git 原理 & 基础学习
文章目录
git 作为仓库管理工具,是每个程序员必须要掌握的技能,而了解其原理对于 git 的学习会有更大的帮助。
本文大纲如下:
1、简述
1.1、git
2、git objects
2.1、读取
2.2、blob
2.3、commit
2.4、tree
2.5、ref
2.6、tag
2.7、branch
2.7.1、远程分支
2.8、git 存储示例
3、packfiles
4、文件移动
5、格式化获取日志
6、fetch & pull
7、三方合并
7.1、合并冲突
8、merge & rebase
8.1、衍合的风险
9、关于 SHA-1 的简短说明
10、文件标注
11、子模块
11.1、克隆一个带子模块的项目
11.2、子模块的问题
12、hook
1、简述
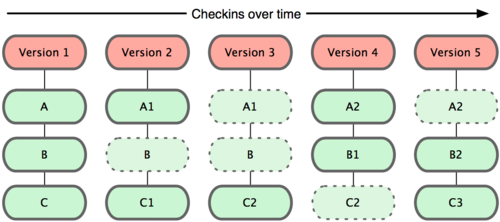
Git 保存的不是文件差异或者变化量,而只是一系列文件快照。
Git 并不保存这些前后变化的差异数据。实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。每次提交更新时,它会纵览一遍所有文件的指纹信息并对文件作一快照,然后保存一个指向这次快照的索引。为提高性能,若文件没有变化,Git 不会再次保存,而只对上次保存的快照作一链接。
在保存到 Git 之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。换句话说,不可能在你修改了文件或目录之后,Git 一无所知。这项特性作为 Git 的设计哲学,建在整体架构的最底层。所以如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git 都能立即察觉。
Git 使用 SHA-1 算法计算数据的校验和,通过对文件的内容或目录的结构计算出一个 SHA-1 哈希值,作为指纹字符串。该字串由 40 个十六进制字符(0-9 及 a-f)组成。
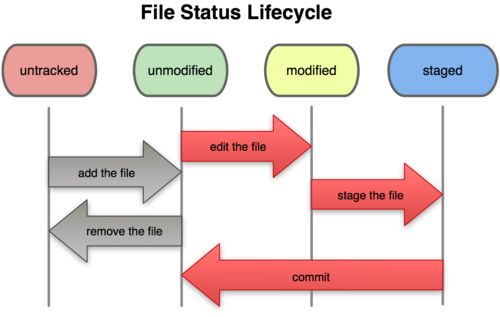
请记住,工作目录下面的所有文件都不外乎这两种状态:已跟踪或未跟踪。已跟踪的文件是指本来就被纳入版本控制管理的文件,在上次快照中有它们的记录,工作一段时间后,它们的状态可能是未更新,已修改或者已放入暂存区。
1.1、.git
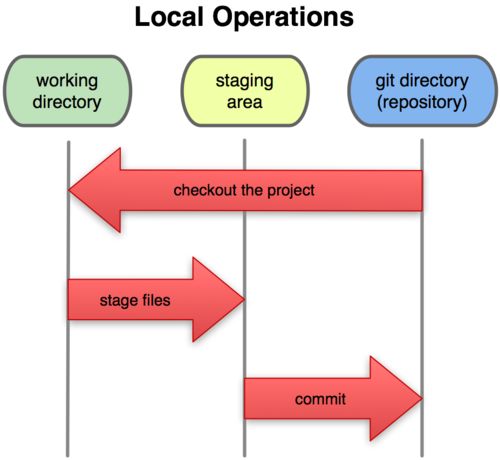
当你在一个新目录或已有目录内执行 git init 时,Git 会创建一个 .git 目录,几乎所有 Git 存储和操作的内容都位于该目录下。如果你要备份或复制一个库,基本上将这一目录拷贝至其他地方就可以了。
|
|
新版本的 Git 不再使用 branches 目录,description 文件仅供 GitWeb 程序使用,所以不用关心这些内容。config 文件包含了项目特有的配置选项,info 目录保存了一份不希望在 .gitignore 文件中管理的忽略模式 (ignored patterns) 的全局可执行文件。hooks 目录保存了客户端或服务端钩子脚本。
另外还有四个重要的文件或目录:HEAD 及 index 文件,objects 及 refs 目录。这些是 Git 的核心部分。objects 目录存储所有数据内容,refs 目录存储指向数据 (分支) 的提交对象的指针,HEAD 文件指向当前分支,index 文件保存了暂存区域信息。
2、git objects
Git uses objects to store quite a lot of things:
first and foremost, the actual files it keeps in version control — source code, for example. Commit are objects, too, as well as tags.
