LLVM JIT 的运用:WebKit FTL JIT
文章目录
之前写了篇文章介绍 LLVM 的 JIT,然后就想看看关于它的一些应用,偶然看到了 WebKit 对它的一个使用,感觉文章内容很不错。本文主要参考 Introducing the WebKit FTL JIT,原文非常地细致,另外,本文还参考了 LLVM 记录的文章。这些都是旧文了,现在 FTL 已经用 B3(Bare Bones Backend)替换了,不过还是值得一看的。
WebKit 是开源的浏览器引擎,大量的应用如 Safari 都在使用,但本文的重点是 WebKit 为什么以及如何引入 LLVM JIT。
如今的网站都提供着大量的高度动态化的 JavaScript 代码,但却只运行较短的时间。这些代码的主要消耗是加载它们的时间和用于保存它们的内存。
WebKit 在 r167958 开始,引入了 LLVM-based just-in-time(JIT) 编译器,简称为 FTL(Fourth Tier LLVM),在 Mac 和 iOS 端是默认开启的。这是 LLVM 的一个重大里程碑,因为它证明了 LLVM 可以用来优化动态类型的语言,这也是第一次运行时信息(profile guided information)被用在 LLVM JIT 里。
1、WebKit JavaScript Engine
先介绍在引入 FTL JIT 之前,原本的 WebKit JavaScript Engine 的工作机制。
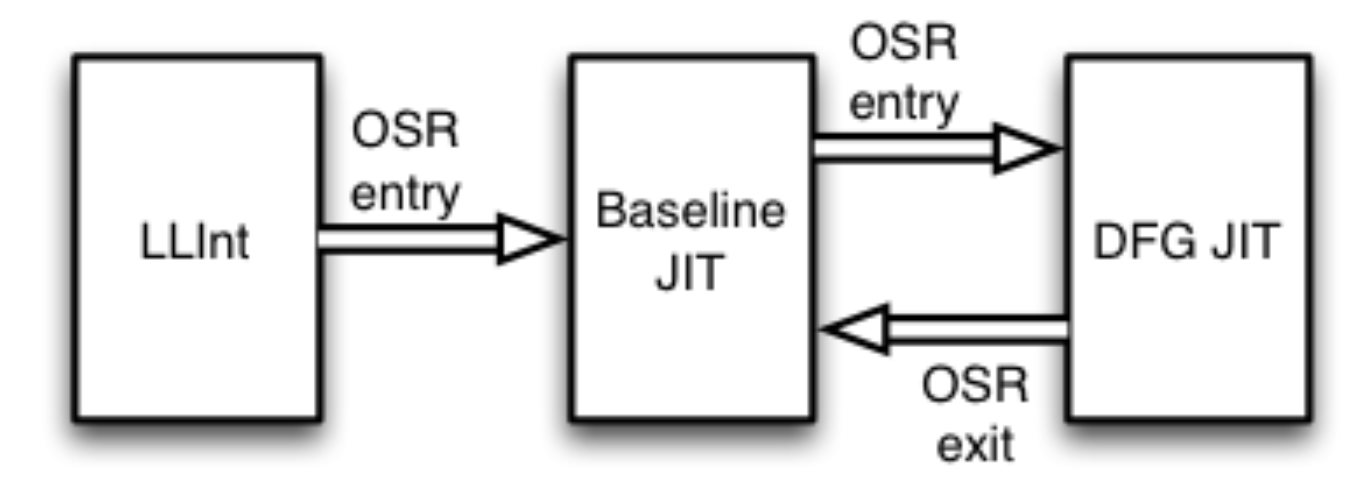
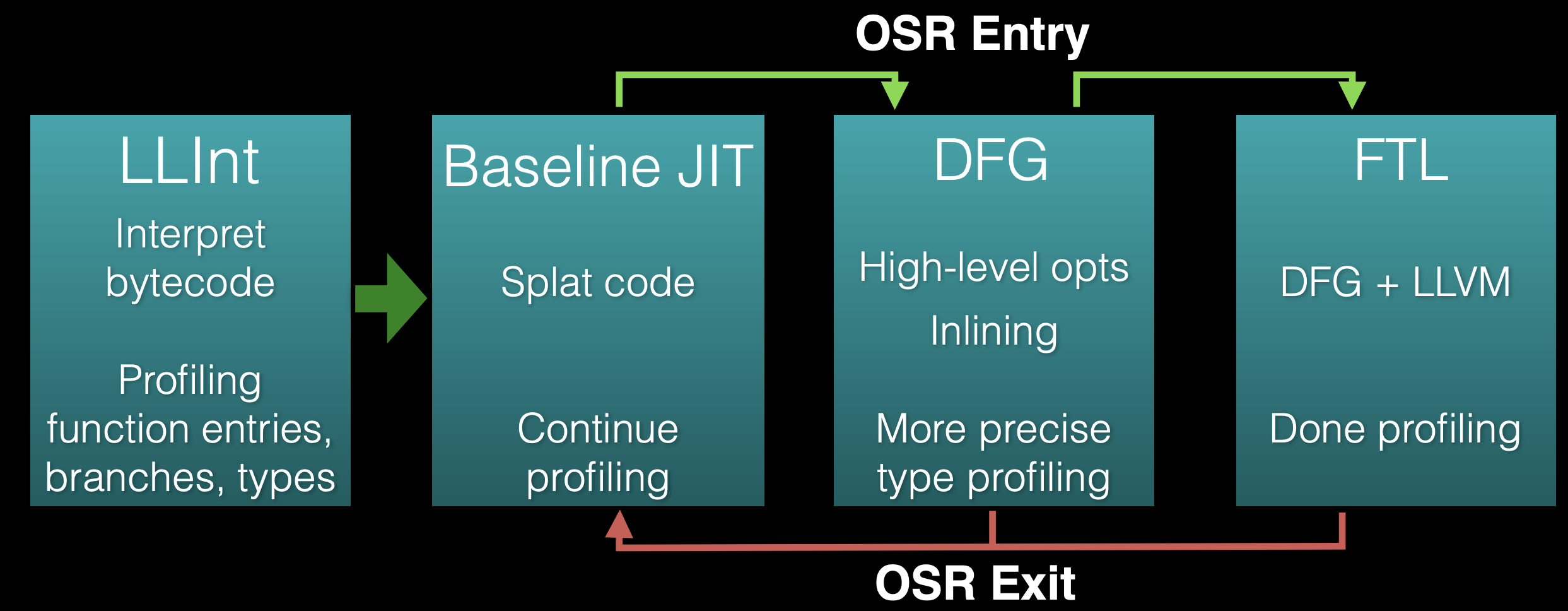
上图是 WebKit 三层(three-tier)架构。箭头代表的是栈替换(on-stack replacement,OSR)。
运行时可以根据每个函数从这三个执行引擎(层)中选取使用。它们会以内部的 JavaScript bytecode(字节码)作为输入,然后用不同的优化级别进行编译或翻译。
这三层分别是 LLInt(Low Level Interpreter)、Baseline JIT、DFG JIT(Data Flow Graph)。LLInt 针对低延时进行优化。Baseline JIT 是直接将 JavaScript 转成机器码的一个转换。而 DFG JIT 是针对高吞吐量进行优化,它有自己的高层级 IR 来做优化。
