Swift 编译器优化技术:WMO
文章目录
Whole-Module Optimization (全模块优化) 是 Swift 编译器的一种优化方法,对工程的运行性能可以有 2~5 倍的提升。在 Xcode(macOS 上的 IDE) 8 之后 release 配置下是默认开启的选项。
1、术语
这里先简单解释一些基本术语的概念,如果对这些已经有很好的认识,可以跳过这部分。
1.1、计算机语言
这部分内容参照文章《编译原理初学者入门指南》。这部分与本文相关度不高,不过 SwiftUI 采用声明式语法,属于 Swift 的 DSL,就贴一下。
随手打开一个工程,我们就能发现形形色色的语言文件,比如 yaml 格式的服务配置文件、json 格式的工程配置文件、js 和 go 等源代码文件等。忽略掉他们繁杂的用途,按其表达能力,可以分为两种:
- DSL(Domain Specific Language):特定领域语言,比如用来描述数据的 json、用来查询数据的 sql、标记型的 xml 和 html,都属于面向特定领域的专用语言,用在正确的领域上就是利器,用错地方就是自找麻烦(比如用 sql 来一段冒泡排序)
- GPL(General Purpose Language):通用用途语言,比如 C、JavaScript、Golang,这类语言是 图灵完备 的,你可以用一门 GPL 语言去设计和实现一种 DSL 语言
不管是为特定领域而发明的各类 DSL,还是图灵完备的 GPL 语言,他们基本都符合 BNF(巴科斯范式)。
BNF 是一种 上下文无关文法。举个反例就是,人类的语言是一种上下文有关文法,具有连贯的逻辑性和因果性。
关于 BNF 具体定义,这里摘抄一下维基百科:
BNF 规定是(产生式)的集合,写为:<符号> ::= <使用符号的表达式>这里的 <符号> 是,而由一个符号序列,或用指示的 ‘|’ 分隔的多个符号序列构成,每个符号序列整体都是左端的符号的一种可能的。从未在左端出现的符号叫做终结符。
1.2、翻译单元(Translation units)
一个程序会包含一个或多个翻译单元,而一个翻译单元包含了一个实现文件(implementation file)和其直接或间接引用的一堆头文件。在 C++ 中,实现文件一般文件扩展名是 .cpp 或者 .cxx,而头文件的文件扩展名是 .h 或者 .hpp。