With a few notable exceptions (which we’ll see later!), almost everything, in Git, is stored as an object.
The path is computed by calculating the SHA-1 hash of its contents.
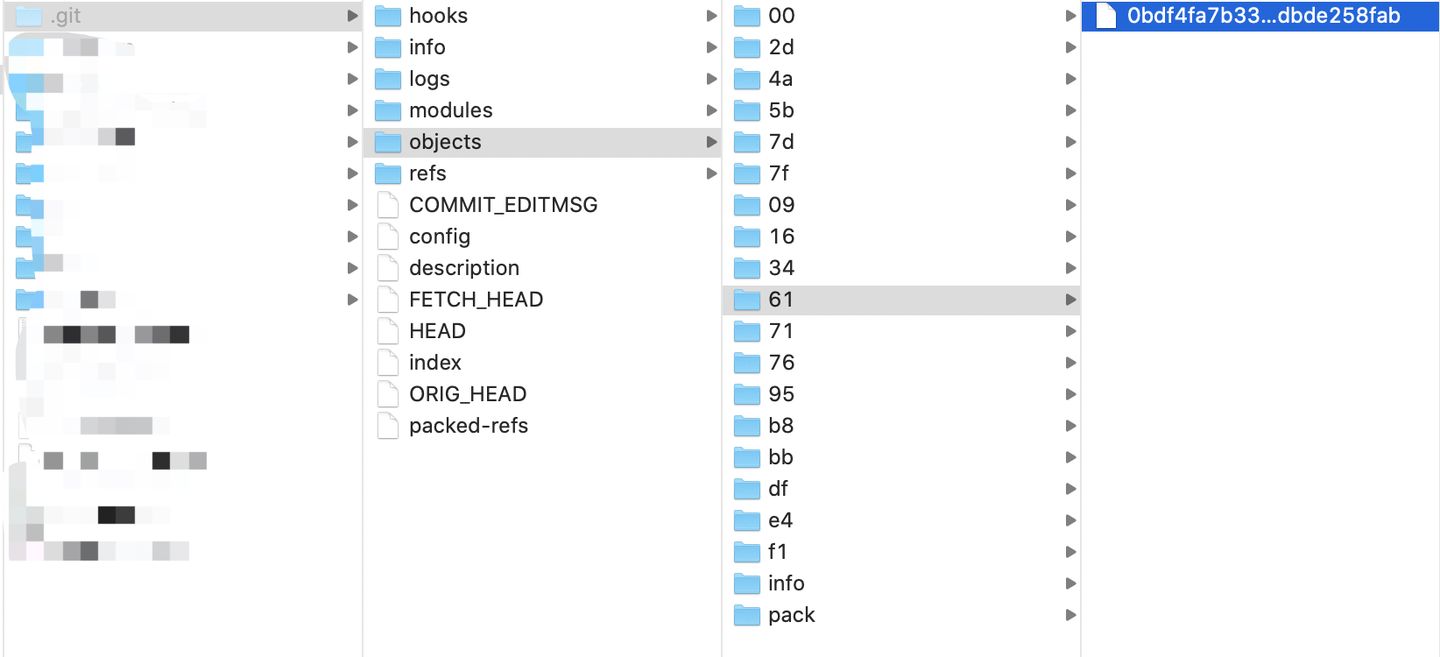

对比上面两幅图,可以看到 git commit 的哈希值,前2位被用作 objects 目录下的文件夹名字,后面的被用作了文件的名字。
2.1、读取
An object starts with a header that specifies its type:
blob, commit, tag or tree.
This header is followed by an ASCII space (0x20), then the size of the object in bytes as an ASCII number, then null (0x00) (the null byte), then the contents of the object.
The first 48 bytes of a commit object in Wyag’s repo look like this:
|
|
在这个例子中,commit 是类型, 1086 是大小。
由于 objects 文件是采用 zlib 进行压缩的,所以也需要用 zlib 来进行读取。
|
|
2.2、blob
Of the four Git object types, blobs are the simplest, because they have no actual format.
Blobs are user content: every file you put in git is stored as a blob.
That make them easy to manipulate, because they have no actual syntax or constraints beyond the basic object storage mechanism: they’re just unspecified data.