所有函数的第一次执行都是在解释层 LLInt 进行的,一旦函数的任意语句执行超过 100 次,或者函数被调用了超过 6 次,执行会被转移给 Baseline JIT 进行代码编译,这会消除解释器的一些开销,但是还缺乏重要的编译器优化功能。一旦 Baseline 中的任意语句被执行超过 1000 次,或者 Baseline 函数被调用超过 66 次,执行会被转交给 DFG JIT。执行的转移几乎都是采用栈替换(OSR)的技术实现,OSR 让我们可以不管执行引擎如何,直接在字节码指令边界对字节码状态析构,并为任何其他引擎重新构造它,以便可以继续执行。
这三层策略很好地平衡了低延时和高吞吐量。如果每条语句只执行一次,那么编译是会比解释更耗时的,因为 JIT 也需要遍历并转换字节码中的所有指令。对于频繁执行的代码,大概有四分之三的执行时间,LLInt 会花费在间接跳转(indirect branch),这也是为什么转移到 Baseline JIT 的次数设置如此,因为 JIT 会抹除解释器执行转移的开销,但它和解释器生成的代码类似,所以 Baseline JIT 生成代码很快,还遗留了很多性能优化的操作给 DFG JIT 来进行。
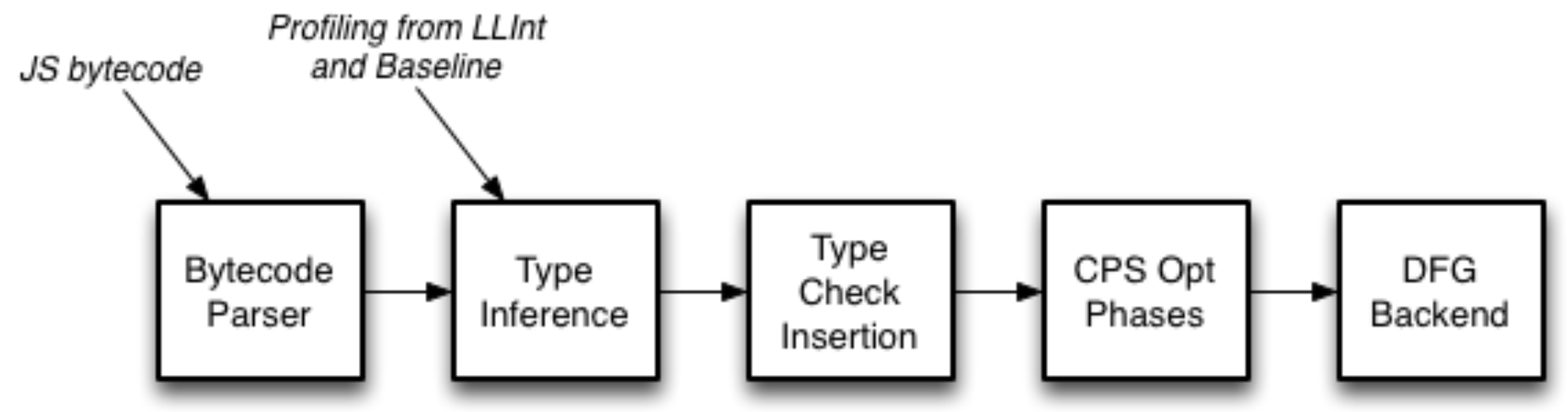
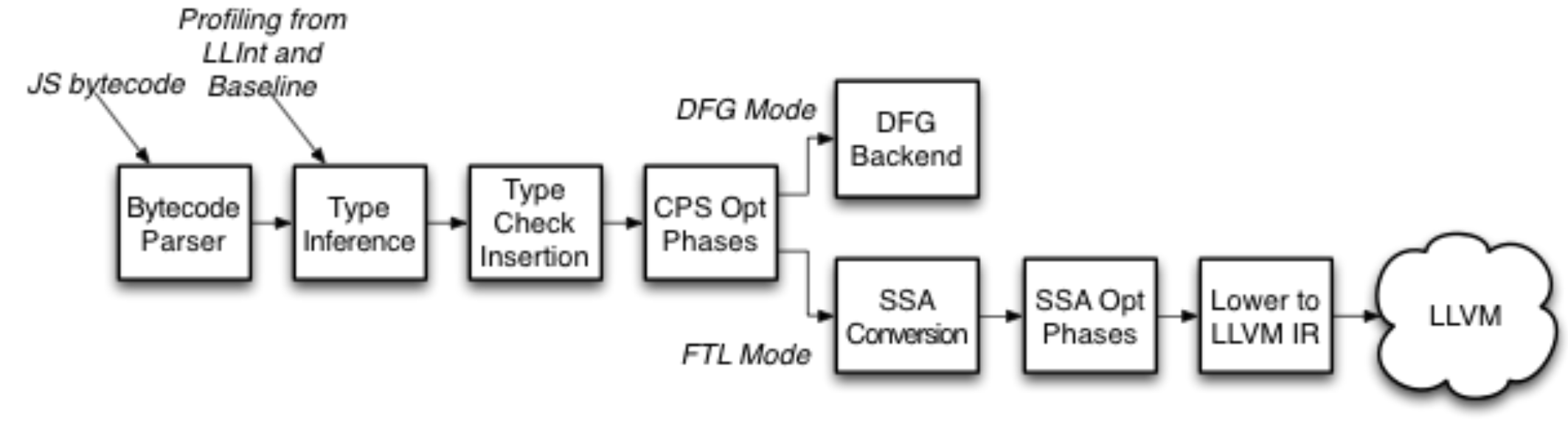
上图是 DFG JIT 的优化流程,它会把字节码转成 DFG CPS(continuation-passing style) 格式,代表变量和临时变量之间的数据流关系。然后使用 profiling information(运行时信息)来推断类型,推断结果会被用来插入最小化的类型检查集合。然后就是传统的编译器优化(寄存器分配、控制流图简化、公共子表达式消除、死代码删除、常量传播等)了,最后编译器会直接从 DFG CPS 格式生成机器码。
因为传统的编译器优化需要有变量的类型信息以及堆对象的结构,所以会使用 LLInt 和 Baseline JIT 采集到的运行时信息和类型推断的预测反馈。
|
|
