egg: 智能编译优化工具
文章目录
看到个工具 egg 可以用来构建程序优化器、合成器、验证器等等,它可以探索所有的等价表达式,再智能地选出最优解。本文简单介绍一下。
1、e-graphs
egg(e-graphs good) 使用了 e-graphs 来重构编译技术,所以需要先从 e-graphs 介绍起,但需要和传统的 e-graphs 做对比,这里会先由传统的 e-graphs 讲起。
e-graphs(Equality graphs) 是一种存储语言等价关系(congruence relations、同余关系) 的数据结构。e-graphs 扩展了 union-find(并查集),简洁有效地表示表达式(expression) 的等价类 e-class。可以把 e-graphs 想象成 “等价类的集合”。
同时维持着一个关键的属性(invariant、同余属性):等价关系(equivalence relation) 在同余(congruence) 下是闭合的。(即两个节点 e-nodes 是等价的,如果他们的并查集的根相同 find(U, i) = find(U, j) 。
注:在图论中,graph property(或 graph invariant) 是图的性质,只取决于其抽象结构,而不取决于图的表示形式。)
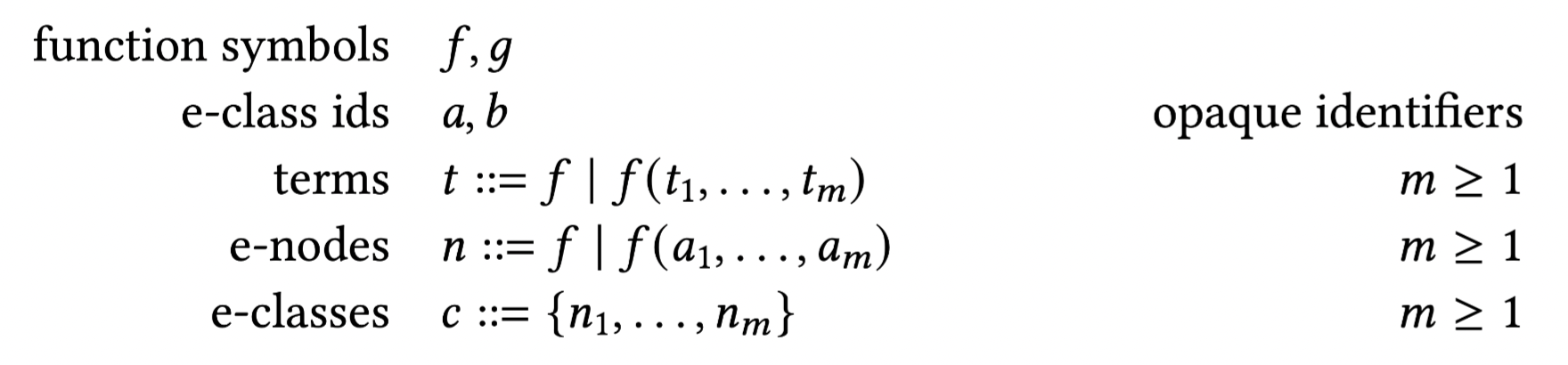
e-graph 由一系列的等价类 e-class 组成,而 e-class 是一系列表示等价项的 e-nodes 组成。e-graph 的“重写能力”本质是 规则驱动+自动推导 的协同系统,所有重写规则本质是 人工预定义的数学恒等式,匹配之后,同余闭包将局部重写推广到全局。
e-graphs 用于 automated theorem proving(ATP、自动化定理证明) 领域,ATP 是借助计算机程序,证明一些推测(conjecture) 是一系列公理(axioms) 的逻辑结果。 如下图著名的三段论推理。由于逻辑推理不需要与其句子实际含义相关,所以计算机程序可以胜任这样的推断任务。

2、equality saturation
我们写代码时,经常会用到 “等价变换”—— 比如把x*2换成x<<1(位运算比乘法更快),把(a+b)+c换成a+(b+c)(加法结合律)。但传统的代码优化有个大难题:先 apply 哪个变换? 比如先做了x*2→x<<1,可能就错过了(x*2)/2→x的简化机会 —— 这就是编译器领域的 “阶段排序问题(Phase Ordering Problem)”。
