MLIR: 多层级通用编译器 IR 简介
文章目录
看到了关于 MLIR 很不错的系列文章,感兴趣可以看下,有中英双文。本文只对 MLIR 的概念和其用来解决的问题做简单介绍。
1、LLVM IR
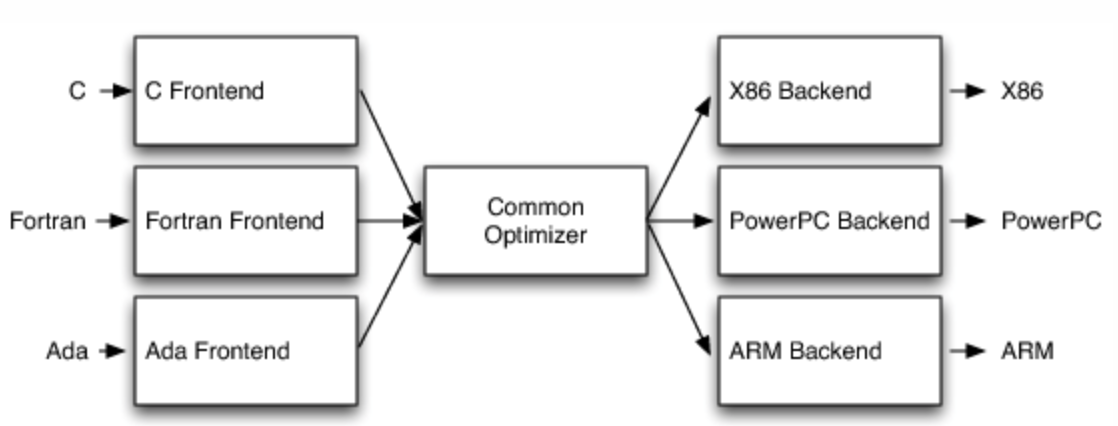
当处理复杂问题时,我们需要抽象化(abstraction),来简化问题。而 LLVM IR(intermediate representation) 在 LLVM 当中就处于一个中间层,独立于目标平台和语言,用来进行编译器优化和代码生成。
|
|
LLVM IR 是低层级的虚拟指令集,指令以三地址码、SSA 格式(static single assignment、静态单赋值,指每个变量只能被赋值一次的特性) 组织,从一系列的输入中输出不同的结果到寄存器中。LLVM IR 还支持标签,看起来像是汇编语言。但与 RISC 指令集不同的是,LLVM IR 会使用简单的类型系统,而且一些机器相关的细节被抽象化了。另一个重大区别是 LLVM IR 的指令不使用具体命名的寄存器,它使用无限的临时字符命名(即假设有无限的寄存器)。

在编译器一步步转换程序的过程中,越来越多的高层次的简明的信息被打散,转换成低层次的细碎的指令,这个过程被称为代码表示递降(lowering);与之相反的过程被称为代码表示递升 (raising)。 后者通常远比前者困难,因为后者需要在芜杂的细节中找出宏观脉络。代码表示递降是编译器的通常转换方式。 不难理解,越晚执行的转换越有结构性劣势,原因是缺乏高层次信息。 —— 《编译器与中间表示: LLVM IR, SPIR-V, 以及 MLIR》
2、Domain Specific SSA-based IR