每个翻译单元会被编译器独立地进行编译,当编译完成后,会生成目标文件(object file),链接器会将这些目标文件合并处理为一个程序。
1.3、模块(module)
一个模块就是一系列编译好的源代码文件,独立于其他翻译单元,可以让翻译单元来引入(import)使用。模块减少了头文件使用的问题,而且也减少了编译耗时。像宏(macro)、预处理命令(preprocessor directives)、非 export 的声明,在模块内对外都是不可见的,因此不会影响导入了模块的翻译单元的编译。
当一个模块编译完成一次后,它的结果就被保存在一个二进制文件中,描述了所有的 export 类型、函数和模版。这个文件可以被很快地进行操作处理,比头文件要快,而且每当模块被导入时,编译器都能够进行复用。
1.4、type-check
Swift 和其类型系统融合了很多流行的语言特性,而 Swift 的类型推断可以让类型信息双向传递,比如:
|
|
类型信息可以从表达式树的叶子 pi 即 Double 类型流向(flow)根 three,也可以从上下文中的根 eFloat 流向叶子 2.71828。这不同于主流的编程语言(C++、Java、C#、OC)。Swift 实现这种双向类型推断,是用了一种基于约束的类型检查(constraint-based type checker),可以更直接通用地表达语义,与解析器(solver)的具体实现分离。Swift 包含有约束的多态类型和函数重载,使得实现更为复杂,而 Swift 限制类型推断的范围为单条表达式或语句,主要是为了提供更好的性能以及提供更好的问题诊断信息(diagnostics)。
对于类型所施加的约束有很多种(只简单列下 3 个以做举例说明):
- Equality。类型相同。
- Subtyping。包含关系(相同或子集)。
- Conversion。第一种类型可以被兼容地转换为第二种类型。
类型检查会在 3 个主要的阶段进行:
- 约束生成。给予输入的表达式和额外的上下文信息,生成一系列描述子表达式类型之间关系的类型约束。生成的约束可能包含有未知的类型,以类型变量(type variables)来进行表示,然后会由解析器来确定其类型。