2.3、commit
在 Git 中提交时,会保存一个提交(commit)对象,该对象包含一个指向暂存内容快照的指针,包含本次提交的作者等相关附属信息,包含零个或多个指向该提交对象的父对象指针:首次提交是没有直接祖先的,普通提交有一个祖先,由两个或多个分支合并产生的提交则有多个祖先。
|
|
Let’s have a look at those fields:
-
treeis a reference to a tree object, a type of object. A tree maps blobs IDs to filesystem locations, and describes a state of the work tree. Put simply, it is the actual content of the commit: files, and where they go. -
parentis a reference to the parent of this commit. It may be repeated: merge commits, for example, have multiple parents. It may also be absent: the very first commit in a repository obviously doesn’t have a parent. -
authorandcommitterare separate, because the author of a commit is not necessarily the person who can commit it (This may not be obvious for GitHub users, but a lot of projects do Git through e-mail) -
gpgsigis the PGP signature of this object.
git log 就是利用 commit 的 parent 这个信息来进行显示的。
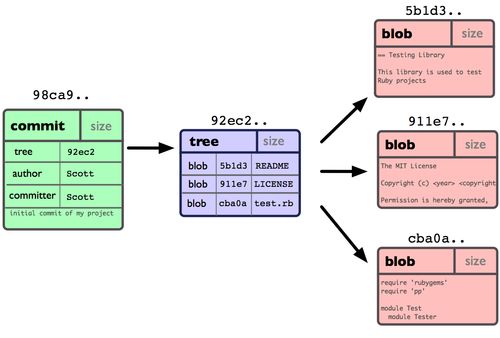
So what makes a commit? To sum it up:
-
A tree object, which we’ll discuss now, that is, the contents of a worktree, files and directories;
-
Zero, one or more parents;
-
An author identity (name and email);
-
A committer identity (name and email);
-
An optional PGP signature
-
A message;
All this hashed together in a SHA-1 identifier.
2.4、tree
Informally, a tree describes the content of the work tree, that it, it associates blobs to paths.
It’s an array of three-element tuples made of a file mode, a path (relative to the worktree) and a SHA-1.
A typical tree contents may look like this:

Mode is just the file’s mode, path is its location.
The SHA-1 refers to either a blob or another tree object. If a blob, the path is a file, if a tree, it’s directory.
To instantiate this tree in the filesystem, we would begin by loading the object associated to the first path (.gitignore) and check its type. Since it’s a blob, we’ll just create a file called .gitignore with this blob’s contents; and same for LICENSE and README.md. But the object associated with src is not a blob, but another tree: we’ll create the directory src and repeat the same operation in that directory with the new tree.
2.5、ref
Git references, or refs, are probably the most simple type of things git holds. They live in subdirectories of .git/refs, and are text files containing a hexadecimal representation of an object’s hash, encoded in ASCII.
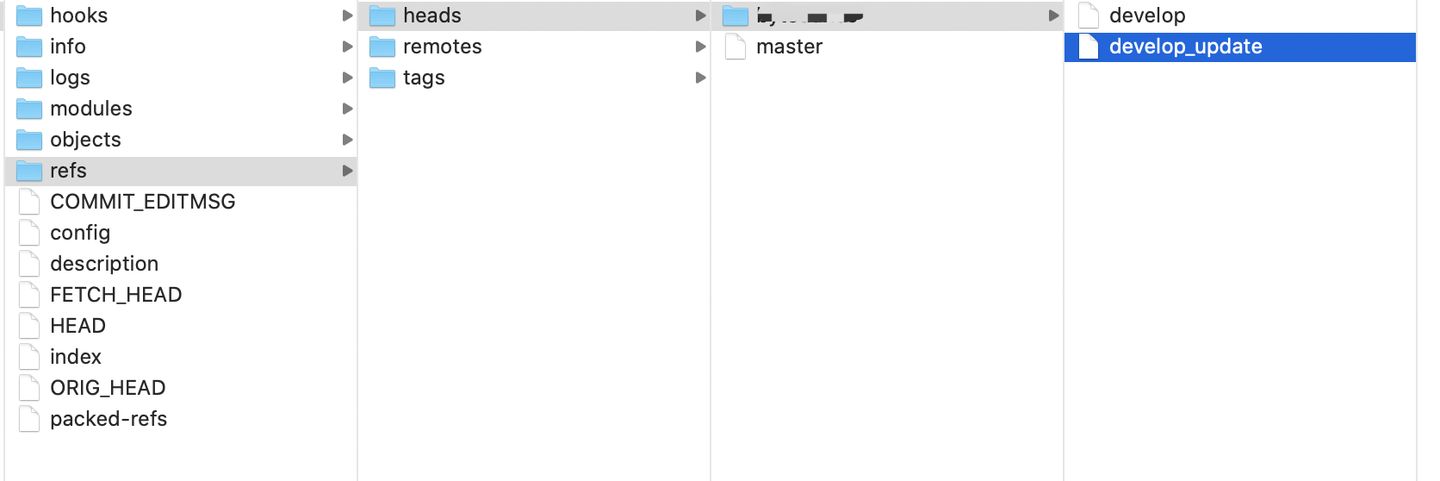
如果想要创建一个新的引用帮助你记住最后一次提交,技术上你可以这样做:
|
|
2.6、tag
在上图中,可以看到一个名为 tags 的文件夹。
The most simple use of refs is tags. A tag is just a user-defined name for an object, often a commit. A very common use of tags is identifying software releases。
You’ve probably guessed already that tags are actually refs.
