当 LLVM 遇上 AI: 给代码优化找个"超级大脑"
文章目录
看到论坛里 LLVM 和 ML 的研讨,感觉非常有趣,本文简单概括整理一下相关内容。MLGO 和一些 LLM 相关的优化之前写过了,这里就不再重复。 由于数量比较多,所以写得会很简单,感兴趣可以点链接细看。
1、LLVM Pass Phase-Ordering
- 目标:通过调整 pass 的顺序,来优化程序性能。
- 背景:一般 llvm pass 的顺序是由开发者手写的,它对程序性能影响较大,是可优化项。
- 方式:使用强化学习来设置 pass 的顺序(不需要依赖运行时信息)。
- 训练集:LLVM test suite,按 4:1 划分为训练集和验证集。直接从 LLVM IR 的抽象特征中学习,使用 NCC embeddings 编码。
- 操作:从 pass 及其参数列表中选择一个来应用。操作历史会采用 one-hot 编码。
- 奖励:使用了新的顺序后,程序执行时间缩短。
- 结果:比 -O3 级别还优化了 32% 左右的性能。
- 缺点:泛化能力有限(基于 llvm test-suite 训练集)、训练成本高(需要编译和运行去对比,耗时夸张)、搜索空间大(pass 数量多,排列组合也多)、难以集成到编译流程里(会增加编译耗时)。
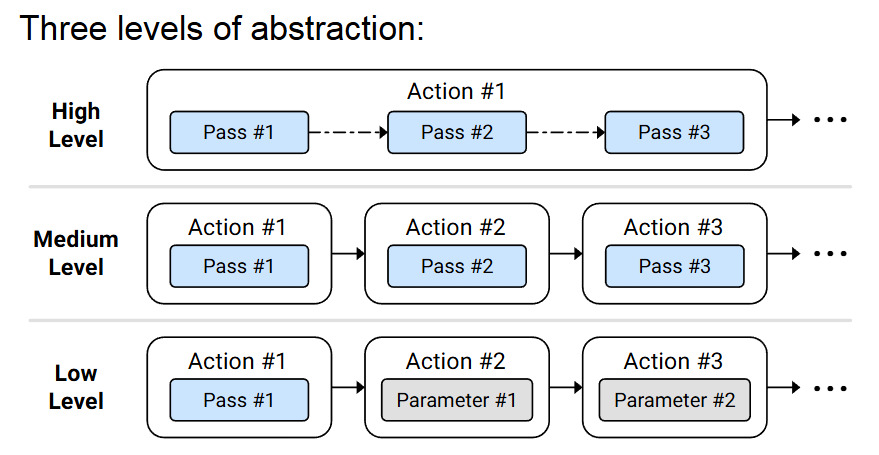
2、Autotuning Loop Transformation
- 目标:优化程序性能,这里是对循环优化来进行操作。
- 背景:传统的编译器依赖于固定的启发式算法(heuristics),这些算法通常是通用性的,无法适应现代复杂硬件(如多核 CPU、GPU)的特定需求,导致生成的代码性能往往不如手动优化的版本。且不同的循环转换在组合起来后的效果难以预测。