- 约束解析。通过把确切的类型赋给类型变量来解析系统的(system、系统类型)约束。约束解析器需要在众多的候选之中选出具体的类型。
- 应用解析。给定输入的表达式、一系列由表达式生成的类型约束、一系列绑定到类型变量的确切类型,要生成一个类型完好的表达式,把所有的隐式转换变得明确,把所有的未知类型和重载都解析完成。这个阶段不能够失败(fail)。
1.5、SCC(strongly connected component)
根据维基百科描述:在有向图(DAG)的数学理论中,如果一个图的每一个顶点都可从该图其他任意一点到达,则称该图是强连通的。在任意有向图中能够实现强连通的部分我们称其为强连通分量。判断一个图是否为强连通以及找到一个图强连通分量只需要线性时间。
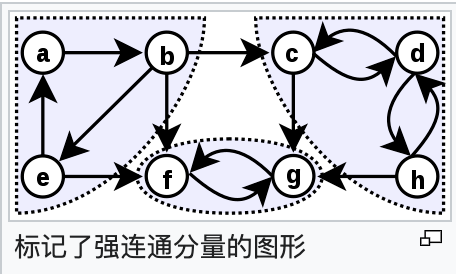
因为在 call graph 当中可能会存在循环,而 pass 遍历图的顺序是可以以 SCC 顺序来进行遍历的,SCC 的那部分被当作了一个整体(单个节点)。
2、Whole Module Optimizations (WMO)
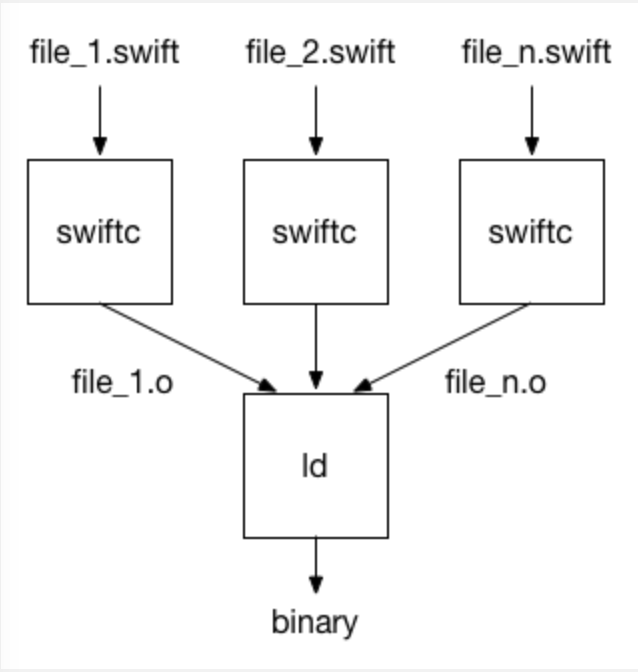
Swift 编译器默认是独立地编译每一个文件(如上图所示),这可以让 Xcode 快速并行地编译多个文件,每个编译都是一个独立的进程在进行。但是,独立地编译每一个文件也意味着无法进行更好的编译优化。实际上,Swift 编译器也可以把整个模块当作一个文件来进行编译,然后当作一个编译单元(compilation unit) 来对整个程序进行优化。这种模式在 swiftc 的命令行下的 -whole-module-optimization 参数开启。在这种模式下,也会花更多的时间去编译,但程序的运行性能会更高。在 Xcode 当中也有对应的编译配置选项 ‘Whole Module Optimization’。
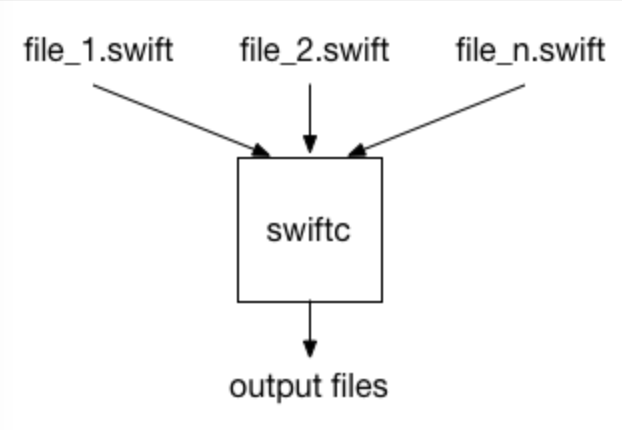
WMO 模式可以让编译器一次性编译一整个模块的源代码,让优化器在编译遇到独立的声明时有了模块层面的信息。而一个内部的声明是对模块外不可见的,所以优化器可以通过发现所有潜在的重写(override)的声明,推断出是否具有 final 属性。因为 Swift 默认的访问控制级别是 internal,所以这样操作可以对其进行脱虚优化操作(devirtualization)。还有跨函数优化、函数内联、函数特化(function specialization,模版特化、范型类型确定化)、优化计数器(GC 垃圾回收)、无用代码去除等优化。
