Flattening ASTs: 优化编译语法树性能
文章目录
读到一篇关于编译器 AST 节点数据结构优化的文章,性能优化了 2.4 倍,本文简单介绍一下。
A Normal AST
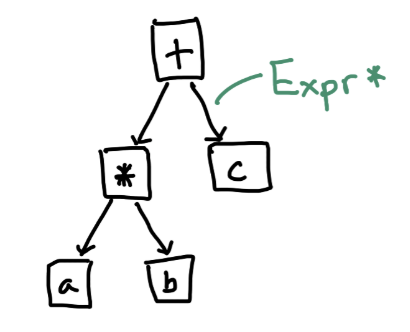
通常的 AST 的节点存储的数据结构,是采用树状的,在堆上申请内存存放节点,然后用指针指向其孩子节点。
Flattening the AST
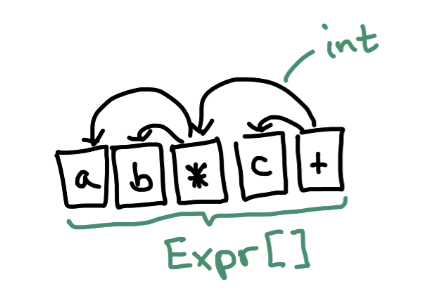
而文中的优化方式,是直接用一个数组来存储节点,不再从堆上申请内存,直接拿索引(数组下标)来指向它的孩子节点。
主要带来了以下几个好处:
- Locality(局部性)。用数组连续存储可以有良好的内存读取局部性,对数据缓存友好。
- Smaller references(更小的指向数据占用)。使用指针的话,一般都是 64 位的;而这里使用索引,用 32 位的变量即可,相当于节省了 50% 的空间占用。
- Cheap allocation(分配内存更高效节省)。无需再调用 malloc,只需要提前设置好足够的空间即可。
- Cheap deallocation(释放内存更高效)。不需要一个个去释放节点了,可以直接一次性释放全部。
- Easier lifetimes(操作简单)。内存管理简单。
- Convenient deduplication(方便数据去重)。可以比较方便地加上哈希索引到重复数据来复用或者去重。
最终在 AST 的处理时带来了 2.4 倍的性能优势。
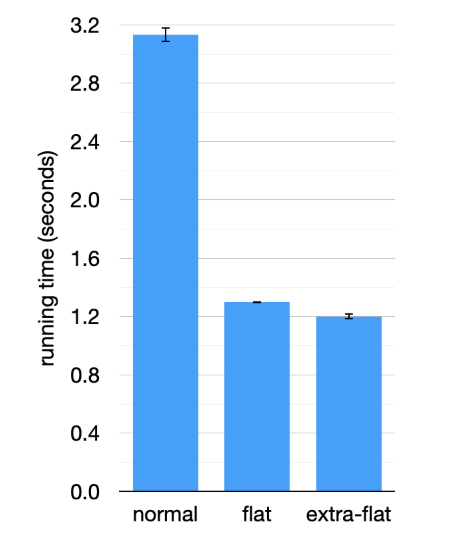
像这种数据结构上的算法优化思路,也可以迁移到不同的地方运用。
参考
文章作者 calssion
上次更新 2025-02-07