有状态编译器: 加速增量编译
文章目录
读到一篇关于增量编译加速的论文,对比基础的 LLVM/Clang 增量编译平均加速了 6.72%,本文笔记简单记录一下。
1、增量编译问题
当前的增量编译构建,主要依靠分析文件之间的依赖性的构建系统,来避免对未更改的文件进行不必要的重新编译。
但是对于确实发生了更改的文件,构建系统只是调用编译器重新编译文件,构建系统以有状态的方式运行,但编译器是无状态的。这里的增量编译是粗粒度的,重点关注整个源文件,而不是某个代码部分这种更细的粒度。
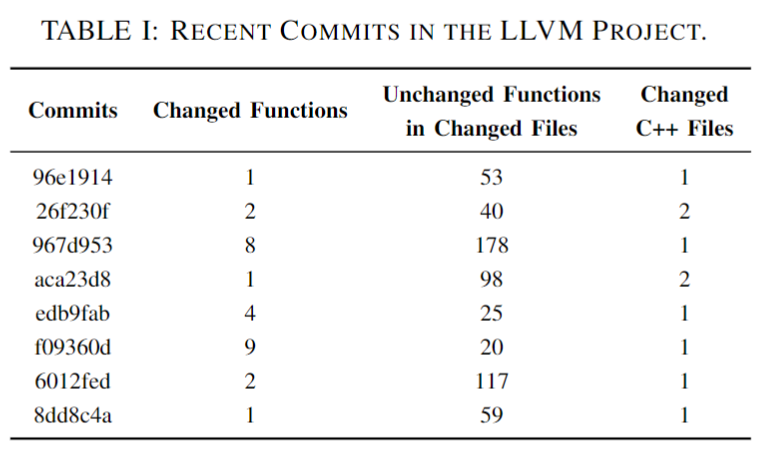
上图展示了 LLVM 当中的一些 commit 修改,很多时候只是修改了一两个文件中的几个函数,没被修改的函数占大多数,但都被重新编译了,这是编译资源的浪费。
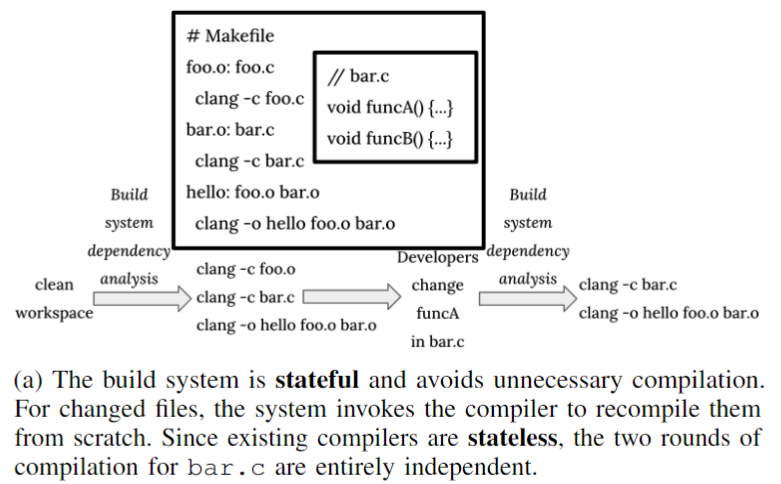
构建系统检测到文件变化,都是直接使用编译指令重新对源文件进行编译。
2、有状态编译器
论文提出有状态编译器的概念,它可以识别出被修改的函数,对于未被修改的函数,直接复用之前的一些结果。
现代编译器会执行几百个 pass,消耗大量的编译时间,但不是所有 pass 都会修改程序,那些不会修改程序的称之为 dormant,会修改的称之为 active。根据论文中描述,跳过那些 dormant 的 pass,就可以节省大概 25% 的时间。

论文在 LLVM/Clang 之上实现了有状态编译,记录 dormant 的 function pass 和 loop pass (忽略 module pass,因为 module 的增量编译在语义上会带来变化)。这两种 pass 是分开存储对应信息的。