像上面的代码案例,我们无法断定 a 和 b 是什么类型,所以 LLInt 和 Baseline JIT 会收集变量运行时信息(value profiles),每一次的执行都是对该信息的补充。比如,如果变量是整型,那么 DFG 就会在编译这个函数时,加上整型的检查和相加的溢出检查。如果检查失败,那么 DFG 会通过 OSR 把执行转移回给 Baseline JIT,也即 DFG 的特定类型优化操作还不适用于该函数。
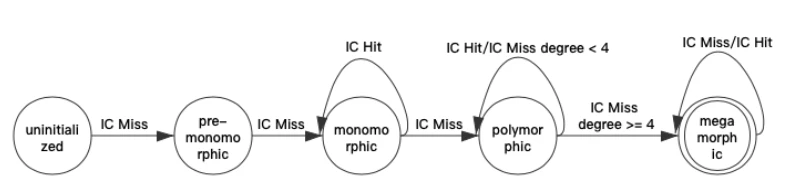
Baseline JIT 的运行时信息还有多态内联缓存(polymorphic inline caches,IC),通过记住以前直接在调用点上方法查询的结果来加快运行时方法绑定的速度,这是用于优化多态派发的。
|
|
比如上面的代码案例,o 的类型是未知的,Baseline JIT 初始时会通过完全的多态派发的方式来执行其变量访问,但它同时也在记录其操作的次数,然后在达到一定次数时,修改堆访问的方式为缓存(caches)访问的方式。
比如 f 一直是在对象基址偏移 16 的位置,那么代码会被修改从而实现一次对 +16 位置是否存在 f 的对象检查。这时缓存就可以说是内联的(inline),因为它们能被生成的机器码完全表示。它们也被称之为多态的,因为如果遇到不同的结构体对象,在进行完整的动态成员查找之前,机器码会被修改为之前遇到的对象类型。
当 DFG 编译这块代码时,会检查这部分内联缓存是否是单一态的,可以对单一对象的结构体进行优化,检查是否可以生成直接加载的方式。而如果对象 o 一直带有固定偏移量的成员 f 和 g,那么 DFG 只需要检查 o 的类型,从而对这两个成员实现直接加载的方式。
2、FTL(Fourth Tier JIT) 架构
DFG JIT 的调整,会给运行时间长的代码(long-running code)带来更激进的优化,提升了性能;但是对于运行时间短的代码(short-running code)是一种伤害,因为 DFG 生成的代码并不够优化,导致编译时间占总运行时间的比重显得很大。DFG 没法同时是低延时和高吞吐量的,生成更好的代码意味着更多的编译耗时。所以引入了第四层 FTL,用来平衡这之间的问题。