They live in the .git/refs/tags/ hierarchy.
The only point worth noting is that they come in two flavors: lightweight tags and tags objects.
“Lightweight” tags are just regular refs to a commit, a tree or a blob.
Tag objects are regular refs pointing to an object of type tag. Unlike lightweight tags, tag objects have an author, a date, an optional PGP signature and an optional annotation. Their format is the same as a commit object.
2.7、branch
Git 中的分支,其实本质上仅仅是个指向 commit 对象的可变指针。
Now, what’s a branch? The answer is actually surprisingly simple, but it may also end up being simply surprising: a branch is a reference to a commit. You could even say that a branch is a kind of a name for a commit. In this regard, a branch is exactly the same thing as a tag. Tags are refs that live in .git/refs/tags, branches are refs that live in .git/refs/heads.
There are, of course, differences between a branch and a tag:
-
Branches are references to a commit, tags can refer to any object;
-
But most importantly, the branch ref is updated at each commit. This means that whenever you commit, Git actually does this:
-
a new commit object is created, with the current branch’s ID as its parent;
-
the commit object is hashed and stored;
-
the branch ref is updated to refer to the new commit’s hash.
-
That’s all.
But what about the current branch? It’s actually even easier. It’s a ref file outside of the refs hierarchy, in .git/HEAD, which is an indirect ref (that is, it is of the form ref: path/to/other/ref, and not a simple hash).
由于 Git 中的分支实际上仅是一个包含所指对象校验和(40 个字符长度 SHA-1 字串)的文件,所以创建和销毁一个分支就变得非常廉价。说白了,新建一个分支就是向一个文件写入 41 个字节(外加一个换行符)那么简单,当然也就很快了。
2.7.1、远程分支
假设你们团队有个地址为 git.ourcompany.com 的 Git 服务器。如果你从这里克隆,Git 会自动为你将此远程仓库命名为 origin,并下载其中所有的数据,建立一个指向它的 master 分支的指针,在本地命名为 origin/master,但你无法在本地更改其数据。接着,Git 建立一个属于你自己的本地 master 分支,始于 origin 上 master 分支相同的位置,你可以就此开始工作。
2.8、git 存储示例
|
|
当存储数据内容时,同时会有一个文件头被存储起来。我们花些时间来看看 Git 是如何存储对象的。你将看来如何通过 Ruby 脚本语言存储一个 blob 对象 (这里以字符串 “what is up, doc?” 为例) 。使用 irb 命令进入 Ruby 交互式模式:
|
|
Git 以对象类型为起始内容构造一个文件头,本例中是一个 blob。然后添加一个空格,接着是数据内容的长度,最后是一个空字节 (null byte):
|
|
Git 将文件头与原始数据内容拼接起来,并计算拼接后的新内容的 SHA-1 校验和。可以在 Ruby 中使用 require 语句导入 SHA1 digest 库,然后调用 Digest::SHA1.hexdigest() 方法计算字符串的 SHA-1 值:
|
|
Git 用 zlib 对数据内容进行压缩,在 Ruby 中可以用 zlib 库来实现。首先需要导入该库,然后用 Zlib::Deflate.deflate() 对数据进行压缩:
|
|
最后将用 zlib 压缩后的内容写入磁盘。需要指定保存对象的路径 (SHA-1 值的头两个字符作为子目录名称,剩余 38 个字符作为文件名保存至该子目录中)。在 Ruby 中,如果子目录不存在可以用 FileUtils.mkdir_p() 函数创建它。接着用 File.open 方法打开文件,并用 write() 方法将之前压缩的内容写入该文件:
|
|
这就行了 ── 你已经创建了一个正确的 blob 对象。所有的 Git 对象都以这种方式存储,惟一的区别是类型不同 ── 除了字符串 blob,文件头起始内容还可以是 commit 或 tree 。不过虽然 blob 几乎可以是任意内容,commit 和 tree 的数据却是有固定格式的。
3、packfiles
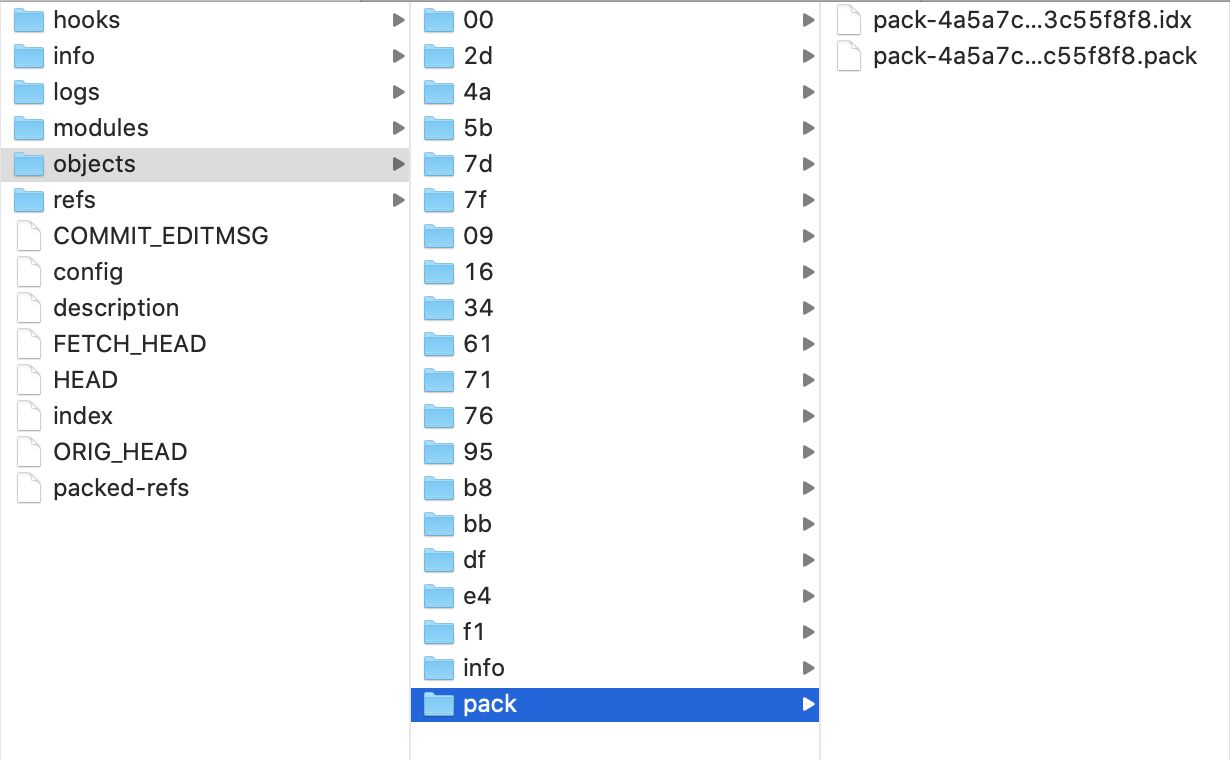
前面说的那些 objects 都是 loose objects。