一般的构建系统,在添加无用指令 a = a 时还是会触发重编;而有状态编译器因为是在 pass 上做文章,所以在经历过优化之后(如 dead code elimination),可以识别到实际上是等价的,不需要重新编译。
有状态编译有两种编译模式:
- profiling build。这个模式下会记录并保存 dormant 信息,只有第一次编译时需要开启这个模式。
- fine-grained incremental build。加载 dormant 信息,跳过那些 dormant pass 以加速编译。现在的实现中,增量编译不会更新 dormant 信息,所以后续的增量编译都可以继续复用。
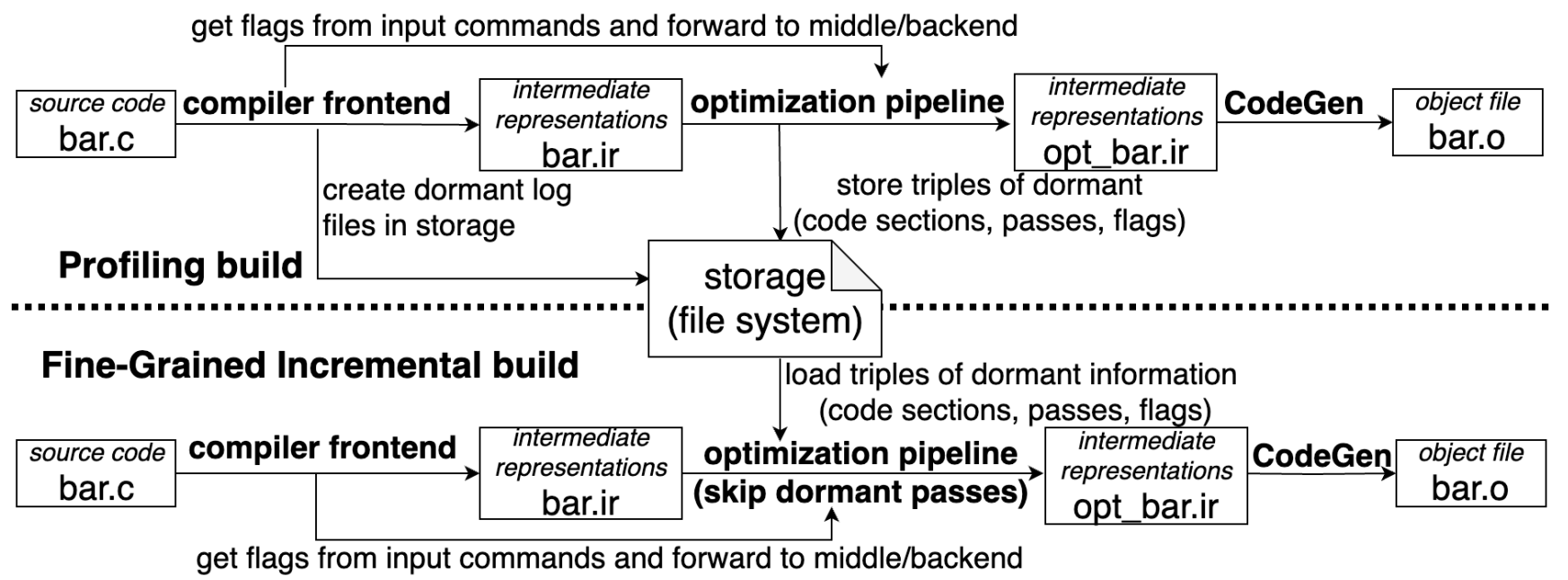
dormant 信息是 code section、pass、flag 的三元组,记录大致为 (LICM, FuncA, ’licm-control-flow-hoisting=false’),代表 FuncA 在控制流 hoisting 选项为 false 时不会被 LICM pass 所修改。code section 使用哈希算法记录,接收 IR 作为输入,输出标量(scalar values)。
这套有状态编译器还可以与 CCache 集成使用,在 CCache 的基础上还能有加速效果。
不过这套有状态编译器还存在一些问题:
- 还需要支持在增量编译时,更新 dormant 信息。因为一些 pass 可能在增量编译时才开始修改程序。
- 需要对 dormant 信息验证正确性,因为还有很多因素会影响 dormant 的状态。
3、最后
这个是 CGO 24 的分享,目前没搜到相关的代码仓库,所以就简单描述一下,算是了解一种增量编译加速的方法。
参考
文章作者 calssion
上次更新 2024-04-16