内存操作对性能影响简析
文章目录
对于程序的运行性能的影响,除了关注 CPU、算法等,内存操作也是相当重要的。
1、memory wall
计算机系统一般由处理器和内存组成,但内存慢于处理器百倍。内存的数据传输,造成了处理器瓶颈和等待。
即使是 vectorization(向量化) 也会遭遇到内存瓶颈,并不能完全依我们设想的提高性能,CPU 会等待数据到达内存当中。另外,它会导致 CPU 更耗能,因为使用了向量单元来操作。
2、cache
所以出现 cache 缓存的技术方案,利用取数据的局部性原理(一是取过的地址附近极有可能也被用到;二是取过的地址在很短时间内极有可能又被访问到),来弥补这种速度差异。
- 当线性访问数据结构时,使用线性结构,如数组,而非链表。
- 在结构体中,把经常访问的放置挨到一起。
- 使用数组存值,而非存指针。
- 保证数组中保存的结构体、以及数组的起始地址是 cache line 大小的倍数,可以用
__attribute__((aligned (64)))。 - 操作二维数组时,避免按列访问。
- 避免过多的结构体中为内存对齐而添加的 padding(字节填充)。
- 使用占用字节小的类型。
- 尽可能使用栈,而非堆内存。
- 逻辑连贯地使用还在 cache 中的数据,而不是分开或分散地多次操作。
- 减少写内存操作,因为写内存时 cache 需要重新加载数据,来避免出现不一致的问题。
- 保证数据对齐,如
char*转换成int读取时,直接转换导致不对齐,可以调用memcpy来避免。 - 对于随机访问,可以预取数据,比如 Clang 支持使用
__builtin_prefetch。
在 clang 编译器中,可以用 clang -cc1 -fdump-record-layouts xxx.cpp 输出源文件中类和结构体的相关信息来查看。
|
|
3、dynamic memory
当我们考虑动态内存对程序的性能影响时,需要考虑两个点:
- 分配速度(allocation speed),即分配和释放内存的速度,通常依赖如 malloc 和 free 的实现。
- 分配内存会慢的其中一个原因,是分配算法需要时间去找到合适的大小的内存块,而随着程序运行,还会出现越来越多的内存碎片(memory fragmentation),使得分配更加困难。