Git 往磁盘保存对象时默认使用的格式叫松散对象 (loose object) 格式。
Git 时不时地将这些对象打包至一个叫 packfile 的二进制文件以节省空间并提高效率。
当仓库中有太多的松散对象,或是手工调用 git gc 命令,或推送至远程服务器时,Git 都会这样做。
4、文件移动
其实,运行 git mv 就相当于运行了下面三条命令:
|
|
如此分开操作,Git 也会意识到这是一次改名,所以不管何种方式都一样。当然,直接用 git mv 轻便得多,不过有时候用其他工具批处理改名的话,要记得在提交前删除老的文件名,再添加新的文件名。
5、格式化获取日志
下表列出了常用的格式占位符写法及其代表的意义。
|
|
用 oneline 或 format 时结合 --graph 选项,可以看到开头多出一些 ASCII 字符串表示的简单图形,形象地展示了每个提交所在的分支及其分化衍合情况。
|
|
6、fetch & pull
fetch 命令只是将远端的数据拉到本地仓库,并不自动合并到当前工作分支,只有当你确实准备好了,才能手工合并。
可以使用 git pull 命令自动抓取数据下来,然后将远端分支自动合并到本地仓库中当前分支。在日常工作中我们经常这么用,既快且好。
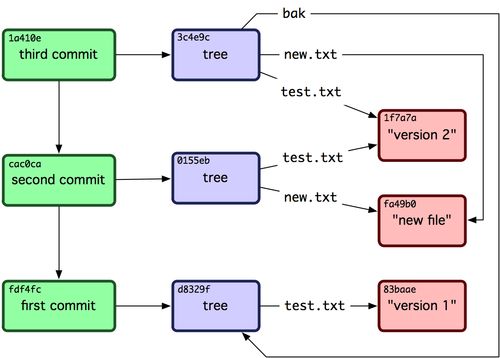
7、三方合并
由于当前 master 分支所指向的提交对象(C4)并不是 iss53 分支的直接祖先,Git 不得不进行一些额外处理。就此例而言,Git 会用两个分支的末端(C4 和 C5)以及它们的共同祖先(C2)进行一次简单的三方合并计算。图中用红框标出了 Git 用于合并的三个提交对象:
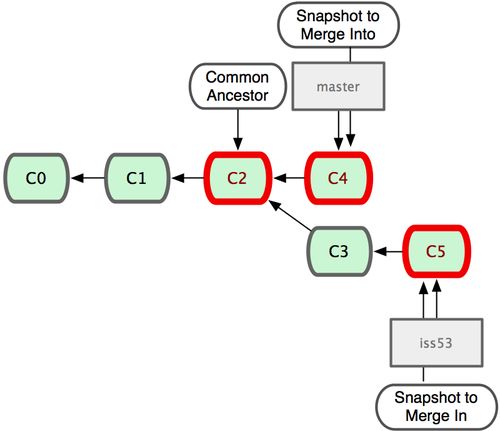
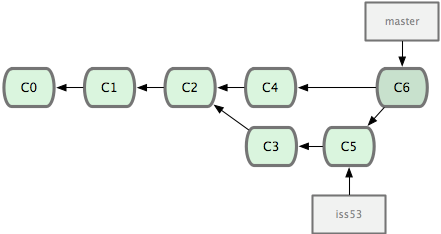
这次,Git 没有简单地把分支指针右移,而是对三方合并后的结果重新做一个新的快照,并自动创建一个指向它的提交对象(C6)(见下图)。这个提交对象比较特殊,它有两个祖先(C4 和 C5)。
值得一提的是 Git 可以自己裁决哪个共同祖先才是最佳合并基础;这和 CVS 或 Subversion(1.5 以后的版本)不同,它们需要开发者手工指定合并基础。所以此特性让 Git 的合并操作比其他系统都要简单不少。
7.1、合并冲突
有时候合并操作并不会如此顺利。如果在不同的分支中都修改了同一个文件的同一部分,Git 就无法干净地把两者合到一起(译注:逻辑上说,这种问题只能由人来裁决。)。如果你在解决问题 #53 的过程中修改了 hotfix 中修改的部分,将得到类似下面的结果:
|
|
Git 作了合并,但没有提交,它会停下来等你解决冲突。要看看哪些文件在合并时发生冲突,可以用 git status 查阅.
任何包含未解决冲突的文件都会以未合并(unmerged)的状态列出。Git 会在有冲突的文件里加入标准的冲突解决标记,可以通过它们来手工定位并解决这些冲突。
如果你想用一个有图形界面的工具来解决这些问题,不妨运行 git mergetool,它会调用一个可视化的合并工具并引导你解决所有冲突.