FTL 对 DFG 后端进行了替换,把 DFG IR(intermediate representation,中间码)转换成 LLVM IR,然后调用 LLVM 的优化操作,用 LLVM MCJIT 后端来生成机器码。
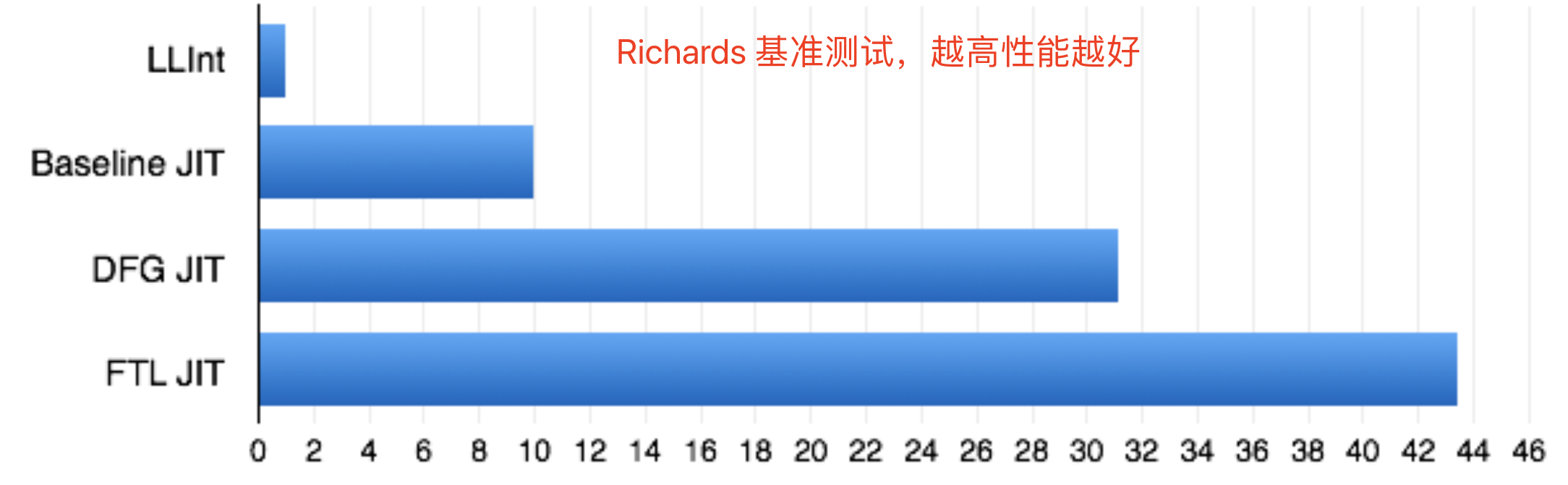
FTL 在 js 的执行时间平均比 DFG 快了 35%。
DFG 后端生成机器码,虽然很快,但是几乎没有进行任何低层级(low-level)的优化,转换成 SSA 之后就可以执行额外的优化了。转换成 SSA 实际上比原始的 DFG CPS 格式更耗性能,但是 SSA 保证了更强大的优化。因为 LLVM IR 也是基于 SSA 的,转换成 LLVM IR 并不困难,后面就可以直接执行 LLVM 的流程了。
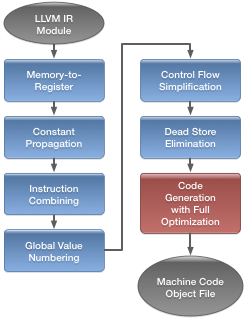
LLVM IR 是静态类型的,而 DFG 的类型推断可以帮助动态语言很好地转换为 LLVM IR,每次转换都是在剔除动态化:WebKit’s bytecode -> DFG CPS IR -> DFG SSA IR -> LLVM IR。
3、集成 LLVM
FTL 是利用了 LLVM MCJIT 框架来实现运行时编译。
3.1、编译时间
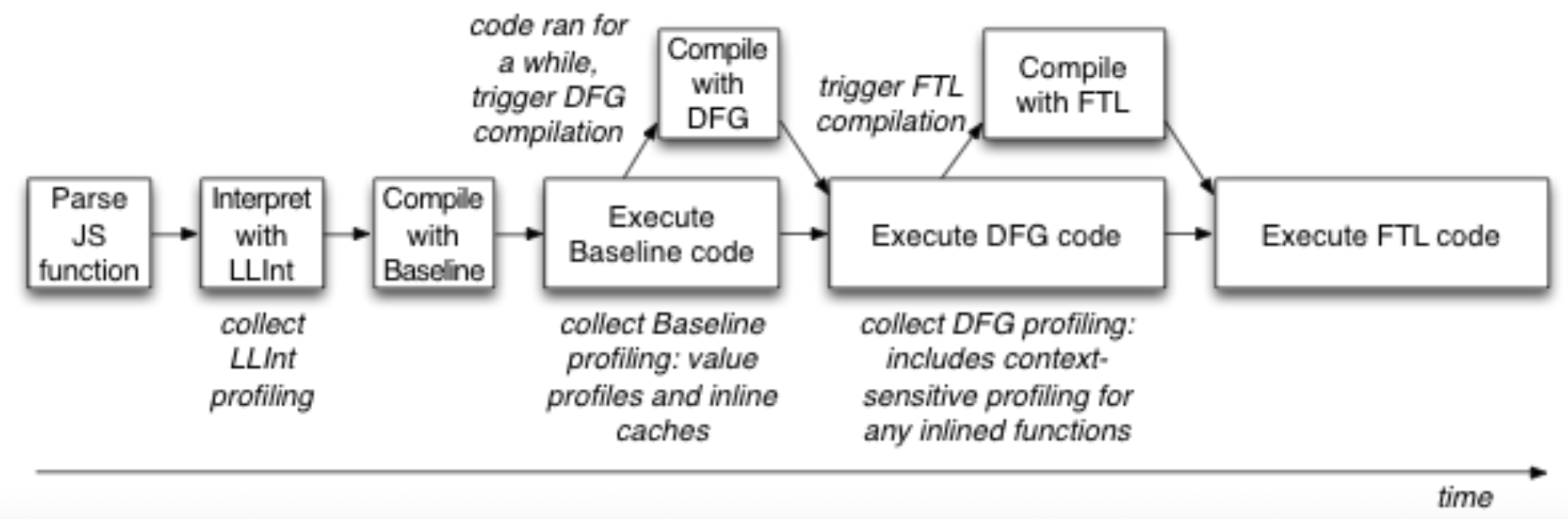
相比于原有的 JIT,LLVM 的编译耗时更多,FTL 只在 LLInt、Baseline JIT、DFG JIT 运行过后才会触发。
所以 FTL 对于运行时间短代码而言采用 DFG 后端,除非执行次数很高;而对于运行时间长的代码而言,通过使用并发和并行的手段调用 LLVM 来减少开销。
3.2、兼容垃圾回收
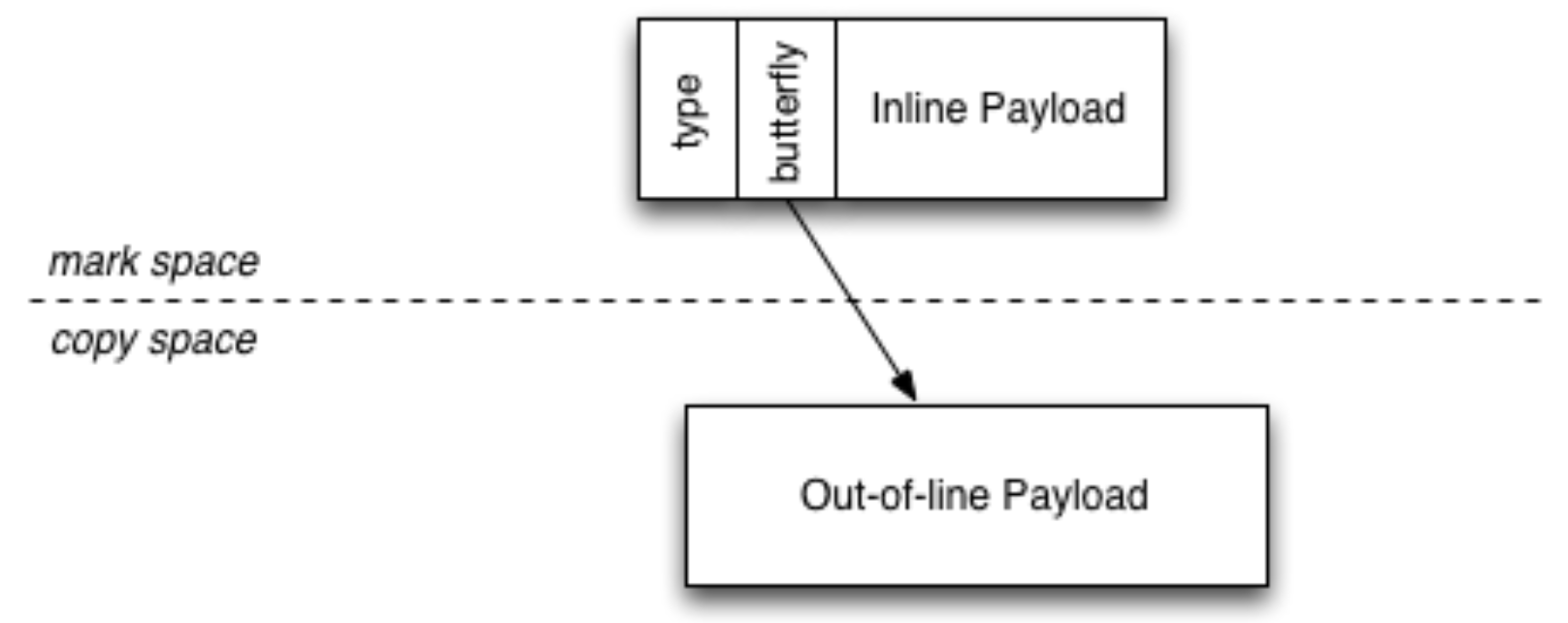
上图是 WebKit 中 JavaScript 的对象模型。WebKit 采用分代垃圾回收算法,为对象单元(cell)提供固定的空间,持有固定大小的数据,和混合了 mark-region/copy 空间存放的可变大小的数据。对象的代(generation)由 sticky mark bit 来进行跟踪。
在集成 LLVM 时,为了最大化吞吐量和垃圾收集的精度,LLVM 并不需要知晓垃圾回收的存在。