LLVM IR 过于低层级和独立了,导致不能很好地支持高层级或者说是特定语言(domain specific) 的分析和优化,比如数据流中特定的类型检查(data-flow specific type checking,需要依赖比较准确的代码位置信息)、引用计数优化等。
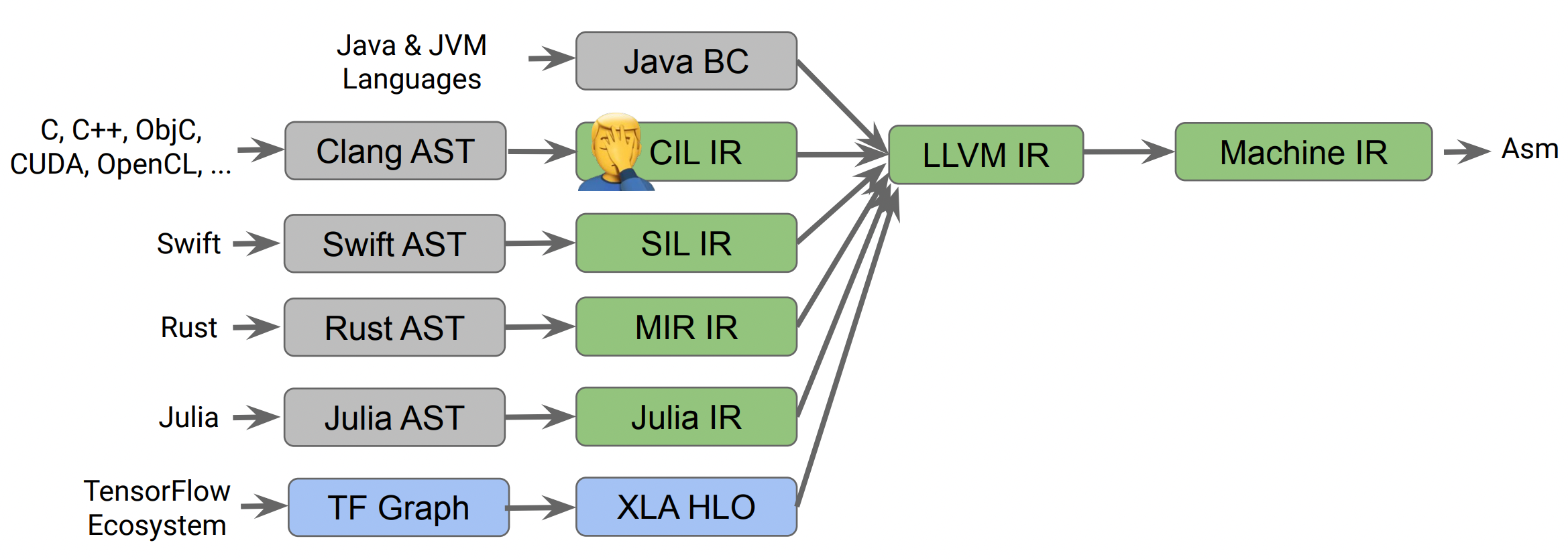
所以我们看到很多语言会设计一套特定语言的高层级的 IR,像 swift 实现了 SIL(Swift Intermediate Language),用来做 swift 特性相关的检查和优化。但像 C 语言转成 Clang AST 之后并没有转换成这样的高层级 IR,因为实现复杂且需要重新实现很多在 LLVM IR 上的操作。
实现一套这样的高层级 IR,好处在于:
- 语言层级的特定分析与优化。
- 层级间 lowering 的复用。
- 有足够的代码位置信息支持流敏感的类型检查。
但是问题在于:
- 需要花很多心力开发。
- 重新实现已有的优化到高层级 IR 上。
- 不通用、其他语言无法受益。
- 处理编译问题:编译时间变长、调试问题、优化实现问题等。

2.1、TensorFlow Compiler
而在机器学习领域也会面临很多的问题,TensorFlow 有很多不同的编译器、基于图的技术和运行时(runtime),但它们没有共享同一种架构或者设计理念,其中一些也没有遵循良好的编译器设计实践方案。
其中也会有很多不同的基于图的 IR(ML graph),可以进行图层级机器学习领域的特定优化,如 operator merging(子图合并),然后再转换成不同编译器后端的 IR,其中也包括 LLVM IR。然而这样对于每种路径,就都需要重新实现优化且基本没有代码复用。
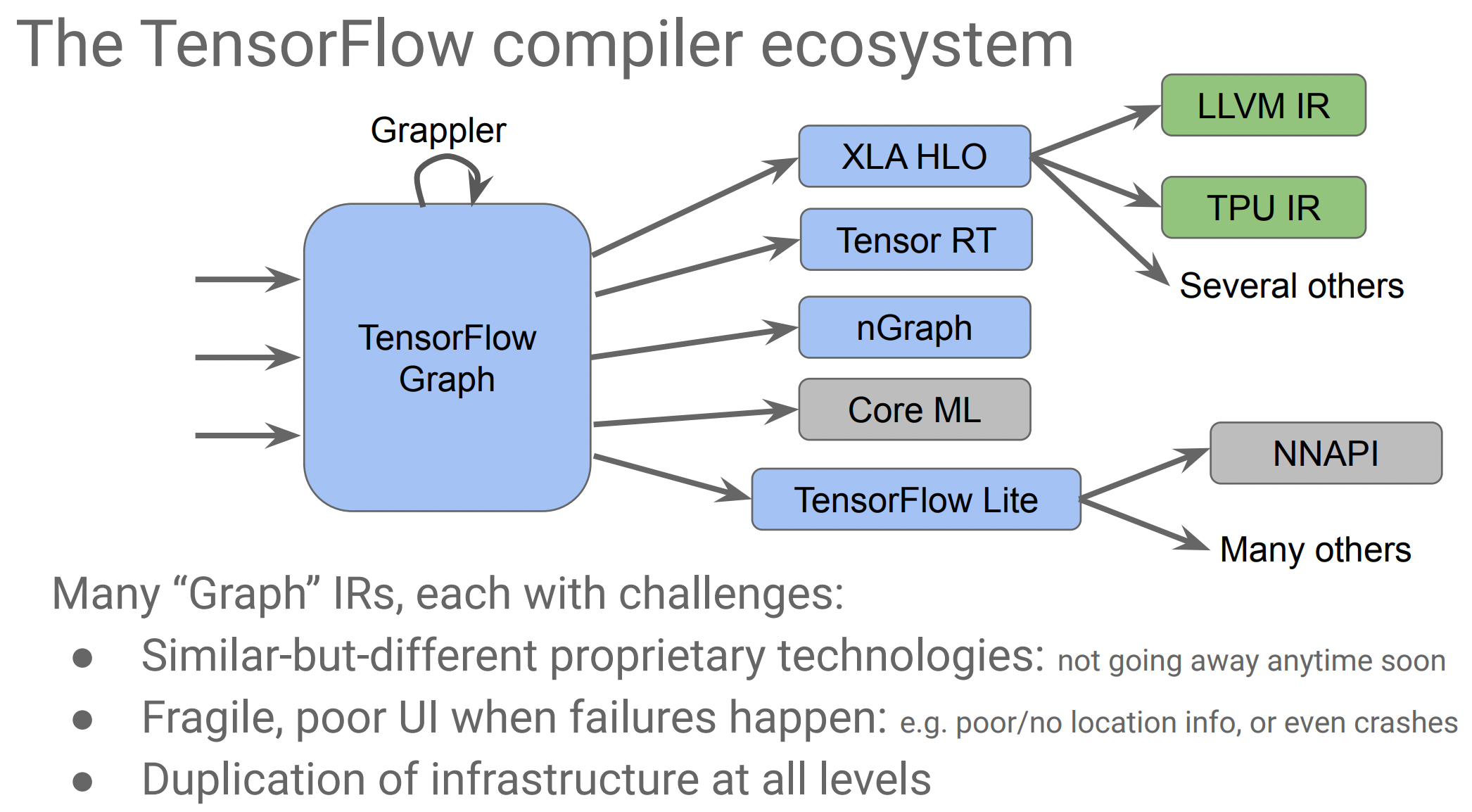
再实现一个高层级的 Domain Specific SSA-based IR 是可以的,但是对于这么多种语言和路径,重复拷贝粘贴特定语言优化的逻辑和代码,不是很通用,可能要为每一种 IR 都写一套。