Equality Saturation(等价渗透) 是一种使用 e-graphs 来构建编译优化、程序生成的技术。不纠结顺序,把所有可能的等价变换都 “记下来”,直到没有新变化为止。给定一个程序 p,equality saturation 会构建一个巨大的 p 的等价程序集合 e-graphs E,通过不断地模式匹配重写到达不动点(fixed point),重写过程会不断地往 e-graph 中添加信息,最终提取程序(extraction) 分析 E 并从中选取最佳的一种(按成本函数如计算量最小的,来提取最优),整个过程不用人工判断先换哪个规则。
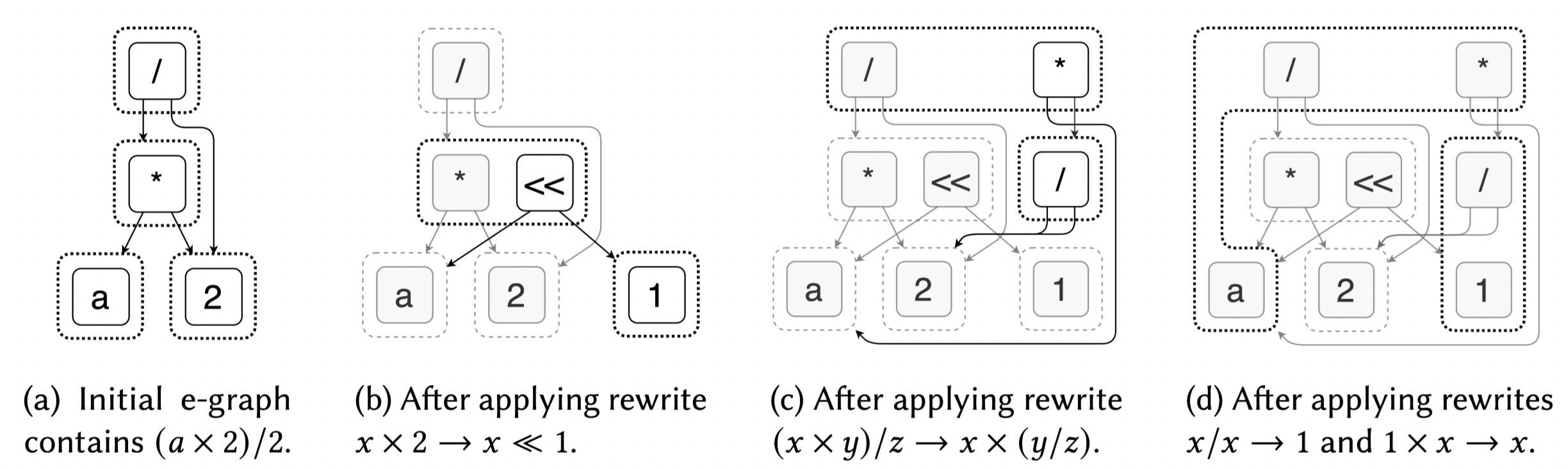
2.1、Equality Saturation Workload
ATPs 会不断地查询和修改 e-graphs,并且还需要有回溯(backtracking) 的能力来撤销修改。
传统方式存在两个问题:
- 慢且成本高。e-graph 增长时,维护等价关系成本很高。一部分是因为传统 ATP 设置下的 e-graphs 无法胜任不同的 equality saturation workload。每次添加新等价关系,都要立刻维护 “同余不变量”,代码量大了会变得非常卡。
- 比较粗糙。很多应用依赖于特定领域分析(domain-specific analyses、专用语言如 json 的解析),但集成它们需要有临时的扩展能力(ad hoc extensions)。只能处理 “纯语法” 的等价变换(比如
x*2→x<<1),没法理解代码的 “语义”—— 比如判断x是不是 0,没法做x/x→1(因为 x=0 时不成立)。
3、e-graphs good(egg)
egg(e-graphs good) 是实现了重建技术(rebuilding) 和 e-class analysis 的开源库,egg 让 e-graphs 从实验室走向了应用。
3.1、rebuilding
“慢”,本质是 “频繁维护不变量”。比如每次合并两个等价类,都要顺着依赖关系往上更新所有父节点,像多米诺骨牌一样停不下来。
egg提出了一个反直觉的思路:不每次都维护,攒到 “合适的时机” 再统一处理—— 这就是 “rebuilding(重建)” 技术。rebuilding 将 e-graph 从“实时修复”升级为“批量处理”,解决性能瓶颈。
rebuilding 在没有牺牲完备性(soundness) 的情况下,延迟了 e-graph 同余属性维护到 equality saturation 的阶段末尾,而不需要每次操作后都处理,累积多个合并操作后批量处理,减少冗余操作。维护待修复的 e-class 工作列表,合并重复项(如 merge(a,b)和 merge(a,c)合并为 merge(a, {b,c}))。
可以理解为传统方式是每装一个零件就要进行全车检查(每次合并都触发全图扫描);而 egg 就相当于是流水线批量检修,合并相同的检修需求、从底层零件盒分层逐层往上检查。
