需求驱动编译简介
文章目录
在编译系统中,需求驱动编译(demand-driven compilation) 即按照需求只执行必要的计算,避免全部重新编译带来的繁重任务量和过长耗时。本文介绍几个编译系统中看到的设计方式。
1、LLVM Pass Manager
这里要描述的一个设计方式是分离,尽可能把独立模块分离开来,而不是耦合到一起。
在 LLVM 中,Pass 是一个基本的单元,用来在 IR(Intermediate Representation) 层面执行操作。众多 Pass 的执行是按照线性顺序的,称之为 Pass pipeline。
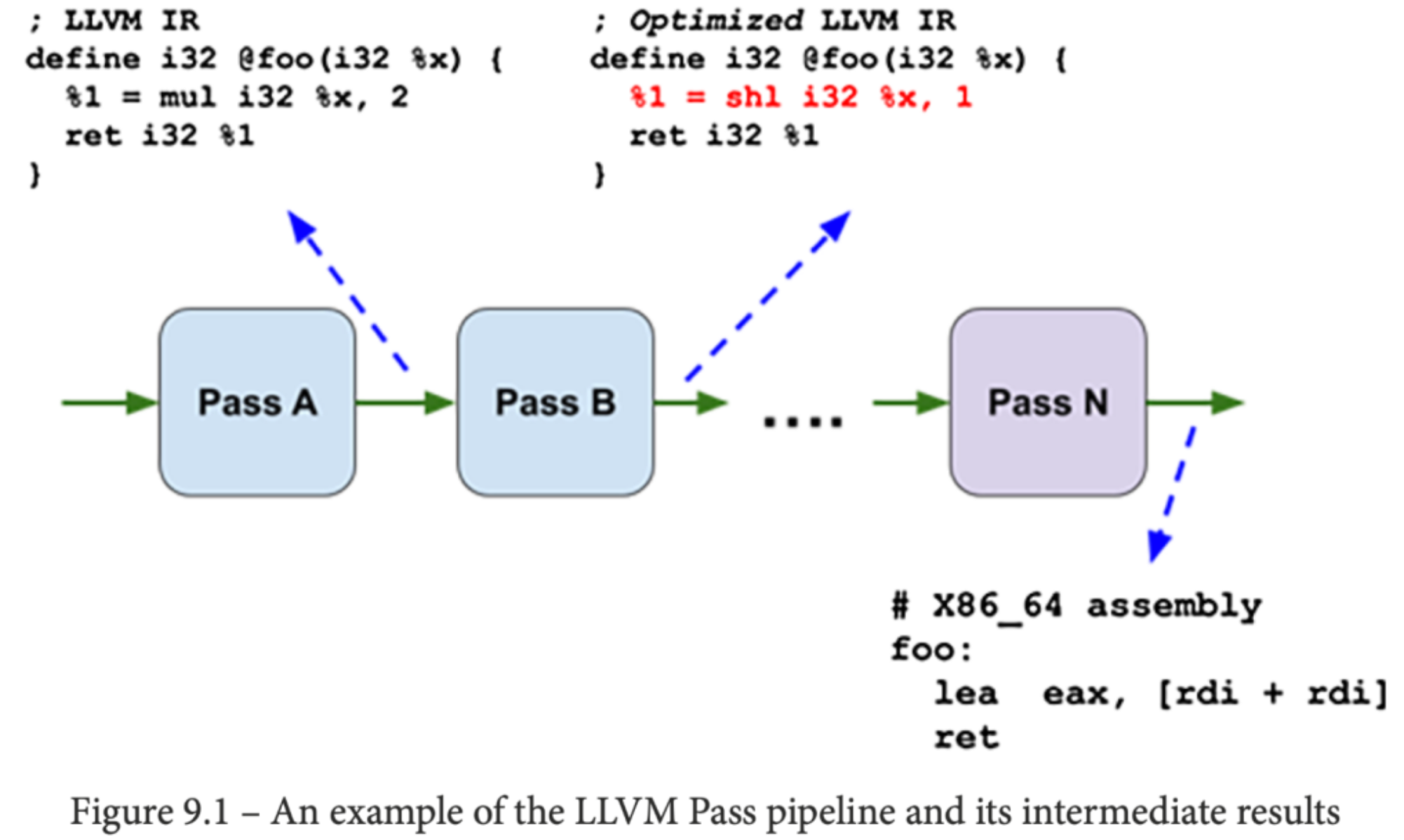
LLVM 中的 pass manager 用来调度 IR 上的 pass 和 analyses(分析) 的顺序,还会用来组织管理 analyses 的结果,在不同的 pass 进行共享。 为了做到这一点,就需要缓存结果和在缓存无效时重新执行了。
现在 LLVM 有两个独立的 pass manager(PM):legacy PM 和 new PM。
在 legacy PM 的设计下,每个 pass 会声明它所需要的和保存的 analyses,如果没有读取缓存成功,就需要重新执行这些 analyses 了。
- 但提前声明 pass 需要哪些 analyses 的操作,是不必要的负担,且在一些条件判断下,一个 pass 可能并不会用到它所声明的所有 analyses,如果触发重新计算是很大的资源浪费。