- 操作:树形搜索,树根是没有优化的原始循环,每个树枝代表优化转换,而且树枝还能继续生长叠加。最后挑选一个优化组合路径,通过编译指示 pragma 插入代码中。
- 结果:性能提升 5 倍。
- 缺点:容易陷入局部最优,搜索成本高。

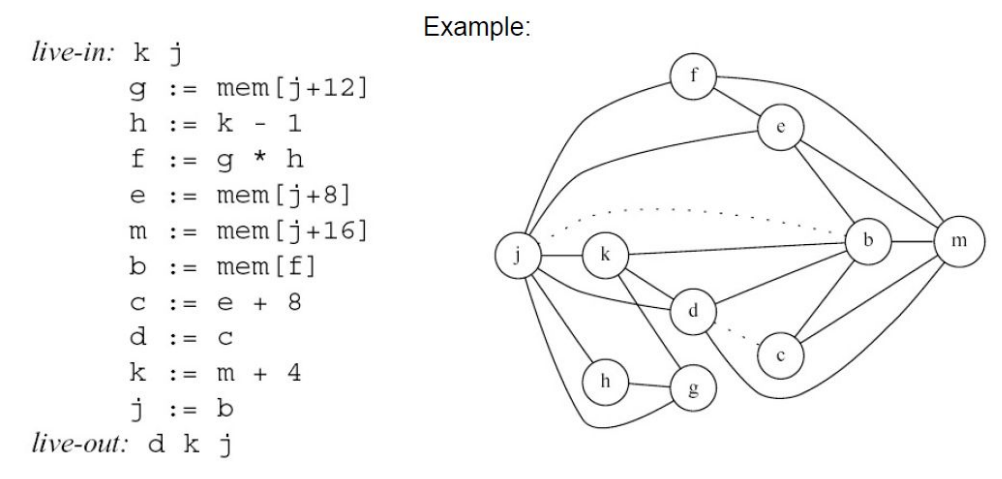
3、Register Allocation
- 目标:优化寄存器分配问题。
- 背景:图着色问题为 NP 难问题,传统解决方案靠贪心算法、启发式算法调优,很难适配大部分场景。
- 操作:采用 LSTM(长短期记忆网络) 模型,输入图的邻接向量(节点之间的连接关系),输出每个节点的颜色。
- 训练集:大量的最优配色案例。
- 结果:接近最优解,比 LLVM 少用 7% 的寄存器。
- 缺点:只擅长小图(节点数量少的)。

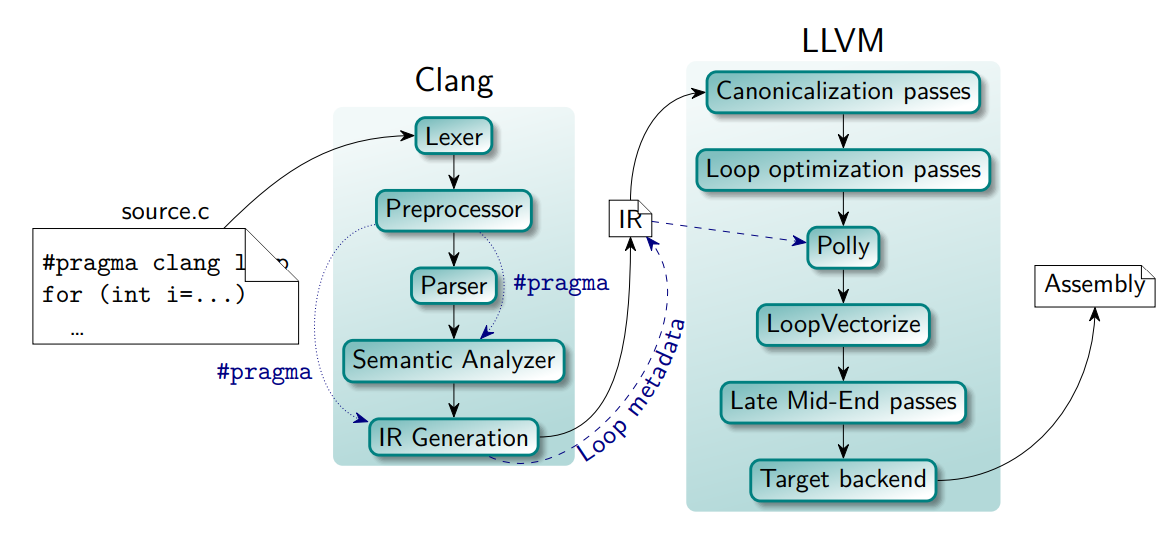
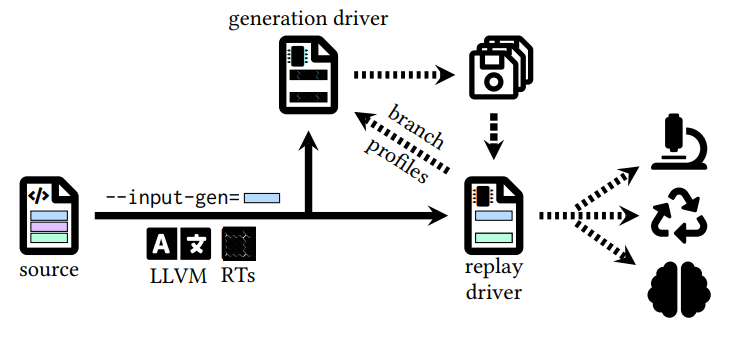
4、input-gen
- 目标:给 IR 自动生成输入数据,用作测试。
- 背景:输入数据往往 “千金难求”,手工写输入要耗费工程师大量时间,随机生成的输入又太 “天真”,测不出复杂场景。
- 操作:输入 LLVM IR,生成对应的输入数据。
- 结果:90% 的生成输入为有效,覆盖率提升 45%。
- 缺点:无法应对过于复杂的场景、缺乏语义级生成逻辑。

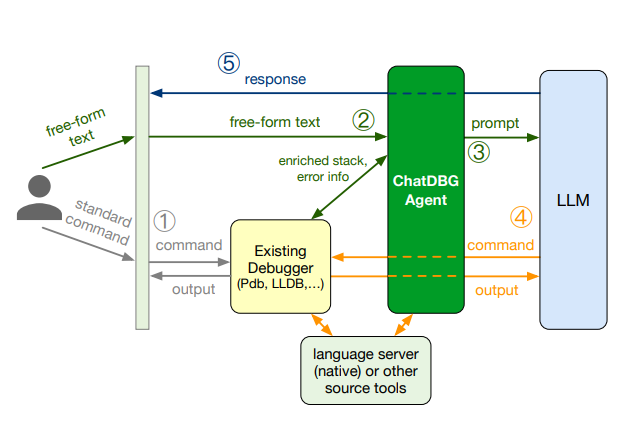
5、ChatDBG
- 目标:AI 辅助调试,利用 AI 来排查问题。
- 背景:调试命令太多、程序状态太多不好排查,调试器结果只能知道结果不对,但不知道原因。