我们使用 Bartlett 垃圾收集方式,堆内存的对象需要有类型映射表来告知它们的域哪部分有指针,以及这些指针应该如何解析。有了这些信息后,只能被其他堆对象访问到的对象可能会被移动,而且指向它们的指针可能会被更新。而栈上的不需要映射表,它们被固定认为是从栈上的引用。垃圾收集进行栈扫描时需要:1、保证它读取了所有的寄存器,而不是栈;2、保守地认为每个具有指针宽度的字(内存大小)都可能是一个指针;3、锁定任何看起来可以从栈访问的对象。这意味着编译器编译 JavaScript 可以对值进行任何操作,而不需要知道它是否为指针。Bartlett 的垃圾收集方式使 WebKit 可以兼容 LLVM 后端。
3.3、OSR enrty
在进行执行转移(栈替换,OSR)时,函数可能是执行了很长一段时间都还没返回,所以在控制执行转移到什么地方是个难题。
当进行执行转移时,从 LLInt 转移到 Baseline JIT 是比较容易的,因为它们的表现(指令码)类似,只需要跳转到对应的代码地址即可。转移到 DFG JIT 会复杂一点,因为它的语句完全不一样,所以 DFG 会把函数的控制流图当作有多个入口(entrypoints),一个入口是函数的起始地址,还有些入口在每个循环的头部。所以 OSR 转移进入 DFG 会像是一个特殊的函数调用。
但 FTL JIT 很不一样,我们希望 LLVM 的语句能有最大程度的自由,而且 LLVM 假定每个函数只有一个入口,还有 LLVM 会对执行路径(从某个函数调用进来)进行优化操作。
最后方案是我们为想要使用的入口,创建一个独立的函数的副本。当一个函数的调用次数满足触发 FTL 编译,我们假设这个函数最终是会返回的,并且会重新调用进 FTL 版本的。但如果 DFG 版本的函数在我们有 FTL 编译后还是调用频繁(hot),我们可以推测是因为在执行循环,然后我们假设更好的方式是进入那个循环体。我们触发对该函数的第二次编译,但是是以循环体头部(loop pre-header)作为函数的入口,称之为 FTLForOSREntry 的模式。这包含了我们为函数从 DFG IR 转换创建新的起始代码块,并且还要从全局缓冲区加载执行循环的所有状态。这个起始代码块会跳入到循环执行,而这之间的代码会变成死代码。