- 而且由于它把 analyses 也看作是 pass 来调度和运行,导致很难去访问任意函数的 analyses 的结果,只能获得函数在最近一次 analyses 运行的信息,经常导致缓存无效化或者需要重新计算结果。
new PM 把普通的 pass 和 analyses 分开,再弄了个 analysis manager 去负责管理 analyses 的计算、缓存和缓存无效化。这样就可以缓存任意函数在任意分析下的结果了。pass 也可以直接从 analysis manager 中获取所需 analyses 的结果了。
2、query system
这里要描述的一个设计方式是按需要划分依赖,像原子性一样组织任务。
传统编译器是基于 pass 的配置来执行固定的编译任务,一个 pass 执行完再接另一个的 pass 运行,这种方式称为 pass-based setup。
而 rust 编译器实现了一个查询系统(query system),用来支持增量编译,如果程序修改了并重编,可以尽可能减少任务量。
在 rustc 当中,所有的步骤都被组织成一系列的查询(query,可以理解为任务),它们之间可能会互相调用、嵌套调用。比如,有一条查询需要补全某个变量的类型,另一条查询需要为某个函数执行优化。每条查询的结果会缓存起来,并且会为其结果计算一个 128 位的哈希值(fingerprint),所以我们能够知道是哪些查询的结果,在最近一次编译中被改变,只需要重新执行这些查询即可。这种方式称之为需求驱动编译(demand-driven compilation)。
一条查询的定义大致如下,就像是提供一个函数给调用一样:
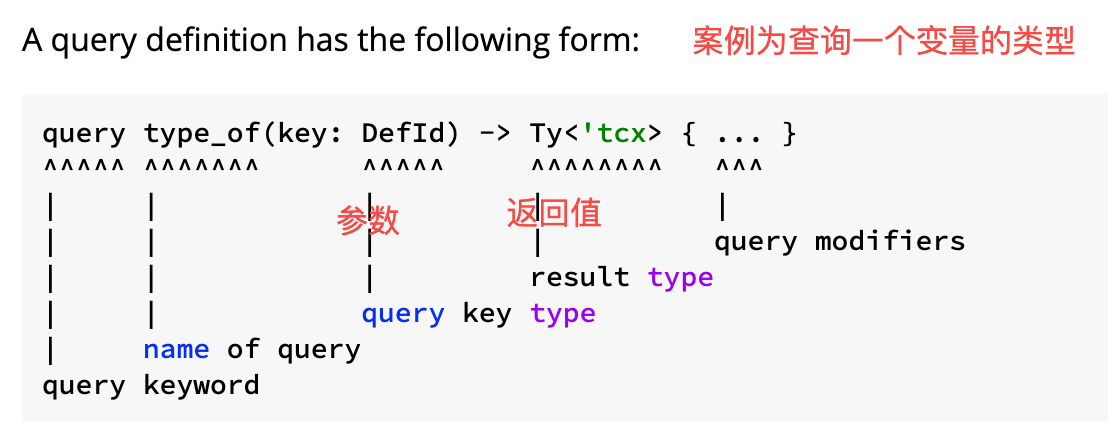
