搞懂 C++ 编译规则:实体与指针的“前向声明”之谜
文章目录
在开发 C++ 时,可能会遇到 incomplete type(不允许使用不完整的类型) 的错误,这个错误的背后隐藏着 C++ 编译器一个经典且合理的规则,本文来简单介绍下。
编译规则
这个规则是:当我们需要一个类的“实体(对象)”时,编译器必须看到它的完整定义;而当我们只需要一个“指针”时,仅仅给编译器一个前向声明就足够了。
来看看具体的案例,这里定义一个实体:
|
|
这段代码会编译报错:error: aggregate 'Test a' has incomplete type and cannot be defined。
而如果我们不定义实体,而只是定义一个指针的话,编译是成功的:
|
|
实体与指针
那么实体与指针到底会有什么区别,编译器是怎么看待类的?
|
|
实际上我们可以通过反汇编生成的二进制文件可知,在最终的机器码中,‘类’这个高级概念已经被抹除了。编译器在计算好内存布局后,所有的成员变量访问都会变成直接的内存地址偏移(如 [r7, #4]),所有的成员函数调用也会变成普通的函数符号调用。
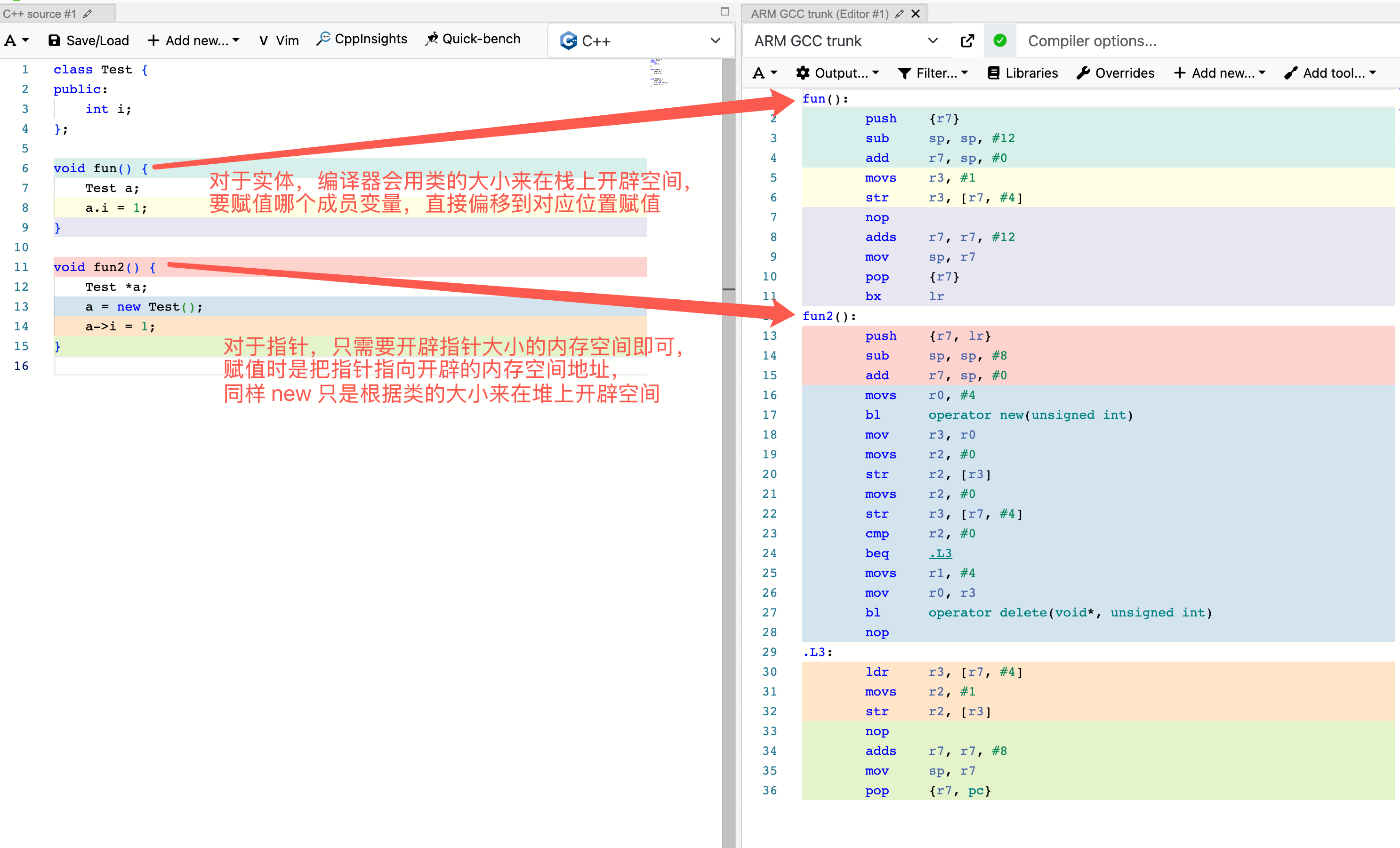
在定义实体时,为了计算内存大小(sizeof)和进行正确的内存布局,编译器必须看到类的完整“定义”。
而在定义指针时,它只是一个内存地址。 无论这个指针指向的是一个极其简单的 int,还是一个极其复杂的超大类对象,指针本身在内存中占据的大小是固定的,所以,只需要提供一个声明。
规则合理性分析
既然编译器这么聪明,为什么不干脆强制要求所有情况都引入完整定义呢?这样岂不是更省事?
C++ 允许“指针只需声明”这一设定,是经过深思熟虑的,它带来了两个极其重要的好处:
1. 解决“鸡生蛋,蛋生鸡”的循环依赖问题
假设你有两个类:Husband (丈夫) 和 Wife (妻子)。丈夫类里需要记录自己的妻子,妻子类里也需要记录自己的丈夫。
如果你在两个类的头文件里互相包含(#include)对方的定义,编译器就会陷入死循环。但因为有了这个规则,你可以在类里使用指针配合声明来完美破局:
|
|
2. 极大提升编译速度(Pimpl 惯用法)
在大型 C++ 项目中,如果一个头文件被修改了,所有包含了这个头文件的代码都要重新编译。如果类的实体到处都是,头文件的依赖网会变得无比复杂,改一个变量可能导致整个项目编译更久。
利用“指针只需声明”的特性,C++ 演化出了著名的 Pimpl (Pointer to implementation) 惯用法。把类的私有实现细节隐藏在一个结构体里,并在对外头文件中只放一个指向该结构体的指针。这样一来,无论你怎么修改内部实现,对外的头文件都不需要变,其他包含了这个头文件的文件也完全不需要重新编译,极大地拯救了编译时间。
文章作者 calssion
上次更新 2026-02-24