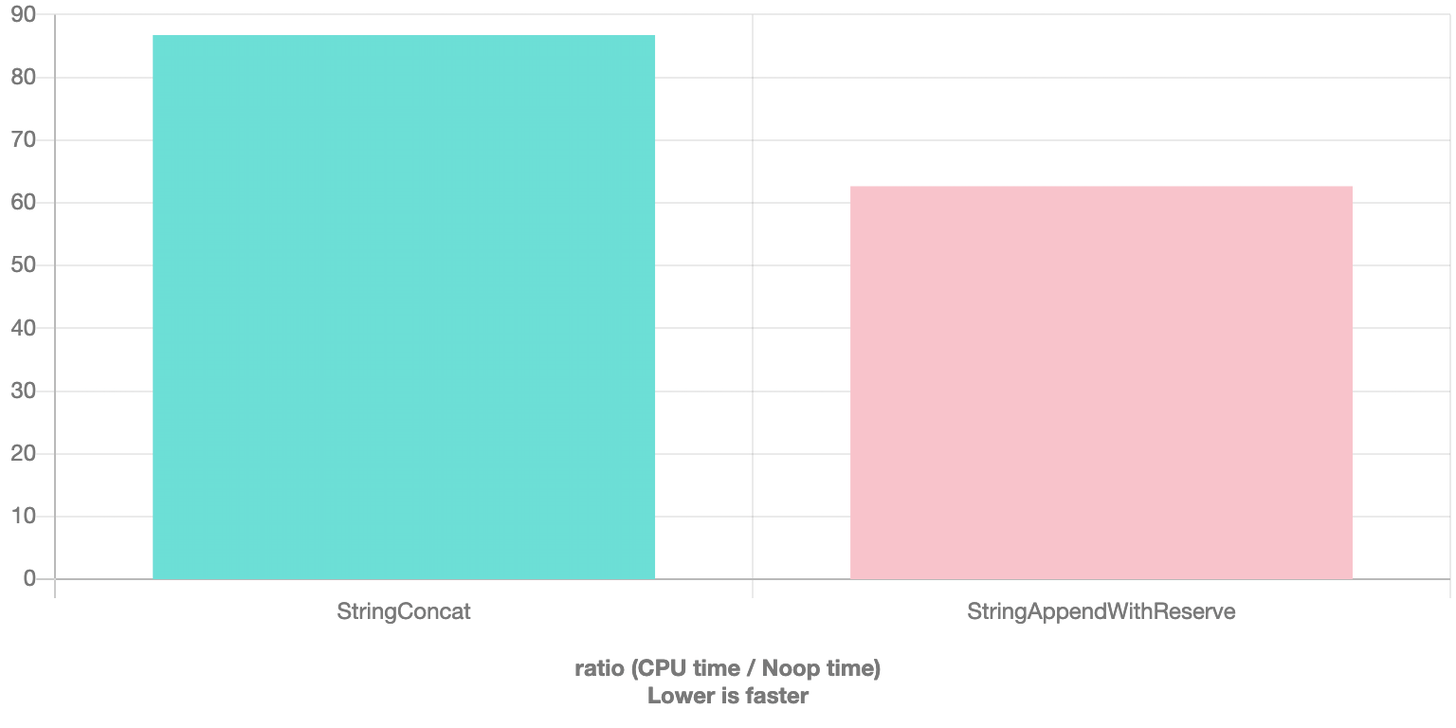
上面这两个方案都是在做字符串的连接,但方案 2 是提前计算好字符串所需预留的大小,再进行操作。
直觉上是操作越少的越快,但是结论反而是方案 2 的性能更优,因为预留足够的空间来做字符串连接也是一项重要优化,而 clang 还没智能到直接算好需要预留的空间。
stack overflow 还有相关问题讨论:Most optimized way of concatenation in strings
但是注意,对于合并总长度较短的字符串,先使用 reserve 可能会劣化,因为 std::string 对短字符串有做优化(Small Object Optimization,不另外开辟内存,直接在原有变量内存上存储短字符串)。
3、指针别名
内容来源:https://travisdowns.github.io/blog/2019/08/26/vector-inc.html
对数组的每一个元素进行加 1 操作,下面有 uint8_t 和 uint32_t 两个版本,哪个会更快?
