链接器优化: 相同代码折叠 ICF
文章目录
最近看到一篇论文《Safe ICF》,是链接器的一项优化技术,叫相同代码折叠(合并),可以用来优化二进制体积,可以搜论文看看,本文是所做的笔记。
1、简介
在大型的 C++ 应用和动态库中,存在着很多函数体一样的函数,大概有 10% 左右的可以做合并操作,这种技术称之为 ICF (Identical Code Folding)。在 C++ 当中,主要是因为对模版的使用,会导致相同实现体的函数出现(比如以类型的指针来进行实例化,而指针类型大小是一致的)。
在链接时,ICF 会检测出带有相同实现体的函数,然后合并为一个单独的副本。显而易见,这样操作的好处就是减小了二进制体积(实验 Google 体积下降 64MB,6% 左右,性能无影响)。
但 ICF 不一定安全,因为它会改变需要函数有唯一地址的运行时行为。ICF 可以安全地用在那些不需要进行地址比较的需合并的函数身上。还有,对二进制进行调试(debugging)和探测(profiling)时会迷惑,因为合并的函数的 PC 地址指向不明,所以也有新的 DWARF 格式对此来进行兼容。
ICF 也扩展到 read-only string section、unwind info 等场景。
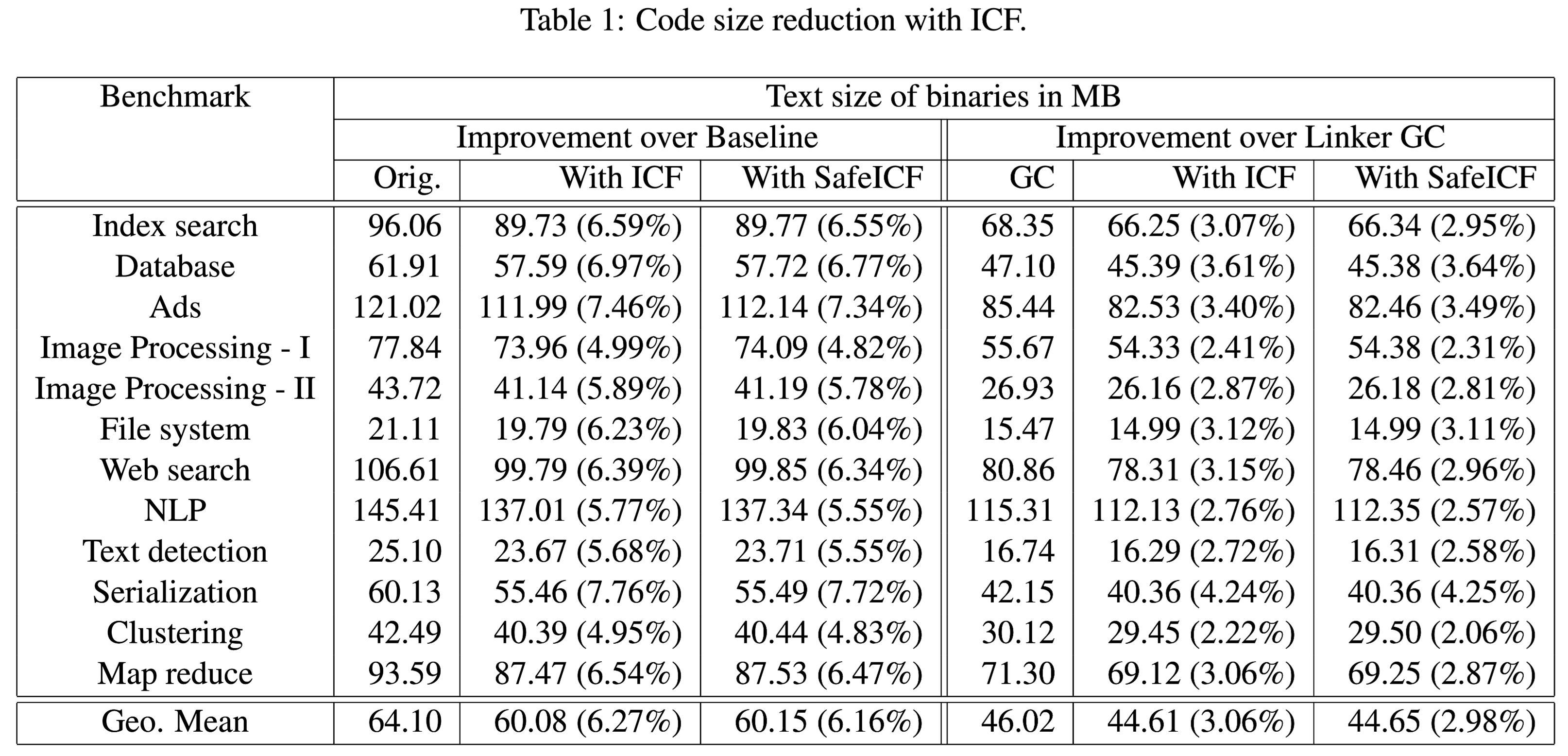
2、ICF 算法
ICF 要如何检测到相同实现体的函数?为了使链接器可以实现这一手段,编译器需要把每一个函数放置在一个单独的 section,这个功能 GCC 编译器已经提供了支持 -ffunctions-sections,当然,实际上拿到 text 段中每一个函数的位置再进行计算也是可行的。
从链接器的角度而言,在代码段,一个函数的实现体包含有代码文本以及重定位信息。那么,只要代码文本二进制完全相同、而且它们的重定位指向相同的 section,就可以认为是相同的。这里的重定位信息指向相同的 section、或者指向被认为相同的函数,都被认为是相同的。
|
|
开始链接器操作,首先,需要把每一个函数体划分为两个部分:常量(constant)和变量(variable)。常量部分代表在分析中不会产生变化的内容,一般是代码段内容、以及不会指向考虑合并的候选函数 section 的重定位信息。而变量部分代表指向被考虑合并的函数 section 的重定位信息。
然后,分析会把可合并的函数归为一组,分多个组。计算时,常量部分保持不变,而变量部分会用组标识符(group identifier)来代替重定位信息,这个组标识符表示重定位信息所指向的函数 section 的组(初始时会为每个考虑合并的函数定义一个组标识符,初始时每个组只有一个函数)。算法会对内容进行 checksum(校验和),然后基于这个结果把函数划分到不同的组里面。再用新的组标识符对新的划分进行上述同样的操作直到收敛(到达不动点 fixed point,每个函数 section 的组标识符不再变化)。在这个过程中,实际上只有变量部分会被重新计算。