3.4、Deoptimization
OSR exit 转移和 OSR entry 是一致的,这里要说的是 deoptimization。我们希望我们的编译器可以做到以下几点:
-
Partial compilation。让部分函数不编译,从而省下内存和编译时间。FTL 需要处理很多的检查导致的出口(回退到 Baseline JIT),急切地让 LLVM 来编译这些路径是不合理的,我们希望这些路径会在之后被修补(patch)。
-
Invalidation。DFG 的优化流程是可以嵌入对堆对象和变量的运行状态的监控(watchpoints),比如,可以用来推断变量是否为常量,用来作为无效化某些优化代码的依据。
-
Polymorphic inline caches。堆内存访问和函数调用都可能是多态的,所属类型的集合可能是很大的,最好的处理方式是 inline cache,一种动态脱虚(dynamic devirtualization)的方式,当操作产生变化,可以重新匹配类型。
上面这些可以被认为是自修改(self-modify,自修改代码是指程序在运行期间修改自身指令)的内联汇编,但是是在低层级的机器码内容层面上,需要判断使用什么寄存器和栈地址。这部分内容是由 LLVM 来决定的,我们称之为 patchpoint(修补点),会被暴露给 llvm.experimental.patchpoint 的 intrinsic(编译器的内置函数,用于后端优化)。patchpoint 是一个关键的 LLVM 特性,有了它,就可以进行动态类型检查、内联缓存、运行时安全检查,而不需要很多性能的消耗。
patchpoint 实际上是两个特性存在于一个 intrinsic,第一个特性是可以找到特定值(变量)的地址,LLVM 会把这些信息记录在 metadata(元信息),称之为 stack map,用于读取变量来重建栈帧(FTL deoptimization,OSR exit);第二个特性是运行时在特定地址对编译好的代码进行修改,会预留固定大小的指令空间以及使用 stack map 记录其地址。这两个特性需要被结合成一个 intrinsic 使用。
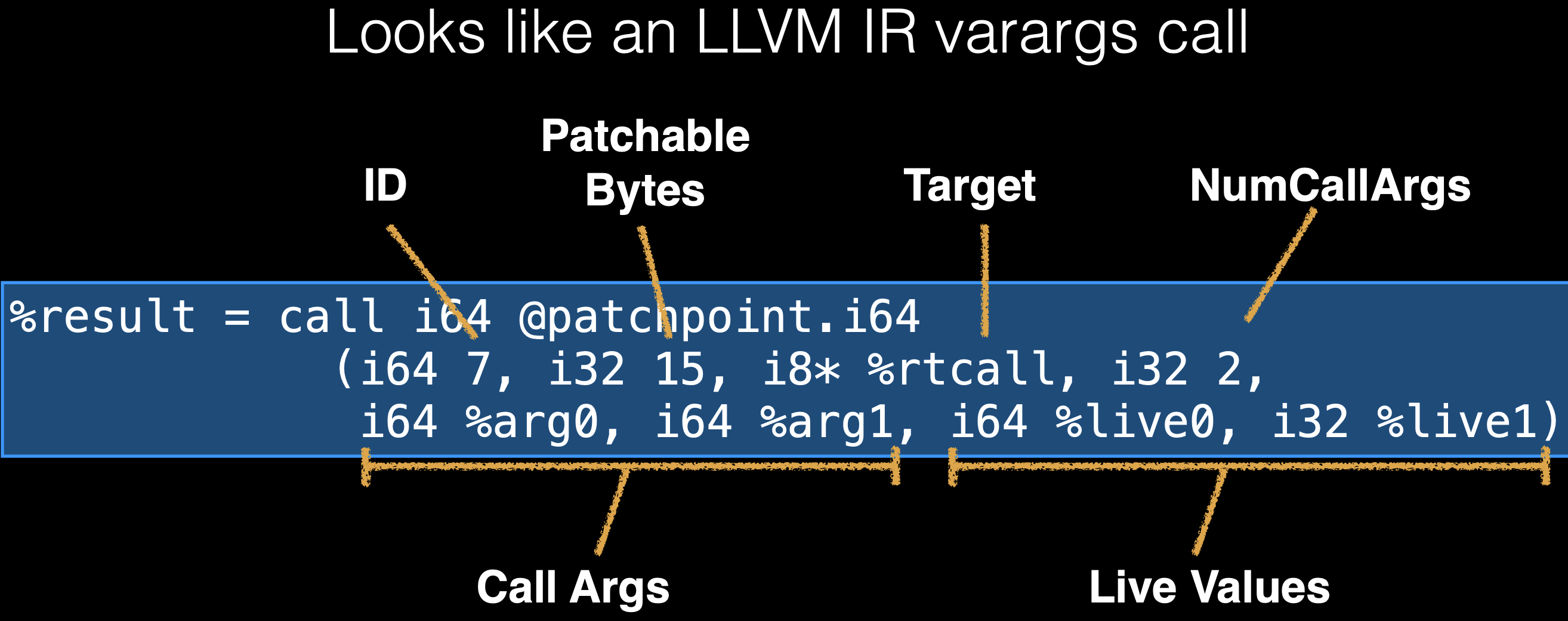