有几个限制来保证其完备性:
- 参数和返回值必须是不可变的值。
- 必须是纯函数,对于同样的参数输入,返回同样的结果输出。
- 函数只能读取参数和 query 的上下文。
|
|
由于每条查询就像是单纯的独立的函数一样,只取决于它们的参数(输入),所以可以很好地支持交叉编译缓存,不依赖于环境,做数据依赖分析图(dependency graph,有向无环图),重编只需要重新构建相关节点即可。
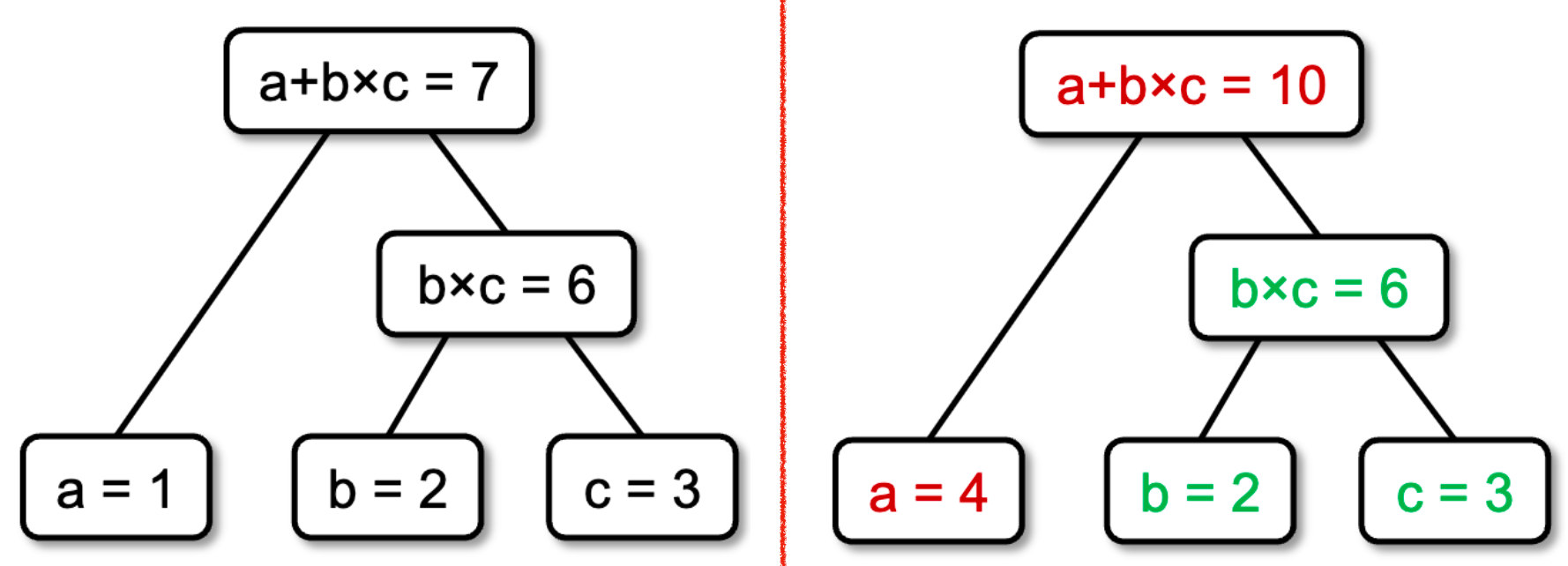
这里会使用依赖分析图和 red/green 算法来保证缓存的一致性和懒加载:
- 初始标记所有的节点为灰色。表明处于未知状态。
- 一旦新版本源码开始重编,可以对比节点是否被改变。如果改变了,标记为红色;否则标记为绿色。
- 当查询来了,查看相关节点是否都是绿色。如果是则说明保持不变可以复用;如果其中一个为红色,就需要重编了,重编后同样需要进行新一轮的红绿标记。
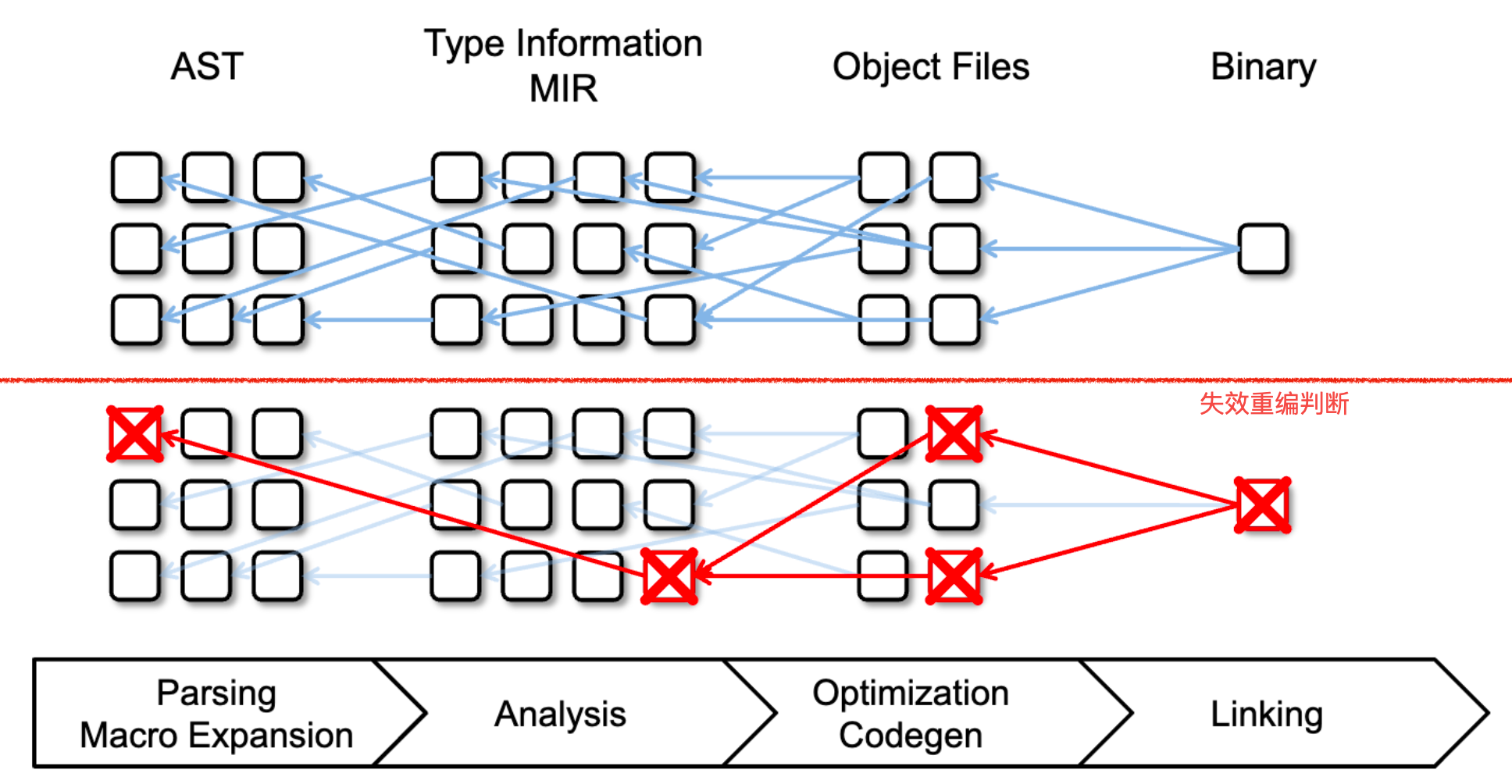
不过编译器需要处理两个问题:
- 假阳性(false positives),即所依赖的节点被判定需要重编,但实际其输入并没有改变,而仅仅是因为被依赖到了。这种情况只能尽可能使编译器检测节点更智能和准确些了。
- 要避免循环调用的情况出现,所以 rust 编译器还做了循环调用的检查,因为一旦出现循环调用,就很难恢复了。
对此,rust 编译器还提供了调试和测试依赖图的功能,可以把相关节点 dump 出来,或测试节点是否一致。
3、Request-Evaluator