3、MLIR
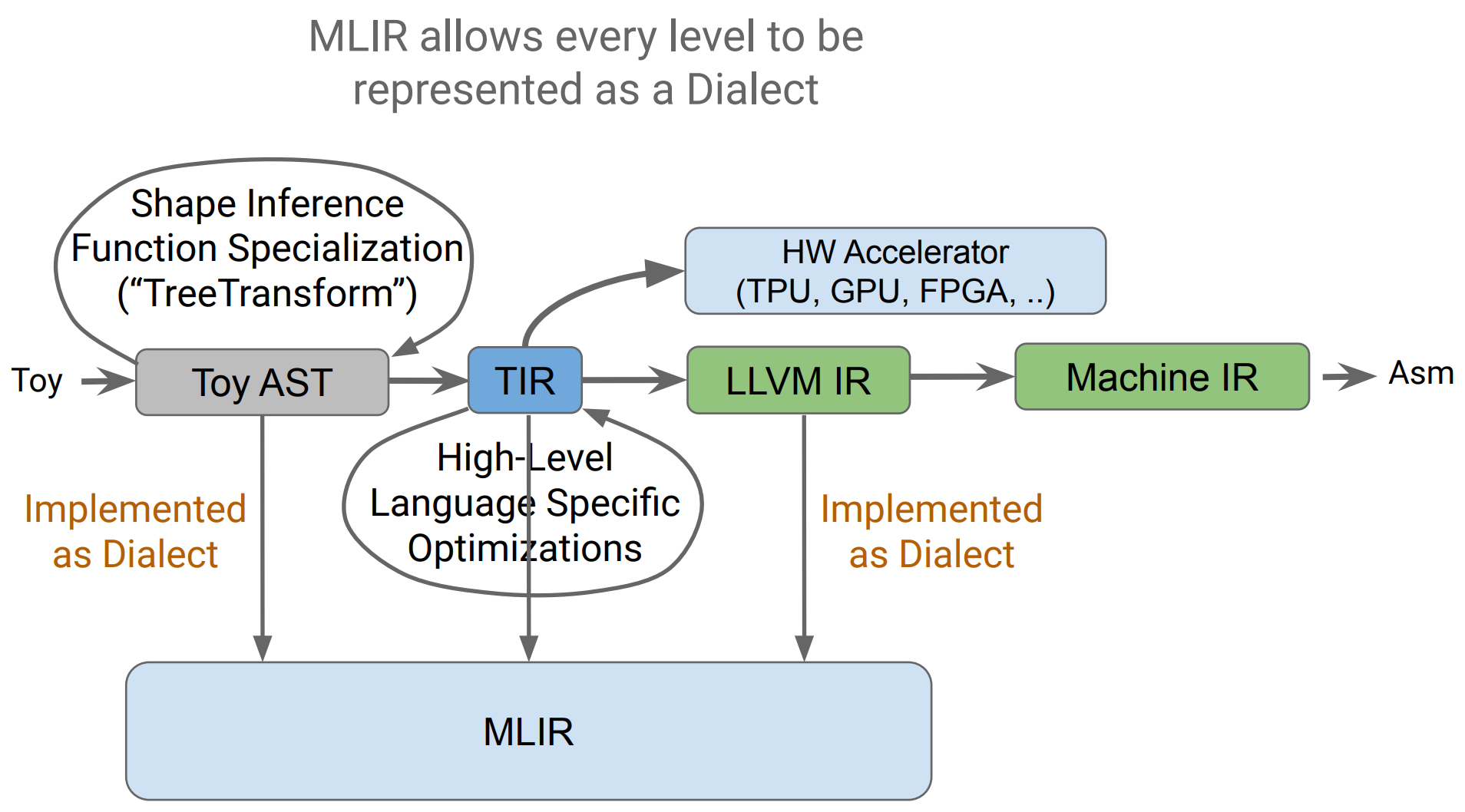
MLIR(Multi-Level Intermediate Representation) 是一种构建可复用的、可扩展的编译器架构的解决方案。目标是解决需要实现多套代码的碎片化(fragmentation) 问题,改善在不同硬件平台编译的问题,特别是减少构建特定领域编译器(domain specific compiler) 的开销,作为不同编译器之间的连接。
也就是说,MLIR 是设计成一种混杂(hybrid)、通用(common) 的 IR,可以支持不同的需要,还能支持特定的硬件层面的指令,更好的是可以统一在 MLIR 上进行问题处理和优化。但它不会去支持低层级(low-level) 代码生成相关的操作(如寄存器分配、指令调度等),因为 LLVM 这种低层级优化器更适合。
3.1、设计

MLIR 有以下需要满足的设计目标:
- Little builtin, everything customizable。 保留最少量的内置类型,让用户设计灵活可自定义的类型、操作符和属性,就可以提供更多的兼容性。需要能够表达不同的抽象(机器学习的图、AST、CFG、LLVM IR 等),但由于抽象的兼容性差,会存在很多没法复用的内部碎片。
- SSA and regions。 使用 SSA 简化了分析和优化的难度,加快了编译速度。现有的很多 IR 引入了嵌套域(nested regions) 的概念,使用扁平化的线性 CFG 来表示,这提升了抽象程度、加速编译和指令提取。不过要支持各种不同的编译,让分析和转换在嵌套域进行,有时就需要牺牲 canonicalization 特性(标准化,一种用来做优化的转换格式,之前的文章介绍过)。