WebKit 使用 LLVM 的 patchpoint 工作流程如下:
-
WebKit 决定哪些值在 patchpoint 是需要用的,选择这些值的表示(representation)的限制(寄存器读取、内存读取等)。还需要选择代码片段的字节大小和返回类型。
-
LLVM 生成空指令序列(nop sled),大小为 WebKit 选取的字节大小。LLVM 会在一个单独的数据段,记录这些空指令序列出现的位置,用什么寄存器。(stack map)
-
WebKit 为 patchpoint 生成机器码到 nop sled 中。
除了 patchpoint,它还包含有更加限制的 intrinsic 为 llvm.experimental.stackmap,它向 LLVM 保证,只会以无状态跳转(unconditional jump)到外部代码来重写代码。stack map 会记录在某一地址运行时所需要用到的变量的位置。要么 stackmap 没打补丁(patch),什么也不会做;要么打了补丁,则执行不会落到 stack map 之后的指令。这可以允许 LLVM 优化掉 nop sled。
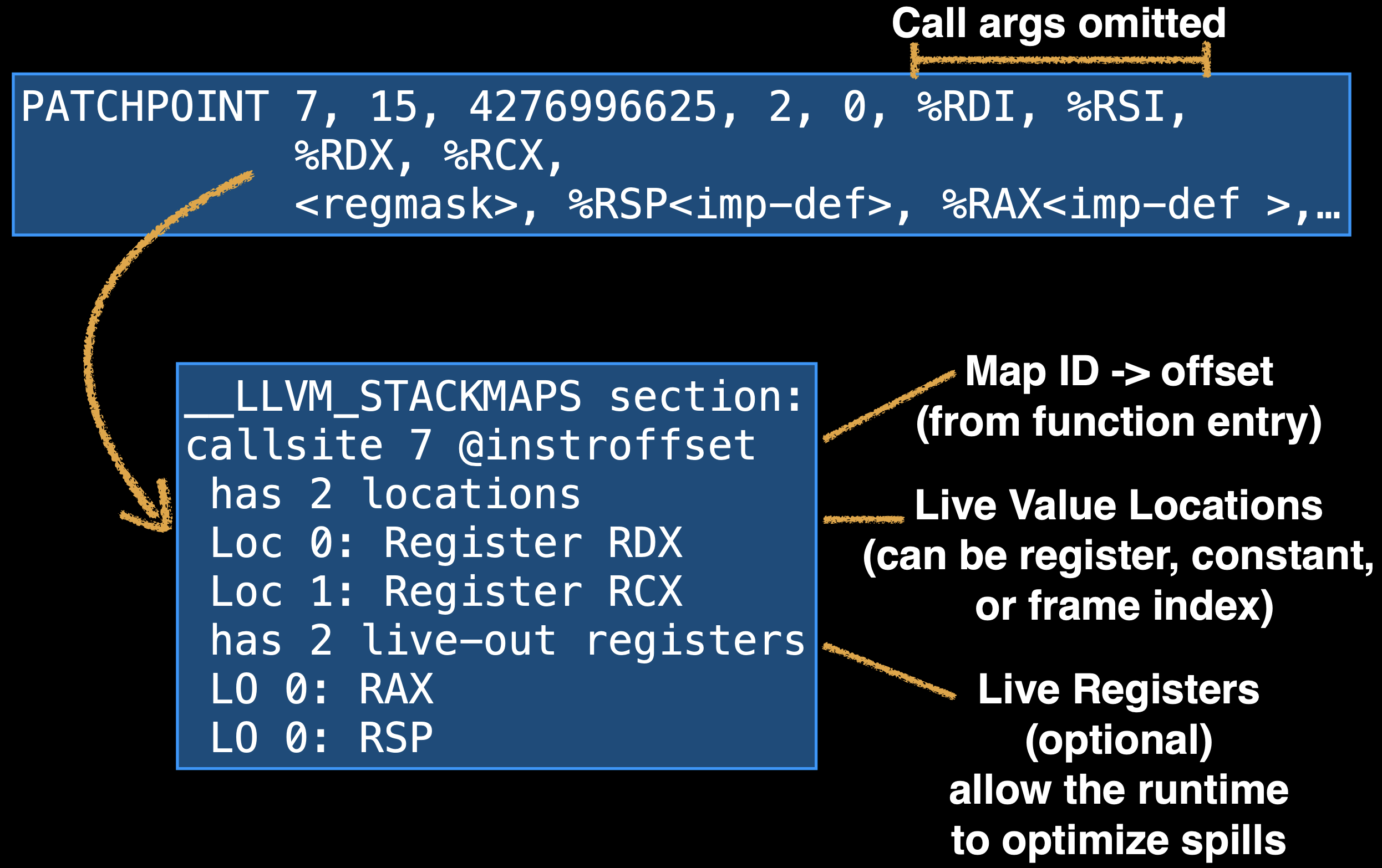
有了 patchpoint 和 stack map,FTL 就可以使用自修改代码的把戏了,而 DFG 和 Baseline JIT 早就可以用来处理多态的代码。这保证了从 DFG 转移到 FTL 不会变慢。
4、B3 JIT
虽然 B3 JIT 不是本文的重点,但还是简单地介绍一下。
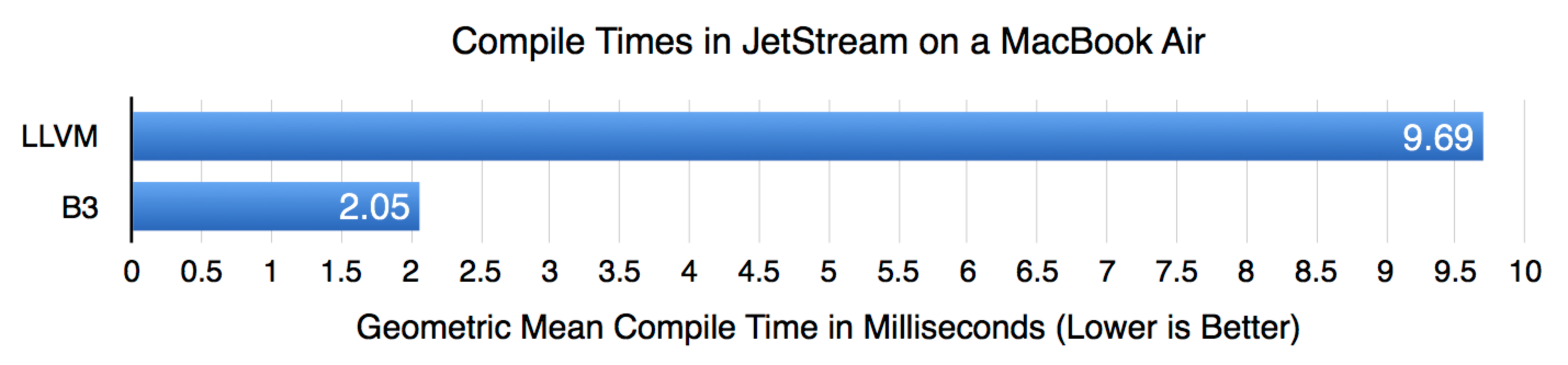
WebKit 现在是用 B3(Bare Bones Backend)替换了 LLVM,连 FTL 的全称都变了,变成 Faster Than Light Just In Time compiler。主要是由于 LLVM 不是专门为动态语言设计的优化,所以 B3 通过调整 FTL 架构来达到更好地优化。
LLVM 还有很多未完成的优化,而且现在 WebKit 的一些优化是采取 FTL 自己的实现,因为需要有对 JavaScript 语义的理解,优化才能完全有效果。还有,LLVM 的编译耗时成为了执行时间的一个瓶颈。