2.1、编译模式
编译模式是用来控制 driver 和编译器前端任务的行为,在 Swift 中主要有以下几种(以一个模块内有 100 个源文件作为说明):
- primary-file。这种模式下,driver 会把工作划分给多个编译器前端的进程,生成局部的结果,然后当编译器前端完成任务后进行合并。每个编译器前端的任务是从模块中读取所有的文件,读取需要编译的主要文件(primary-file,可能有多个),懒加载分析对于模块的定义引用。这种模式下也有两种子模式:
- single-file。对每个文件运行一个编译器前端任务,每个任务只会有一个主要文件。 【会运行 100 个编译器前端子进程,每个都会解析所有 100 个输入的源文件(因为会存在模块内的互相引用,所以总共会有 10,000 次解析),每个子进程会把定义编译到自己的单个主要文件当中。】
- batch。在每个 CPU 核上运行一个编译器前端任务,将一批大小数量相同的模块文件(module‘s files,意为模块里的文件)都当作是主要文件。
-enable-batch-mode。 【系统有 4 核 CPU 就会运行 4 个编译器前端子进程,每个都会解析所有 100 个输入的源文件(总共会有 400 次解析),然后每个会编译 25 个主要文件(即 1/4)。】
- WMO。这种模式下,driver 为整个模块运行一个编译器前端任务,前端会一次性读取所有模块内的文件然后一次性一起编译完。
-wmo或-whole-module-optimization。 【只会运行一个编译器前端子进程,一次性读取所有 100 输入的源文件(总共 100 次解析),然后一次性地线性顺序编译所有文件。】
primary-file 模式可以进行增量编译,高效地进行并行操作,坏处就是每个前端任务都需要读取模块内所有的源文件,意味着两次的重复操作,任务量倍数级增长。
WMO 模式可以进行整个模块的优化,也不需要重复读取源文件了,但坏处是每次都会重编所有源文件,在 LLVM IR 后端代码生成之前的操作,都无法进行并行操作。