- Progressive lowering。 需要支持从高层级抽象 lower 转换到下一级的表示。
- Maintain higher-level semantics。 需要能够保留高层级的语法信息用作分析和优化。
- IR validation。 需要检查编译器 bugs,验证可用性。
- Declarative rewrite patterns。 转换过程(transformation) 应该以声明式表达的重写规则来实现。
- Source location tracking and traceability。 可以追踪到操作指令的代码位置信息。对于安全敏感的应用做转换和优化时,需要考虑编译器是否会破坏掉一些代码保护。
由于要支持很多不同的编译器 IR,所以 MLIR 的实现需要有可扩展性,能容纳下不同的实现。

具体细节部分就不展开了(可能这部分是深入研究的重点,不过本文只做简介),在 MLIR 中,Module/Function/Block/Operation 等的语法结构单元都是 operation(简写为 Op),而不是使用指令(instructions),支持用户自定义扩展。

MLIR 中,使用 Dialects 来支持扩展性,它是 Ops、属性(attributes,即编译期的静态信息,如整型静态变量、字符串数据等)、类型(types) 在唯一的命名空间下的集合。

参考
- MLIR 系列文章
- Compilers and IRs: LLVM IR, SPIR-V, and MLIR
- 编译器与中间表示: LLVM IR, SPIR-V, 以及 MLIR
- 抽象化 (计算机科学)
- LLVM
- Multi-Level Intermediate Representation Overview
- 静态单赋值形式
- MLIR: Redefining the compiler infrastructure
- Wrong of 《MLIR: Redefining the compiler infrastructure》
- hacker news - MLIR
- Multi-Level Intermediate Representation Overview
- MLIR: A Compiler Infrastructure for the End of Moore’s Law
- LLVM Language Reference Manual
- 2019 EuroLLVM Developers’ Meeting: T. Shpeisman & C. Lattner “MLIR: Multi-Level Intermediate Repr..”
- 2019 EuroLLVM Developers’ Meeting: Mehdi & Vasilache & Zinenko “Building a Compiler with MLIR”
- 2020 LLVM in HPC Workshop: Keynote: MLIR: an Agile Infrastructure for Building a Compiler Ecosystem
- Increasing development velocity of giant AI models
- Part 2: Increasing development velocity of giant AI models
- [RFC] Splitting the Standard dialect
- Codegen Dialect Overview
- A Data-Centric Model for Performance Portability on Heterogeneous Architectures
文章作者 calssion
上次更新 2023-03-19