用 AI 检测代码覆盖率
文章目录
最近发现一个检测代码覆盖率的新玩法,可以在不执行代码的情况下,利用 AI 来预测代码的覆盖率。本文来简单了解一下。
1、code coverage
软件测试是比较重要的检测程序 bug 的手段,而代码覆盖率是其中用来衡量测试质量的重要指标。如果被漏掉的测试代码太多,对于测试质量而言是不达标的,所以需要代码覆盖率来进行判断。
当然,之前的文章也写过,代码覆盖率,还可以用来做程序启动时使用的函数收集(通过重排函数位置优化启动速度)、无用函数检测等。
一般代码覆盖率是通过提前插桩(instrumentation、一般是提前插入指令),然后运行来得到哪些代码被执行了。这个过程是比较繁琐的,因为需要以插桩的方式重新编译,然后运行得到报告。
2、LLMs(Large Language Models)
最近大语言模型 LLMs 在代码相关的任务上表现不错,尤其是在代码生成和测试用例生成方面,它们能够理解(特征提取) 代码语法和语义,但它们对代码执行的理解仍不清晰。而根据给定的测试用例及其输入来准确地确定执行了方法的哪一行,需要对底层代码执行有深刻的理解。
所以出现了 Code Coverage Prediction,用来评估 LLMs 在理解代码执行时的质量。此外,这个模型也能够用来计算代码执行覆盖的情况,减小了代码覆盖率的成本,以及一些无法覆盖到的代码情况。方便开发人员快速评估是否需要编写额外的测试来覆盖遗漏的分支或行,节约了时间和资源。
2.1、task

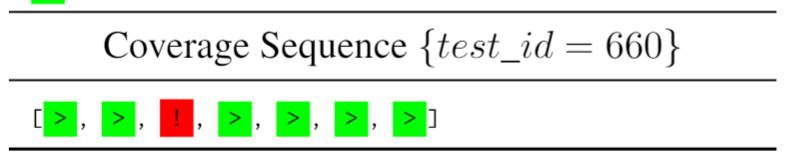
代码覆盖率一般以语句级别来进行计算,也有代码块或者函数级别的,上图为语句是否被执行的判断。'!' 代表没覆盖到,'-' 代表不可达,'>' 代表被执行到了,这些符号用来代表每条语句在该测试用例下的状态。

2.2、模型训练
为了完成预训练,论文作者在 CI/CD 流水线执行上部署了模型训练,采用执行时的日志输出(包含哪里被执行了的信息) 来作为覆盖率判断,让模型学会了如何把输入、测试用例和代码执行关联起来。
作者还创建了 CoverageEval 数据集,包含了有覆盖率注解的方法和测试用例。数据的格式化也如下面所示:
|
|
2.3、模型评估
模型的预测,首先需要把代码覆盖率问题转成 LLMs 的任务,设计的 prompt 如下:

执行的效果如下:
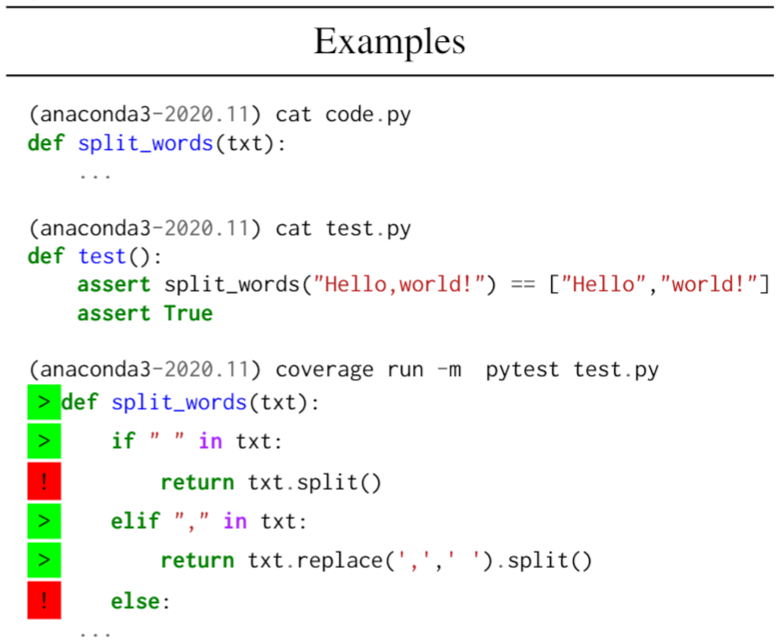
对于模型的预测的效果判断,有以下几个:
- Perfect Sequence Match。对于语句是否执行的完整序列(>、!、-) 匹配的百分比。
- Statement Correctness。语句执行预测正确的百分比。
- Branch Correctness。具有分支条件语句的执行预测正确的百分比。

在预测代码覆盖率方面,各个模型的准确率都不算高,表明 LLMs 在理解代码执行还有很长的路要走。不过通过不停地微调和数据学习,相信未来效果会越来越好。
3、扩展思考
类似的,对输入和测试用例进行模拟执行(即不进行编译执行,像运行在虚拟机一样,采用模拟语句判断来执行),也是一种减少插桩编译消耗的方式。
不过进行模拟或者翻译执行,都需要比较大的工程基础来支撑,而使用 LLMs,由模型来学习总结特征,来做判断,虽然存在准确性问题,但大大减少了工程量的负担,而且也可以快速迁移支持不同语言。
除了代码生成、测试用例生成、代码覆盖率等,LLMs 还有很多的可能,比如支持不同语言之间的直接翻译、还有类似 MLGO 对编译器优化的策略选择等。玩法会有很多,但如何提升准确性就显得更加重要了。
参考
文章作者 calssion
上次更新 2023-07-30