LLMs 协助编译器优化代码体积
文章目录
简读一篇论文《Large Language Models for Compiler Optimization》,是将大语言模型 LLMs 用于编译器代码优化阶段,优化生成的代码的体积,在已有编译器优化的情况下,再实现了 3% 左右的减少量。
之前有写过机器学习用于代码优化的,即 MLGO(Machine Learning Guided Compiler Optimization),它使用一些数字化的特征来引导函数的内联操作,但难以还原 call graph(调用图) 和 control flow(控制流)。
机器学习的方式表现良好,但难以泛化到不同的程序当中。论文作者认为具有足够推理能力的 LLMs 可以学习做出良好的优化决策,而无需进行多次编译。
细节略读,论文作者使用 LLaMa2 作为框架,以大量的 LLVM IR(Intermediate Representation) 函数进行训练,还包括最佳的编译器选项以及执行这些优化后的 IR 代码。训练的目标是选择更优的编译器优化 pass 和顺序,以达到更小的代码体积,训练会使用生成的 IR 指令数作为评估指标。模型接收未经优化的 IR 作为输入,然后输出一个应该进行的一些优化 pass 的列表,而且还可以顺便直接生成指令数量情况和优化后的 IR 代码。
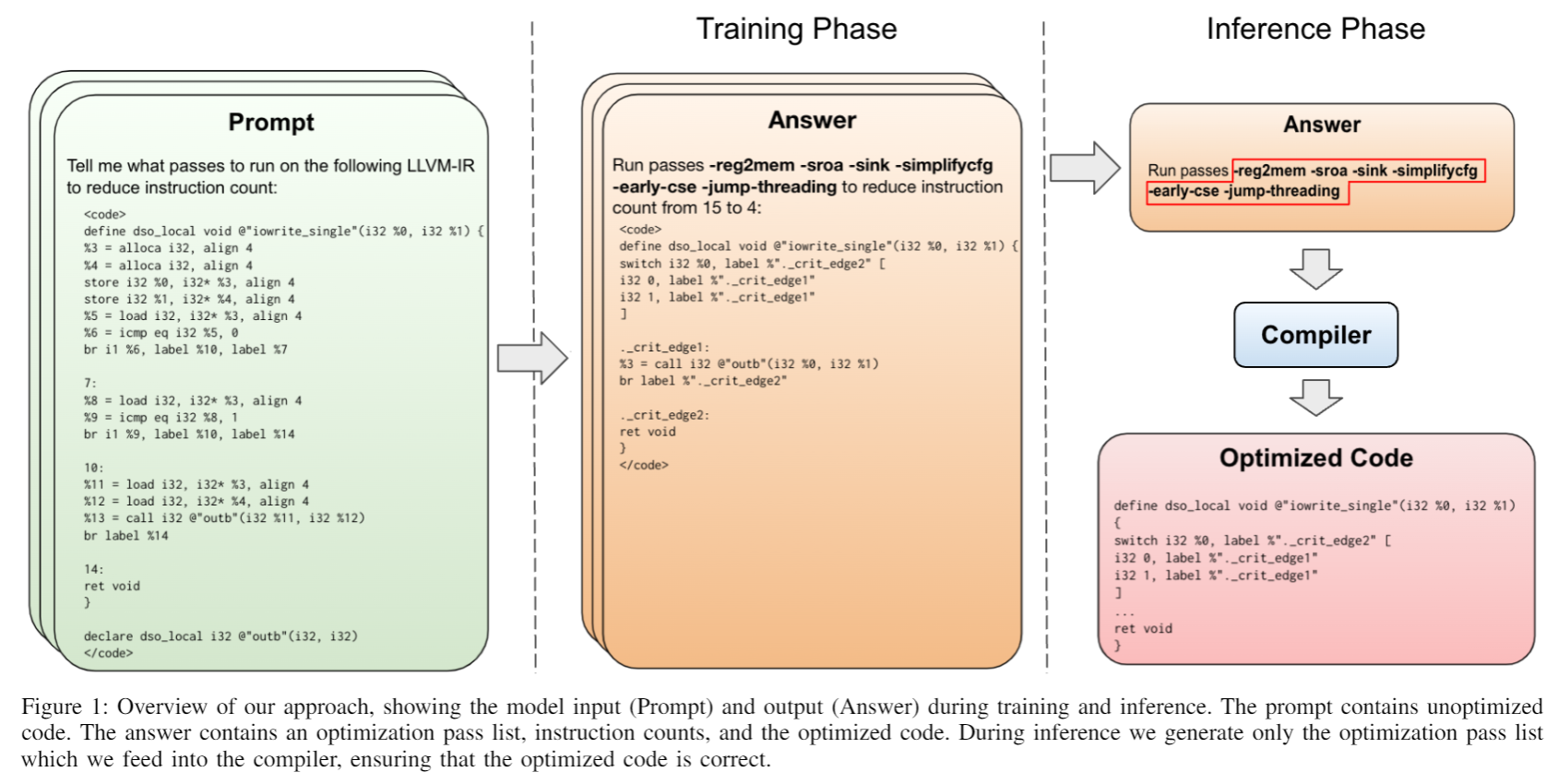
训练使用的代码需要规范化,比如去掉注释、调试元数据、attribute 属性、一致地缩进和空格等,这减少 IR 代码的长度。训练使用 autotuning 自动调优,对于每个函数,运行固定时间的随机搜索,然后通过不断迭代,删除随机选择的部分 pass,来最小化最佳的 pass 列表,看是否对指令数有贡献。如果无就抛弃,如果有就尝试应用到其他函数中看效果。

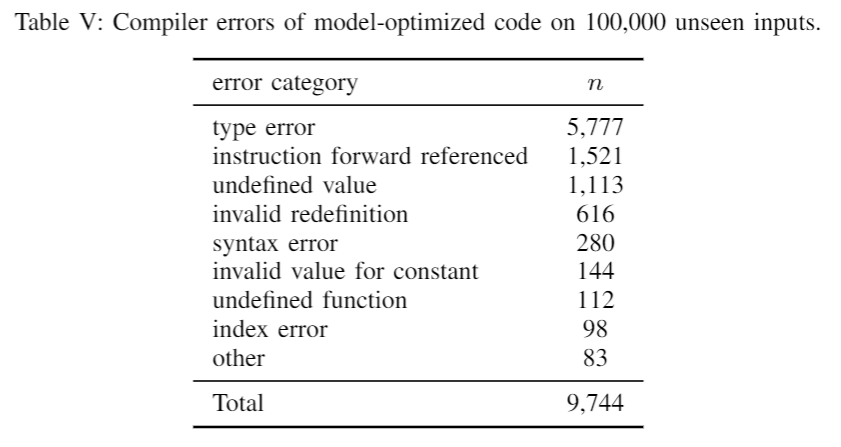
该模型生成的 IR 代码编译成功率为 90.3%,其中有 68.4% 的生成代码与编译器生成的完全一致。而那 9.7% 的错误的类型主要如下。
但与编译器生成不一致,就还需要评估语义等价性了,LLMs 对于数学运算和逻辑运算不是什么强项,使用思维链(chain-of-though) 可以有所帮助。
看完该论文,我认为直接使用 LLMs 生成的 IR 指令还是有很大的风险,但使用其生成的 pass list 让编译器去进行优化,还是值得去尝试的。
参考
文章作者 calssion
上次更新 2023-09-21