- 操作:集成 LLM 辅助调试。
- 结果:C/C++ 能成功诊断并提供修复方案的比例高达 91%,其中 36% 能直击根因,55% 能解决直接导致崩溃的问题。
- 缺点:AI 可能出现盲目排查情况。

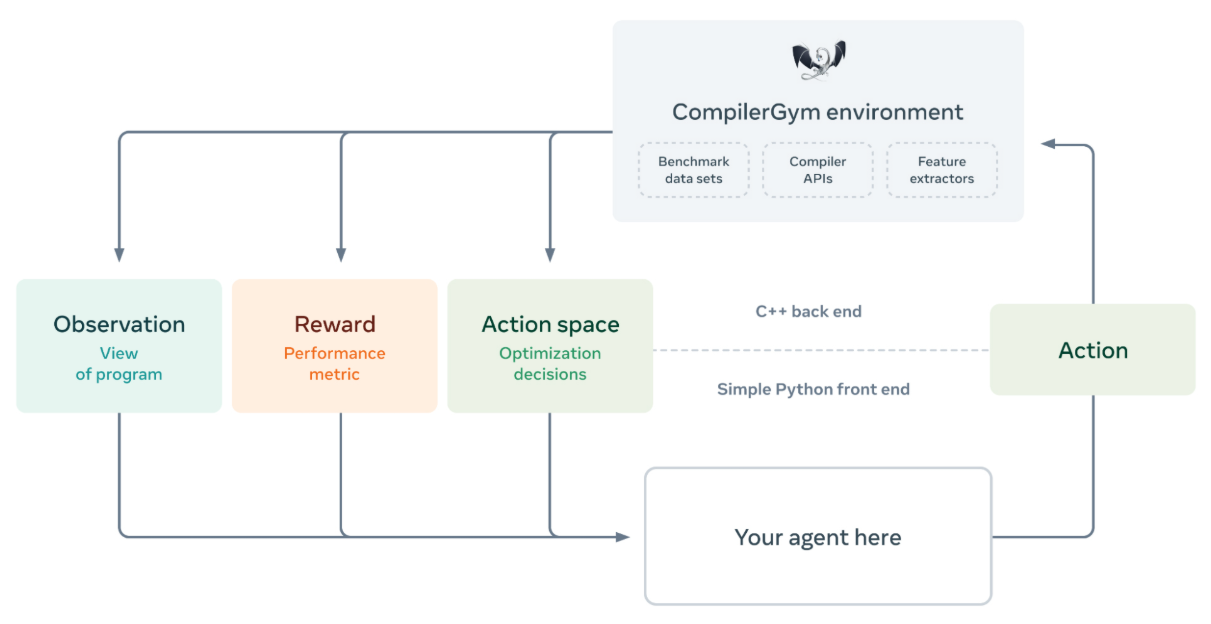
扩展
期间有些优化用到了一个工具 compilergym.ai/,它专为编译器优化任务而设计,CompilerGym 将编译器优化问题打包,并使其看起来像强化学习问题。
参考
- [LLVM-DEV’25] LLVM & ML Workshop
- STATIC NEURAL COMPILER OPTIMIZATION VIA DEEP REINFORCEMENT LEARNING
- 2020 LLVM in HPC Workshop: Autotuning Search Space for Loop Transformations
- 2020 LLVM in HPC Workshop: Deep Learning-based Approx. Graph-Coloring for Register Allocation
- The Sixth Workshop on the LLVM Compiler Infrastructure in HPC
- compilergym.ai/
- Introducing input-gen: Automatically generate runnable inputs for your IR
- ML Guided Compiler Optimizations
- ChatDBG
文章作者 calssion
上次更新 2025-11-08