- 还有对于多线程而言,还需要保证内存操作是线程安全的,所以通常还需要有同步机制,比如锁,这对于性能也是一大消耗。
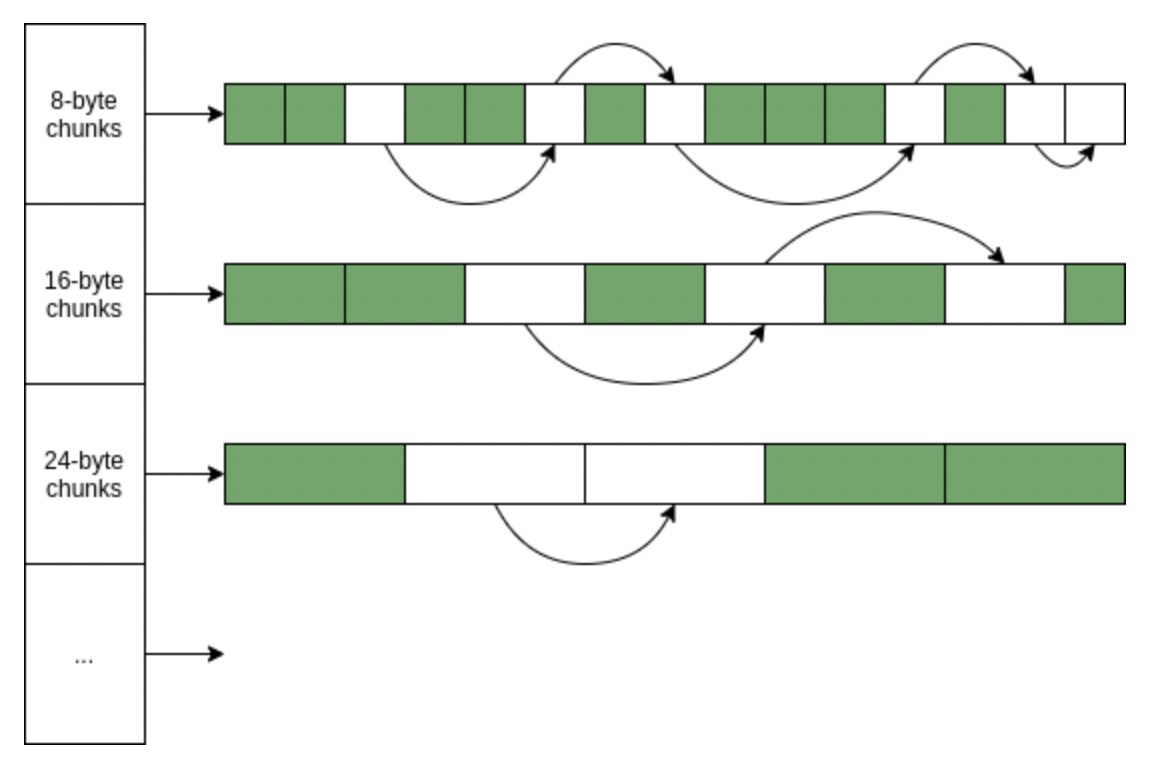
- 访问速度(access speed),即访问系统分配的内存的速度,依赖于内存硬件系统和内存分配器。
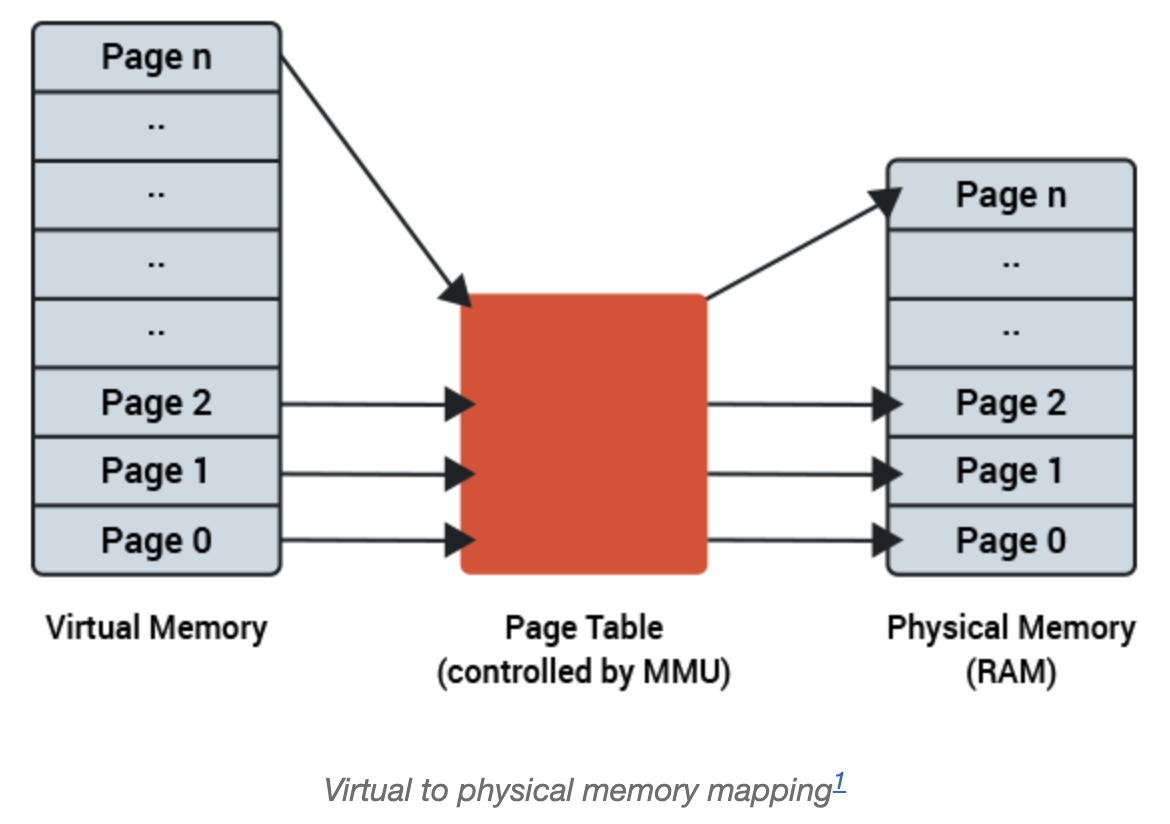
- 用户程序使用的是虚拟内存,由硬件内存管理单元 MMU(Memory Management Unit) 进行虚拟地址到物理地址的转换,转换需要从内存中加载页表去读取映射关系。为了加速转换过程,添加了一个硬件 cache TLB(Translation Lookaside Buffer) 作为缓存。
- 没有实际物理地址的内存,在初次写入时,会出现缺页中断(page fault),如使用 mmap 后的写入。
4、减少内存的读写次数
除了减小数据量级和数据的访问方式,我们还可以通过减少内存的读写次数,来提升性能。
4.1、Fusion
合并一些操作可以减少重复的内存读写次数。在之前写的循环优化文章当中,有 loop fusion,是将两个独立的循环体进行合并,比如分开求值的 min 和 max,可以合并到一块。
4.2、指针别名导致的内存读写操作
|
|
如何避免上述代码中多次的加载,有以下方式:
- 使用值拷贝传递参数的方式。
- 使用
__restrict__告知编译器这个引用不会指向同一块内存当中。 - 强制使用向量化优化,通常会自动忽略掉指针别名的情况。
4.3、Register Spills
寄存器溢出,通常发生在没有足够的寄存器来容纳过多的值(value),就会先放到栈上,等需要时又从栈中加载回来。在执行频繁(hot) 的逻辑中,发生寄存器溢出,是会损坏运行时性能的。
编译器决定寄存器是否保存某个值,是通过存活分析(live range analysis) 判断的。编译器可以知道某个值什么时候会被用到,或者什么时候不再需要了。当值开始被初始化时,就变成活的(alive),处于稍后会被用到的的状态;而当值完成最后一次使用后,它就是死状态(dead),那么保存着该值的寄存器就可以用来存其他的了。