2.2、编译器操作
那么编译器是如何整合多个文件来一起编译,在 SIL(Swift Intermediate Language) 优化器完成了所有 Swift 的重要特定优化(Swift-specific optimizations)之后,模块会被再次分割为多个部分,LLVM 后端再多线程处理这些分离的部分。所以即使是 WMO 下,编译器后端依然可以并发或增量编译操作。
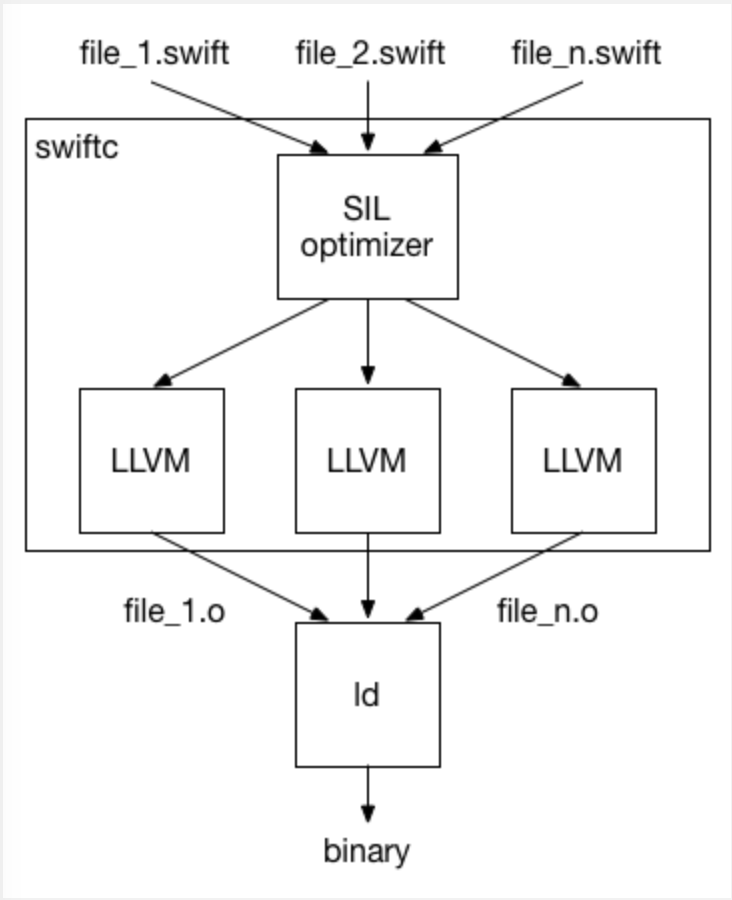
当 -whole-module-optimization 参数传递给 Swift 后,编译模式就改变了,这种模式下,driver 就只会触发一次编译器前端(frontend)编译,同时不会有主文件(primary file)的概念。相反,每个文件都会被解析(parse)和类型检查(type-check),之后所有生成的代码会被一起进行优化。
整个模块一起编译实际上有两种方式:多线程(thread)和单线程(non-thread)。默认是单线程的,会为整个编译单元生成一个目标文件。如果想生成很多目标文件,可以使用 -o 和 -c 参数来控制每个目标文件的输出。
在多线程模式下,一个目标文件的生成对应一个输入的源文件,然后编译器后端(backend)会在多线程下对生成的代码进行处理。和非 WMO 模式编译一样,目标文件的位置是由输出文件映射表(output file map)来控制的。多线程模式由命令行参数 -num-threads 控制。
2.3、实现
先来看看 Xcode 是如何进行组织的,在普通编译模式中,module 里面的源文件会被各自进行编译,最后再合并成一个 module。这里图中的展开,实际上就相当于给 swiftc 加上了 -driver-print-jobs 的参数,即下方展开的,实际上就是编译所进行的任务。
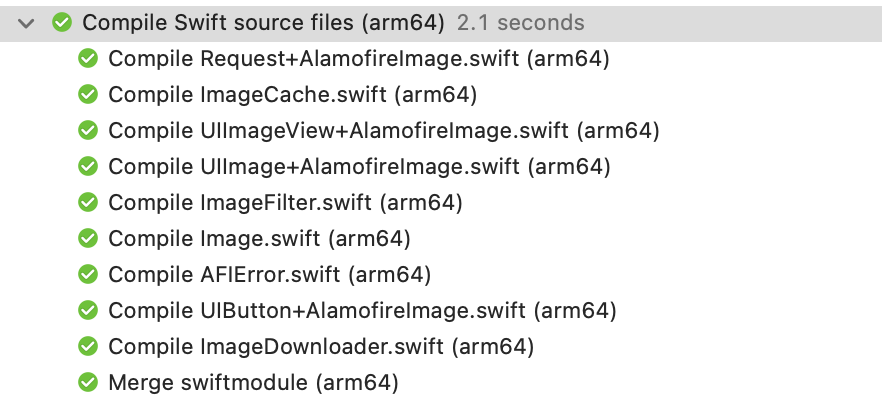
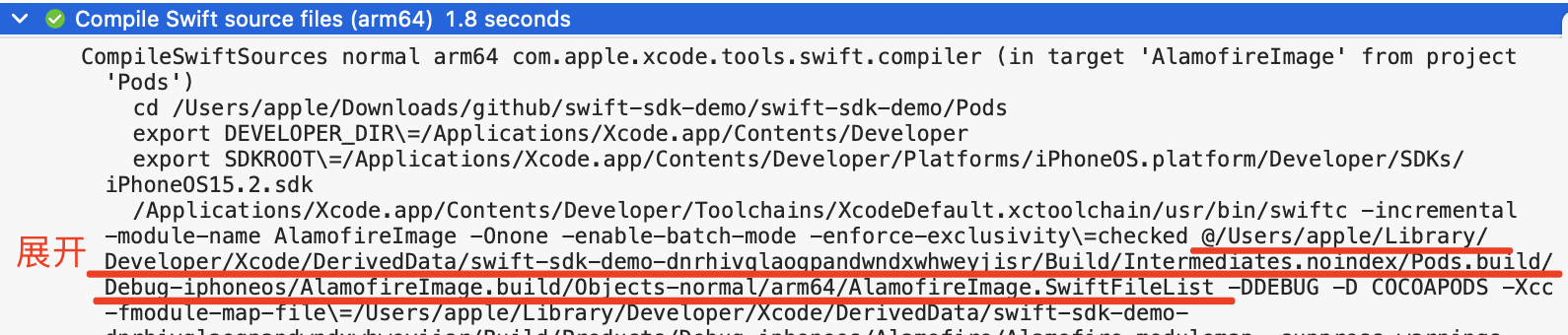
而 WMO 下,会把模块下所有的源文件都组织起来一起编译,编译器实际上是把 WMO 的参数,转换成源文件一起编译的方式。

实际上编译参数的差异主要是 -whole-module-optimization,然后来看一下 Swift Driver 当中的实现。