8、merge & rebase
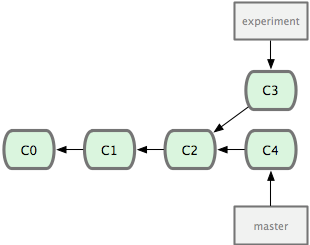
最容易的整合分支的方法是 merge 命令,它会把两个分支最新的快照(C3 和 C4)以及二者最新的共同祖先(C2)进行三方合并,合并的结果是产生一个新的提交对象(C5)。如下图所示:
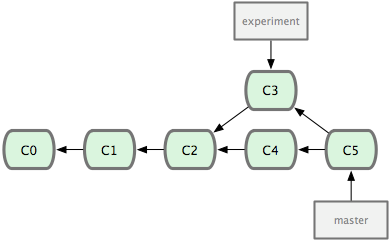
还有另外一个选择:你可以把在 C3 里产生的变化补丁在 C4 的基础上重新打一遍。在 Git 里,这种操作叫做衍合(rebase)。有了 rebase 命令,就可以把在一个分支里提交的改变移到另一个分支里重放一遍。
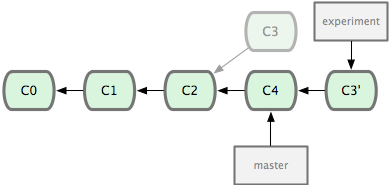
虽然最后整合得到的结果没有任何区别,但衍合能产生一个更为整洁的提交历史。如果视察一个衍合过的分支的历史记录,看起来会更清楚:仿佛所有修改都是在一根线上先后进行的,尽管实际上它们原本是同时并行发生的。
一般我们使用衍合的目的,是想要得到一个能在远程分支上干净应用的补丁 — 比如某些项目你不是维护者,但想帮点忙的话,最好用衍合:先在自己的一个分支里进行开发,当准备向主项目提交补丁的时候,根据最新的 origin/master 进行一次衍合操作然后再提交,这样维护者就不需要做任何整合工作(译注:实际上是把解决分支补丁同最新主干代码之间冲突的责任,化转为由提交补丁的人来解决。),只需根据你提供的仓库地址作一次快进合并,或者直接采纳你提交的补丁。
请注意,合并结果中最后一次提交所指向的快照,无论是通过衍合,还是三方合并,都会得到相同的快照内容,只不过提交历史不同罢了。衍合是按照每行的修改次序重演一遍修改,而合并是把最终结果合在一起。
8.1、衍合的风险
呃,奇妙的衍合也并非完美无缺,要用它得遵守一条准则:
一旦分支中的提交对象发布到公共仓库,就千万不要对该分支进行衍合操作。
如果你遵循这条金科玉律,就不会出差错。否则,人民群众会仇恨你,你的朋友和家人也会嘲笑你,唾弃你。
在进行衍合的时候,实际上抛弃了一些现存的提交对象而创造了一些类似但不同的新的提交对象。如果你把原来分支中的提交对象发布出去,并且其他人更新下载后在其基础上开展工作,而稍后你又用 git rebase 抛弃这些提交对象,把新的重演后的提交对象发布出去的话,你的合作者就不得不重新合并他们的工作,这样当你再次从他们那里获取内容时,提交历史就会变得一团糟。
9、关于 SHA-1 的简短说明
许多人可能会担心一个问题:在随机的偶然情况下,在他们的仓库里会出现两个具有相同 SHA-1 值的对象。那会怎么样呢?
如果你真的向仓库里提交了一个跟之前的某个对象具有相同 SHA-1 值的对象,Git 将会发现之前的那个对象已经存在在 Git 数据库中,并认为它已经被写入了。如果什么时候你想再次检出那个对象时,你会总是得到先前的那个对象的数据。
不过,你应该了解到,这种情况发生的概率是多么微小。SHA-1 摘要长度是 20 字节,也就是 160 位。为了保证有 50% 的概率出现一次冲突,需要 2^80 个随机哈希的对象(计算冲突机率的公式是 p = (n(n-1)/2) * (1/2^160))。2^80 是 1.2 x 10^24,也就是一亿亿亿,那是地球上沙粒总数的 1200 倍。
现在举例说一下怎样才能产生一次 SHA-1 冲突。如果地球上 65 亿的人类都在编程,每人每秒都在产生等价于整个 Linux 内核历史(一百万个 Git 对象)的代码,并将之提交到一个巨大的 Git 仓库里面,那将花费 5 年的时间才会产生足够的对象,使其拥有 50% 的概率产生一次 SHA-1 对象冲突。这要比你编程团队的成员同一个晚上在互不相干的意外中被狼袭击并杀死的机率还要小。
10、文件标注
如果你在追踪代码中的缺陷想知道这是什么时候为什么被引进来的,文件标注会是你的最佳工具。它会显示文件中对每一行进行修改的最近一次提交。因此,如果你发现自己代码中的一个方法存在缺陷,你可以用git blame来标注文件,查看那个方法的每一行分别是由谁在哪一天修改的。下面这个例子使用了-L选项来限制输出范围在第12至22行:
|
|
11、子模块
子模块允许你将一个 Git 仓库当作另外一个Git仓库的子目录。这允许你克隆另外一个仓库到你的项目中并且保持你的提交相对独立。