|
|
虽然很难控制具体的编译器行为,因为初始化和销毁的指令是可能会被挪动的。但开发者也可以在上层的编程语言,减少寄存器溢出的情况:
- 让一个值的初始化和首次使用尽可能挨近。
- 让一个值的销毁和最后一次使用尽可能挨近。
- 尽可能让一个值的生命周期在一个块中完成。
- reduction(多个值求结果得到一个值,通常是表达式),把求值过程划分成多个子求值过程,减少一次性加载的值的个数。
- rematerialization(重新计算值),有时重新计算一遍,比起持有某个值时发生寄存器溢出和重新加载要好得多。比如我们通常会把多次用到的
v+1的结果保存到一个新的变量当中来复用,但如果会频繁发生变化,可以考虑直接用表达式v+1重新计算,而不是持有。
参考
- Make your programs run faster by better using the data cache
- The price of dynamic memory: Allocation
- cache miss, a TLB miss and page fault
- The price of dynamic memory: Memory Access
- When vectorization hits the memory wall: investigating the AVX2 memory gather instruction
- AI’s compute fragmentation: what matrix multiplication teaches us
- Decreasing the Number of Memory Accesses 1/2
- Decreasing the Number of Memory Accesses: The Compiler’s Secret Life 2/2
- Dumping a C++ object’s memory layout with Clang
- Why is memory safety still a concern?
文章作者 calssion
上次更新 2023-06-05