|
|
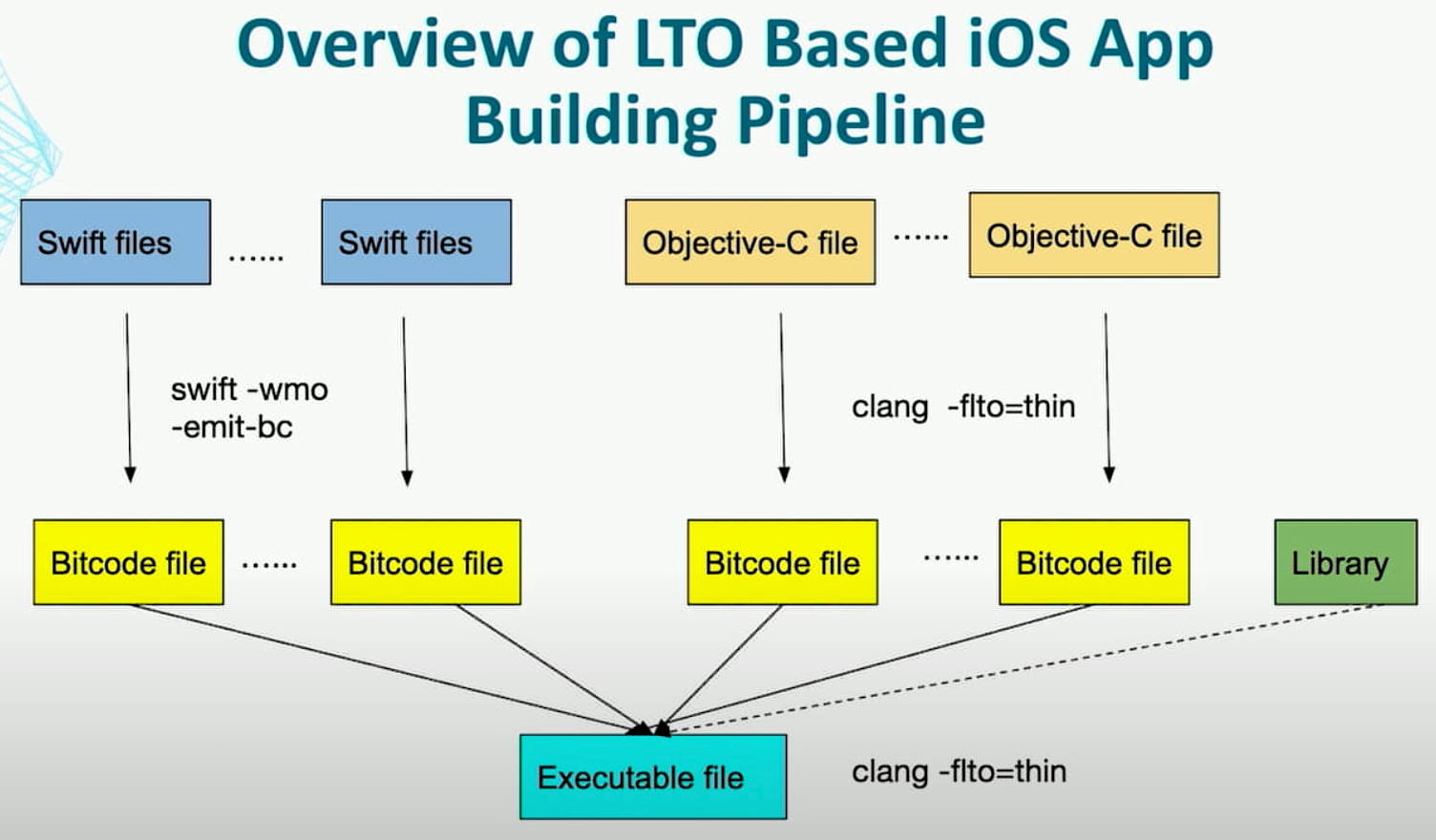
2.4、与 LTO 的区别
WMO 的优化范围是一整个模块内的,是一次性编译一整个模块内的所有源文件。
而 LTO(link-time optimization,之前我写过一篇介绍,感兴趣可以翻翻) 是对整个程序范围内的优化,是跨模块的,而且优化是放在链接期来进行,而编译器只是先把所有文件都编译成一种 IR(bitcode) 的中间格式。LTO 有两种模式,一种是 monolithic 模式直接把所有的输入当作一个翻译单元进行处理,另一种是 thin 模式实现了更好地并行性,会生成紧凑格式的描述信息来代表每个模块,用来进行全局的分析,以 SCC 作为边界(boundary)更好地提升了并行能力以及减少了内存的使用。
一个 Swift WMO 结合 LTO 的方式:
参考
- Whole-Module Optimization in Swift 3
- 编译原理初学者入门指南
- C++ language documentation
- Type Checker Design and Implementation
- Writing High-Performance Swift Code
- Swift Compiler Performance
- 强连通分量 - 维基百科
- What does SCC stand for, with respect to LLVM?
- Difference between WMO and LTO
- 2019 LLVM Developers’ Meeting: J. Lin “Link Time Optimization For Swift”
- ThinLTO_EuroLLVM2015
- How Uber Deals with Large iOS App Size
- An Experience with Code-Size Optimization for Production iOS Mobile Applications
- [RFC] A Unified LTO Bitcode Frontend
- RFC: ThinLTO Impementation Plan
文章作者 calssion
上次更新 2022-04-17