最后,我们在每个组里面,只保留一个,其余的被丢弃。
2.1、初始阶段
在初始化阶段,有两种选择:
- 消极,每个函数放在一个单独的组里。 这样操作每次迭代后结果都是正确的,不一定需要到达不动点。但是对于递归调用函数或相互间的递归调用,就难以识别出来了(因为重定位部分会用组标识符来替换,所以这些函数很难被认为是相同的)。
|
|
- 乐观,所有函数放到同一个组里,即认为所有的函数初始时都是相同的。可以识别递归函数,但算法需要执行到不动点才能保证完全正确。
在论文《Safe ICF》中,采用的是消极的方式,首先保证正确性,对于递归函数,则先识别出来,然后采用特殊符号来进行替换。
2.2、预处理
为了减少需要分析的函数的数量,先剔除掉只具有常量部分的候选函数(即只有静态代码文本,而没有重定位信息的),因为这些函数可以直接做比较,不需要进一步的算法分析。
链接器在做 sections 合并的时候,会把所有的 section 以及只读的常量(read-only constants)看作是常量静态文本。而 ICF 的分析需要在链接器做合并操作之前进行。因此,我们需要先把被引用的常量内联(inline)到被引用的地方,这样函数就更有可能是相同的。
3、安全模式
链接器开启 ICF 使用选项 --icf=all,这里还提供了一种更为安全的选项 --icf=safe。
前面说过,对于需要进行地址比较的函数,进行合并是一种危险的操作。为了保证运行时的安全性,安全模式下会检测哪些函数被通过指针获取地址,阻止这些函数被合并。虽然不是所有通过指针获取函数地址的情况都会拿来比较,但为了确保安全,所有这些函数都会被标记为不能合并。
根据 C++ 规范,通过函数指针来获取构造函数(constructors)和析构函数(destructors)是被禁止的,因此,对他们进行合并操作是安全的。对于虚函数的指针获取,只是为了虚表的使用,也是可以安全地考虑进行合并,并不会影响运行时行为。
参考
- 论文《Safe ICF: Pointer Safe and Unwinding aware Identical Code Folding in the Gold Linker》
- Teach ICF to dedup functions with identical unwind info
- Implement ICF
文章作者 calssion
上次更新 2022-03-20