假设你想把 Rack 库(一个 Ruby 的 web 服务器网关接口)加入到你的项目中,可能既要保持你自己的变更,又要延续上游的变更。首先你要把外部的仓库克隆到你的子目录中。你通过git submodule add将外部项目加为子模块:
|
|
首先你注意到有一个.gitmodules文件。这是一个配置文件,保存了项目 URL 和你拉取到的本地子目录
|
|
如果你有多个子模块,这个文件里会有多个条目。很重要的一点是这个文件跟其他文件一样也是处于版本控制之下的,就像你的.gitignore文件一样。它跟项目里的其他文件一样可以被推送和拉取。这是其他克隆此项目的人获知子模块项目来源的途径。git status的输出里所列的另一项目是 rack 。如果你运行在那上面运行git diff,会发现一些有趣的东西:
|
|
你可以将rack目录当作一个独立的项目,保持一个指向子目录的最新提交的指针然后反复地更新上层项目。所有的Git命令都在两个子目录里独立工作:
|
|
11.1、克隆一个带子模块的项目
你必须运行两个命令:git submodule init来初始化你的本地配置文件,git submodule update来从那个项目拉取所有数据并检出你上层项目里所列的合适的提交。
现在你的rack子目录就处于你先前提交的确切状态了。如果另外一个开发者变更了 rack 的代码并提交,你拉取那个引用然后归并之,将得到稍有点怪异的东西:
|
|
你归并来的仅仅上是一个指向你的子模块的指针;但是它并不更新你子模块目录里的代码,所以看起来你的工作目录处于一个临时状态:
|
|
事情就是这样,因为你所拥有的指向子模块的指针和子模块目录的真实状态并不匹配。为了修复这一点,你必须再次运行git submodule update
每次你从主项目中拉取一个子模块的变更都必须这样做。看起来很怪但是管用。
一个常见问题是当开发者对子模块做了一个本地的变更但是并没有推送到公共服务器。然后他们提交了一个指向那个非公开状态的指针然后推送上层项目。当其他开发者试图运行git submodule update,那个子模块系统会找不到所引用的提交,因为它只存在于第一个开发者的系统中。如果发生那种情况,你会看到类似这样的错误:
|
|
你不得不去查看谁最后变更了子模块。
11.2、子模块的问题
使用子模块并非没有任何缺点。首先,你在子模块目录中工作时必须相对小心。当你运行git submodule update,它会检出项目的指定版本,但是不在分支内。这叫做获得一个分离的头——这意味着 HEAD 文件直接指向一次提交,而不是一个符号引用。问题在于你通常并不想在一个分离的头的环境下工作,因为太容易丢失变更了。如果你先执行了一次submodule update,然后在那个子模块目录里不创建分支就进行提交,然后再次从上层项目里运行git submodule update同时不进行提交,Git会毫无提示地覆盖你的变更。技术上讲你不会丢失工作,但是你将失去指向它的分支,因此会很难取到。
为了避免这个问题,当你在子模块目录里工作时应使用git checkout -b work创建一个分支。当你再次在子模块里更新的时候,它仍然会覆盖你的工作,但是至少你拥有一个可以回溯的指针。
12、hook
和其他版本控制系统一样,当某些重要事件发生时,Git 以调用自定义脚本。有两组挂钩:客户端和服务器端。客户端挂钩用于客户端的操作,如提交和合并。服务器端挂钩用于 Git 服务器端的操作,如接收被推送的提交。你可以随意地使用这些挂钩,下面会讲解其中一些。
挂钩都被存储在 Git 目录下的hooks子目录中,即大部分项目中的.git/hooks。 Git 默认会放置一些脚本样本在这个目录中,除了可以作为挂钩使用,这些样本本身是可以独立使用的。所有的样本都是shell脚本,其中一些还包含了Perl的脚本,不过,任何正确命名的可执行脚本都可以正常使用 — 可以用Ruby或Python,或其他。在Git 1.6版本之后,这些样本名都是以.sample结尾,因此,你必须重新命名。在Git 1.6版本之前,这些样本名都是正确的,但这些样本不是可执行文件。
参考资料
Write yourself a Git!:https://wyag.thb.lt/
Pro Git(中文版):https://git.oschina.net/progit/index.html
文章作者 calssion
上次更新 2021-05-03