3.2、e-class analysis
纯语法重写无法支持 领域特定优化(如常量折叠、变量分析)。传统方案需手动扩展 e-graph,增加实现复杂度。
e-class analysis 为每个 e-class 附加 半格(semilattice)域 的数据(如常量值、自由变量集合)。(下面介绍定义,熟悉可跳过)
可以理解为 egg 给零件盒贴 「智能标签」(标签里存着代码的语义信息 —— 比如 “这个节点里的表达式都是常数 3”)。因为传统方式是纯零件匹配(语法重写),无法处理「齿轮组A」能否和「轴承组B」组合;而 egg 在每个零件盒绑定分析数据标签,合并时也会合并标签,就可以处理语义信息了。
3.2.1、序论
在 Order Theory(序论,使用二元关系(binary relations、如小于) 来研究序的概念) 中,具有自反性(reflexive)、反对称性(antisymmetric)、传递性(transitive) 的是偏序集(partially ordered sets):
- 自反性:a ≤ a
- 反对称性:如果 a ≤ b 以及 b ≤ a,那么 a = b
- 传递性:如果 a ≤ b 以及 b ≤ c,那么 a ≤ c
下确界(infimum、meet) 在偏序集 P 的子集 S 中,是小于或等于集合 S 中每一个元素的最大元素,也称为最大下界(a greatest lower bound、GLB)。如 inf{2, 3, 4} = 2。
上确界(supremum、join) 在偏序集 P 的子集 S 中,是大于或等于集合 S 中每一个元素的最小元素,也成为最小上界(a least upper bound、LUB)。如 sup{1, 2, 3} = 3。
格(lattice) 是由特殊的偏序集组成,其中每一对元素都有一个唯一的上确界和一个唯一的下确界。比如,一个集合的超集(power set、该集合所有子集的集合) 的包含关系,上确界为并集,而下确界为交集。另一个例子是按可整除性部分排序的自然数,上确界是最小公倍数,下确界是最大公约数。
半格(Semilattice) 偏序集中每一对元素都有上确界或者下确界的集合。
3.2.2、定义
e-class analysis 使用半格域提取的 facts(事实、公理) 来标注每一个 e-class。随着 e-graph 增长,facts 会被引入、传递和 join 连接来满足 e-class analysis 的属性,它将 e-graph 中表示的项与 facts 关联到一起。
3.3、结论
egg的价值不只是 “快”,更是 “降低了 Equality Saturation 的使用门槛”,目前已经可以看到有很多的应用了 awesome-egraphs。
参考
文章作者 calssion
上次更新 2025-10-07