类似的思路,在 Swift 编译器实现了一种叫 Request-Evaluator 的架构方式,可以追踪并可视化依赖、对编译结果分离缓存起来、移除像 AST(Abstract Syntax Tree) 中的可变状态带来的影响。
主要是为了解决以下一些问题:
- 类型检查(type checking) 依赖于可变的 AST 的状态,导致很难评估类型检查的结果。
- 编译器类型检查只检查给定的源文件,而无法指定更多。
- 现有的类型检查容易导致循环调用问题,比如 A 和 B 互相依赖。
- 多源文件目标(multi-file target) 编译时编译器操作过多,还容易循环操作。
Request-Evaluator 就是提供一种查询 AST 信息的中间层,把每一种状态都组织缓存起来,自动追踪请求的依赖,识别出循环依赖。可以很好地增量编译、调试和测试。
核心是请求(request),类似于查询,比如查询获取类 Foo 的父类,会组织成一种 request 的类型,然后有对应的函数去计算和缓存它的结果。
参考
- The New Pass Manager
- 《LLVM Techniques, Tips, and Best Practices》
- Ast build is very long
- Rust Compiler Development Guide
- rustc-on-demand-and-incremental.md
- Incremental Compilation - Rust Blog
- Request-Evaluator
文章作者 calssion
上次更新 2023-05-14