|
|
假设有接近 20000 个元素,直觉上是 8-bit 版本的会更快,因为占用的内存更小,同时也更能够满足 L1 cache,而且说不定还用上 auto-vectorization (自动向量化计算,如利用 SIMD(single instruction multiple data) 单条指令同时操作多个数据),那么 8-bit 版本应该更有优势。
但事实并非如此(数字越小,代表耗时越短):
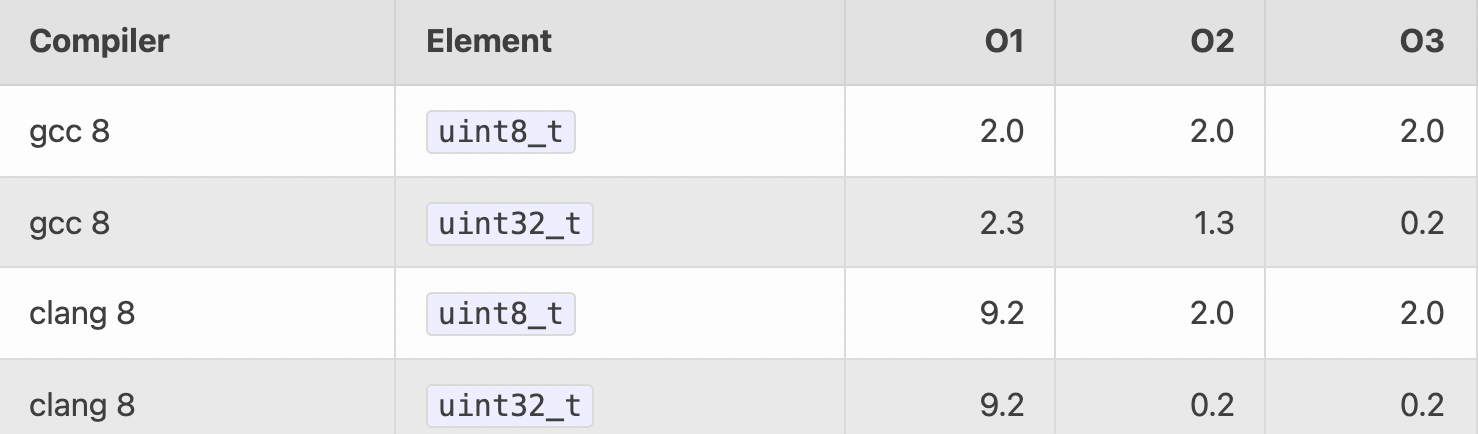
反直觉的,32-bit 的版本性能更高。
3.1、-O2
在 -O2 优化下,看看指令的差别:
|
|
32-bit 版本的循环体,少了对 vector::begin 和 vector::end 的加载、用 end - start 计算出 size。而 8-bit 把这些都放在循环体内,属于重复操作。为什么会产生这样的差异,原因就在于指针别名(pointer aliasing),下面会进行解释。
3.2、-O3
-O3 优化又做了什么,来取得了进一步的优化?
|
|
答案就是 auto-vectorization,整个循环体被向量化,可以在 L1 cache 中一次循环同时操作 8 个数据(256 bit)。
3.3、pointer aliasing
那么导致 8-bit 版本无法进行这些优化的罪魁祸首,就是指针别名了。
|
|
首先数组 v 是通过引用而来的,实际上就是一个指针,编译器需要通过 v::begin 和 v::end 来计算出数组的大小 size()。
编译器需要在循环体中,一直获取 size(),因为它无法保证 size() 会不会在过程中被修改。
为什么呢?因为 v[i]++ 在写入未知的内存位置,编译器无法确认修改的会不会是 size() 的值。
那为什么只在 8-bit 版本上无法确认?因为对于大多数编译器而言:
-
uint8_t是unsigned char的别名(typedef) -
unsigned char(或 char) 数组可以指向(alias,别名)任何类型 -
通过
uint8_t指针修改,会被认为有可能更新任意位置的内存 -
编译器认为
v[i]++会威胁到size(),所以每次循环重复计算
编译器有时候就是不够智能!
3.4、如何解决
那么解决方法,就是让编译器认为我们不会在过程中修改 size() 的值。
|
|
在这里不再使用 size() 来做判断,而是使用 end() 来判断结束,编译器会优化成:
|
|
为什么要把 v[i]++ 改成 (*i)++ 了?因为 v[i]++ 可能会被认为是 *(v.data() + i),导致多出一次对内存的访问操作。
但这里还是会有冗余,对 end 内存访问的操作,那么提前计算好,就是给编译器最好的提示:
|
|
参考
In C++, is empty() faster than comparing the size with zero?
The point of test %eax %eax [duplicate]
Options to Request or Suppress Warnings
文章作者 calssion
上次更新 2021-12-12