B3 设计有两种 IR,一种轻量高层级的是 B3 IR,另一种机器码级别的是 Assembly IR(简称 Air)。这两种 IR 都是为了最小化内存访问的开销(低层级 IR 需要大量的内存访问表示(representation),意味着编译器在分析函数时也需要扫描大量的内存,导致编译器产生大量 cache misses)。
B3 的 IR 设计主要有 4 种策略:
-
减小 IR 的大小。B3 去掉了冗余的可以之后再计算的信息,Air 调整了所有对象的布局。
-
减少每个操作表达的 IR 的数量。通过封装而不再需要大量的代码块。
-
遍历 IR 时减少指针追踪的需要。尽可能地采用数组来进行线性扫描,这样也能命中同一 cache line。
-
减少 IR 的总数。
B3 已经包含有很多优化了:控制流图简化、流敏感常量折叠、激进的无用代码删除、整型溢出检查删除、公共子表达式删除等。
参考
Introducing the WebKit FTL JIT:https://webkit.org/blog/3362/introducing-the-webkit-ftl-jit/
JS 引擎中的 Inline Cache 技术内幕,你知道多少?:https://www.infoq.cn/article/6xoszzpr1884e70slu9k
WebKit:https://webkit.org/
Stack maps and patch points in LLVM:https://llvm.org/docs/StackMaps.html
FTL: WebKit’s LLVM based JIT:http://blog.llvm.org/2014/07/ftl-webkits-llvm-based-jit.html
FTL - LLVM Developers’ Meeting 2014:https://llvm.org/devmtg/2014-10/Slides/Trick-FTL.pdf
Introducing the B3 JIT Compiler:https://webkit.org/blog/5852/introducing-the-b3-jit-compiler/
文章作者 calssion
上次更新 2021-10-16